
최근(2023.10)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Google DeepMind, Standford Univ]
LLM의 reasoning process를 자동적으로 guide하는 analogical prompting를 제시.
labeling 작업이 필요하지 않아 generality & convenience, 특정 problem에 적용 가능하여 adaptability.
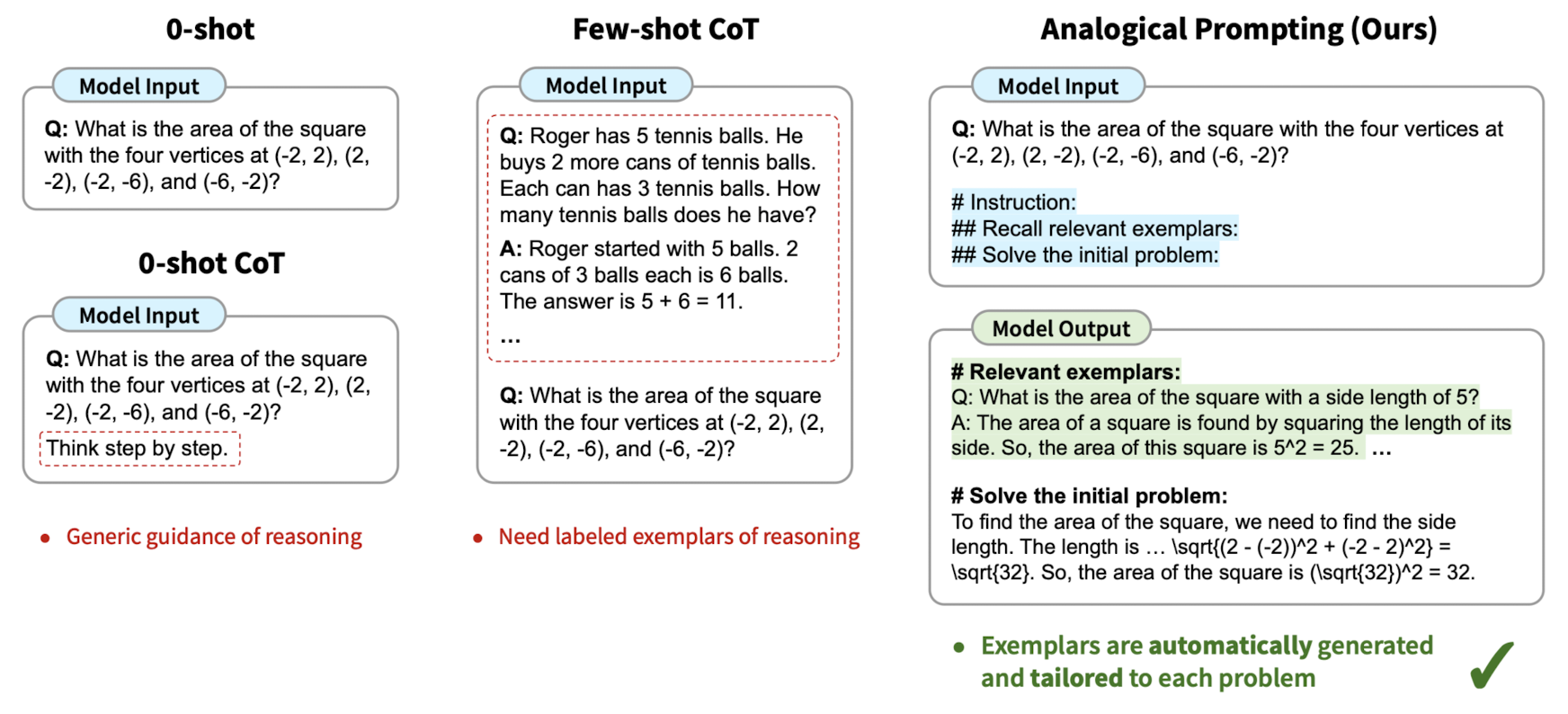
배경
언어 모델을 학습할 때 CoT(Chain of Thought) 방식을 채택하는 것이 모델 성능 향상에 큰 도움이 된다는 것은 이미 잘 알려져 있습니다.
어떤 문제를 해결할 때 단순히 정답만을 반환하는 것이 아니라, 정답이 도출되기까지의 과정을 함께 반환하도록 하는 방식을 CoT라고 부릅니다.
그러나 이는 데이터셋을 구축하기 위해 단순한 정답 하나만을 annotation하면 되던 과거와 달리 과정 전체를 사람이 제작/평가해야 하는 상황으로 이어져 데이터셋 제작에 많은 시간과 비용이 들어가게 되었습니다.
즉, 추론과 관련있는 guidance/examplar를 제공해야 한다는 것과 이를 직접(manual) labeling 해야 한다는 점이 CoT의 문제점으로 제기되고 있는 상황입니다.
본 논문의 저자는 사람이 새로운 문제를 해결하기 위해 관련된 과거의 경험을 이용한다는 심리학적 개념에 기인하여,
LLM이 지금 해결하고자 하는 문제와 관련된 다른 문제 해결 과정을 참고하도록 하는 방식인 analogical prompting을 제시합니다.
관련 연구
- A Language model estimates probabilities over text
- LLMs with billions of parameters demonstrate in-context learning and few-show learning abilities
- Recitation-augmented generation
- Recalling problem-solving and reasoning process
- Chain of Thought
- 0-Shot CoT / Few-Shot CoT / retrieval-based CoT
- self-consistency / least-to-most
Approach
Self-generated Exemplars
이 approach는 LLM이 training 기간 동안 문제 해결을 위한 방대한 양의 지식은 이미 습득했다는 가정에서 출발합니다.
즉, 새로운 문제를 해결하는데 참고할 만한 능력은 이미 습득했으므로 이를 참조하도록 하면 더 좋은 결과를 반환하도록 할 수 있다는 뜻입니다.


위 예시에서는 문제와 관련되었으면서도 구분이 가능한(distinct) 문제 세 개와 그 해결 과정을 제시하라고 합니다.
다음은 이 방식에서 사용된 세 개의 핵심 테크닉입니다.
- Generating relevant and diverse exemplars is import: 이를 위해서 'distinct'라는 단어를 일부러 삽입해둔 것을 알 수 있습니다.
- Single-pass vs. independent exemplar generation: 세 개의 예시를 한꺼번에 호출하는 single-pass 방식과, 각 예시를 따로 호출하고 나중에 합치는 방식 중에서 전자가 더 좋은 결과로 이어졌다는 것을 실험적으로 확인했습니다.
- The number of exemplars to generate (K) : 이 역시 비교 실험을 통해서 태스크에 따라 3개 또는 5개의 예시를 불러오도록 하는 것이 가장 좋은 결과로 이어진다는 것을 밝혔습니다.
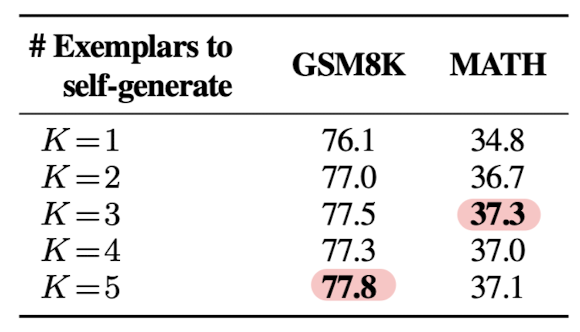
Self-generated Knowledge + Exemplars
exemplars를 생성하는 것이 code generation과 같은 복잡한 태스크에 큰 도움이 되는 것은 사실이지만,
분명히 low-level exemplar를 생성하는 것이기 때문에 일반화에 실패할 가능성이 높습니다.
즉, 특정 코드 생성은 기가 막히게 잘 해낼 수 있지만 다른 reasoning task는 결이 다르기 때문에 잘 수행하지 못할 가능성이 높다는 뜻이죠.
따라서 본 논문에서는 "knowledge"라고 표현하는 high-level notion을 생성하도록 하고 있습니다.


주어진 문제의 핵심 개념을 파악하고 tutorial을 제시하라고 되어 있습니다.
이를 관련 problem & solution 여러 개를 제시하는 것보다 선행하여 low-level exemplar만 reference함으로써 발생할 수 있는 한계를 극복하고자 한 것으로 이해할 수 있습니다.
Experiments & Results
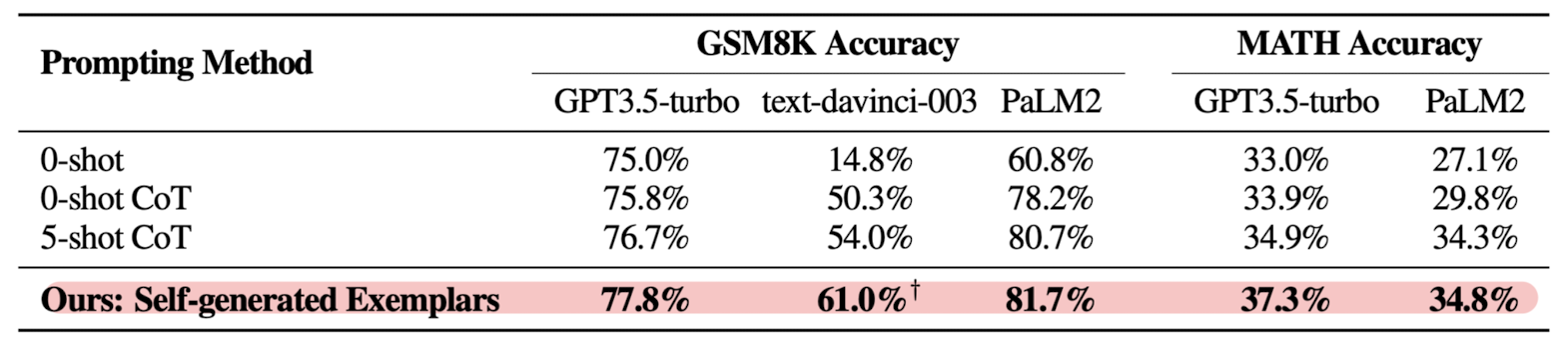
기존의 zero/few-shot CoT와 Self-generated Exemplars 방식의 성능을 비교한 결과입니다.
reasoning 성능을 검증하는 대표적인 벤치마크인 GSM8K, MATH에 대한 accuracy를 비교한 것을 알 수 있습니다.
본 논문의 방식은 데이터셋 구축에 annotation을 포함하지 않음에도 불구하고 기존에 비해 훨씬 좋은 성능을 보임을 알 수 있습니다.
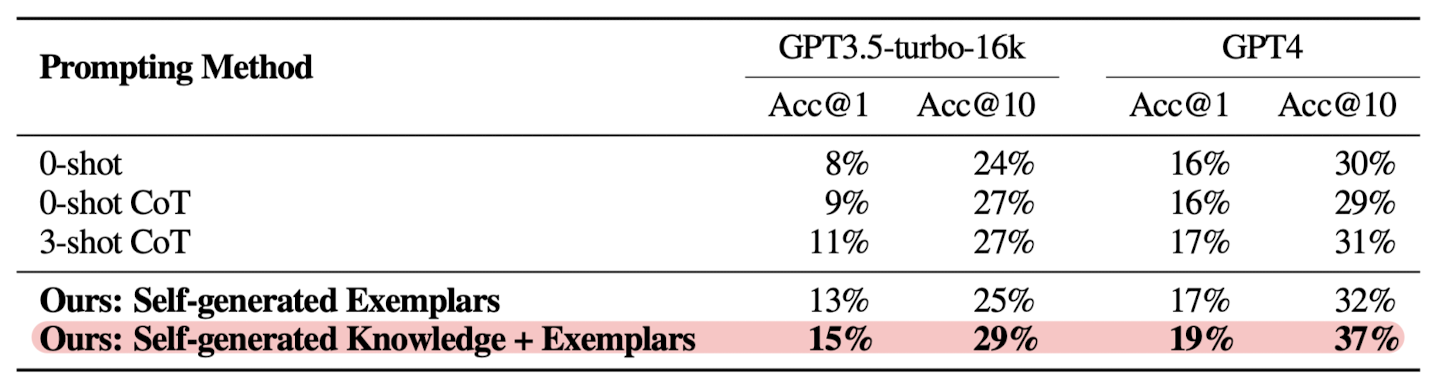
하지만 단순히 Exemplars를 생성하는 것 뿐만 아니라 Knowledge 또한 모델이 생성하게 만듦으로써 모델 성능을 더욱 극대화할 수 있음이 확인 가능합니다.
이때 @k는 k개의 output을 만들어서 그중에 accurate한 output이 있었는지에 대한 비율을 뜻합니다.
따라서 의외로 단 하나의 output만으로 모델 성능을 평가하는 경우 10% 수준의 정확도만을 기록하지 못한다는 것도 주목할만하고, 이것이 본 논문에서 제시하는 방법론에 의해 적잖이 개선될 수 있다는 것이 흥미롭습니다.
개인적 감상
간만에 prompt tuning과 관련된 논문을 읽은 것 같은데 무척이나 재밌었습니다.
사실 모델의 파라미터를 업데이트하지 않고서도 좋은 성능을 이끌어내는데 이것만한 전략이 없기 때문이죠 ㅋㅋㅋ..
또한 거대 언어 모델이 학습 과정에서 이미 대부분의 태스크를 처리할 수 있을 만큼의 능력을 갖추었을 것이라는 전제가 타당하다고 생각했습니다.
그렇기 때문에 in-context learning에 대한 연구도 활발히 이뤄졌던 것이니까요..
다만 저자가 스스로 밝힌 바와 같이 inference 비용이 많이 든다는 명확한 문제점이 존재합니다.
(exemplar를 몇 개씩이나 생성하는게 기본이니..)
개인적으로는 파라미터 업데이트 비용과 inference 비용을 비교하여 어떤 것이 더 경제적일지 파악하는 것이 이를 활용하는 입장에서 중요한 포인트가 아닐까 싶습니다.
한 모델을 지속적으로 사용한다는 관점에서는 오히려 전자가 장기적으로 비용을 줄여줄 수 있을 것 같고..
그렇게 생각해보면 이러한 방식으로 학습된 모델을 사용하는 방법도 떠올려 볼 수 있을 것 같습니다.
그런 경우는 물론 본질적으로 모델의 파라미터 업데이트 없이 성능 개선한다는 목적을 달성하진 못하지만 서비스 관점에서 적절한 균형을 이루게되는 것이 아닐까 싶습니다.
출처 : https://arxiv.org/abs/2310.01714
Large Language Models as Analogical Reasoners
Chain-of-thought (CoT) prompting for language models demonstrates impressive performance across reasoning tasks, but typically needs labeled exemplars of the reasoning process. In this work, we introduce a new prompting approach, Analogical Prompting, desi
arxiv.org
'Paper Review' 카테고리의 다른 글
최근(2023.10)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Google DeepMind, Standford Univ]
LLM의 reasoning process를 자동적으로 guide하는 analogical prompting를 제시.
labeling 작업이 필요하지 않아 generality & convenience, 특정 problem에 적용 가능하여 adaptability.
배경
언어 모델을 학습할 때 CoT(Chain of Thought) 방식을 채택하는 것이 모델 성능 향상에 큰 도움이 된다는 것은 이미 잘 알려져 있습니다.
어떤 문제를 해결할 때 단순히 정답만을 반환하는 것이 아니라, 정답이 도출되기까지의 과정을 함께 반환하도록 하는 방식을 CoT라고 부릅니다.
그러나 이는 데이터셋을 구축하기 위해 단순한 정답 하나만을 annotation하면 되던 과거와 달리 과정 전체를 사람이 제작/평가해야 하는 상황으로 이어져 데이터셋 제작에 많은 시간과 비용이 들어가게 되었습니다.
즉, 추론과 관련있는 guidance/examplar를 제공해야 한다는 것과 이를 직접(manual) labeling 해야 한다는 점이 CoT의 문제점으로 제기되고 있는 상황입니다.
본 논문의 저자는 사람이 새로운 문제를 해결하기 위해 관련된 과거의 경험을 이용한다는 심리학적 개념에 기인하여,
LLM이 지금 해결하고자 하는 문제와 관련된 다른 문제 해결 과정을 참고하도록 하는 방식인 analogical prompting을 제시합니다.
관련 연구
- A Language model estimates probabilities over text
- LLMs with billions of parameters demonstrate in-context learning and few-show learning abilities
- Recitation-augmented generation
- Recalling problem-solving and reasoning process
- Chain of Thought
- 0-Shot CoT / Few-Shot CoT / retrieval-based CoT
- self-consistency / least-to-most
Approach
Self-generated Exemplars
이 approach는 LLM이 training 기간 동안 문제 해결을 위한 방대한 양의 지식은 이미 습득했다는 가정에서 출발합니다.
즉, 새로운 문제를 해결하는데 참고할 만한 능력은 이미 습득했으므로 이를 참조하도록 하면 더 좋은 결과를 반환하도록 할 수 있다는 뜻입니다.
위 예시에서는 문제와 관련되었으면서도 구분이 가능한(distinct) 문제 세 개와 그 해결 과정을 제시하라고 합니다.
다음은 이 방식에서 사용된 세 개의 핵심 테크닉입니다.
- Generating relevant and diverse exemplars is import: 이를 위해서 'distinct'라는 단어를 일부러 삽입해둔 것을 알 수 있습니다.
- Single-pass vs. independent exemplar generation: 세 개의 예시를 한꺼번에 호출하는 single-pass 방식과, 각 예시를 따로 호출하고 나중에 합치는 방식 중에서 전자가 더 좋은 결과로 이어졌다는 것을 실험적으로 확인했습니다.
- The number of exemplars to generate (K) : 이 역시 비교 실험을 통해서 태스크에 따라 3개 또는 5개의 예시를 불러오도록 하는 것이 가장 좋은 결과로 이어진다는 것을 밝혔습니다.
Self-generated Knowledge + Exemplars
exemplars를 생성하는 것이 code generation과 같은 복잡한 태스크에 큰 도움이 되는 것은 사실이지만,
분명히 low-level exemplar를 생성하는 것이기 때문에 일반화에 실패할 가능성이 높습니다.
즉, 특정 코드 생성은 기가 막히게 잘 해낼 수 있지만 다른 reasoning task는 결이 다르기 때문에 잘 수행하지 못할 가능성이 높다는 뜻이죠.
따라서 본 논문에서는 "knowledge"라고 표현하는 high-level notion을 생성하도록 하고 있습니다.
주어진 문제의 핵심 개념을 파악하고 tutorial을 제시하라고 되어 있습니다.
이를 관련 problem & solution 여러 개를 제시하는 것보다 선행하여 low-level exemplar만 reference함으로써 발생할 수 있는 한계를 극복하고자 한 것으로 이해할 수 있습니다.
Experiments & Results
기존의 zero/few-shot CoT와 Self-generated Exemplars 방식의 성능을 비교한 결과입니다.
reasoning 성능을 검증하는 대표적인 벤치마크인 GSM8K, MATH에 대한 accuracy를 비교한 것을 알 수 있습니다.
본 논문의 방식은 데이터셋 구축에 annotation을 포함하지 않음에도 불구하고 기존에 비해 훨씬 좋은 성능을 보임을 알 수 있습니다.
하지만 단순히 Exemplars를 생성하는 것 뿐만 아니라 Knowledge 또한 모델이 생성하게 만듦으로써 모델 성능을 더욱 극대화할 수 있음이 확인 가능합니다.
이때 @k는 k개의 output을 만들어서 그중에 accurate한 output이 있었는지에 대한 비율을 뜻합니다.
따라서 의외로 단 하나의 output만으로 모델 성능을 평가하는 경우 10% 수준의 정확도만을 기록하지 못한다는 것도 주목할만하고, 이것이 본 논문에서 제시하는 방법론에 의해 적잖이 개선될 수 있다는 것이 흥미롭습니다.
개인적 감상
간만에 prompt tuning과 관련된 논문을 읽은 것 같은데 무척이나 재밌었습니다.
사실 모델의 파라미터를 업데이트하지 않고서도 좋은 성능을 이끌어내는데 이것만한 전략이 없기 때문이죠 ㅋㅋㅋ..
또한 거대 언어 모델이 학습 과정에서 이미 대부분의 태스크를 처리할 수 있을 만큼의 능력을 갖추었을 것이라는 전제가 타당하다고 생각했습니다.
그렇기 때문에 in-context learning에 대한 연구도 활발히 이뤄졌던 것이니까요..
다만 저자가 스스로 밝힌 바와 같이 inference 비용이 많이 든다는 명확한 문제점이 존재합니다.
(exemplar를 몇 개씩이나 생성하는게 기본이니..)
개인적으로는 파라미터 업데이트 비용과 inference 비용을 비교하여 어떤 것이 더 경제적일지 파악하는 것이 이를 활용하는 입장에서 중요한 포인트가 아닐까 싶습니다.
한 모델을 지속적으로 사용한다는 관점에서는 오히려 전자가 장기적으로 비용을 줄여줄 수 있을 것 같고..
그렇게 생각해보면 이러한 방식으로 학습된 모델을 사용하는 방법도 떠올려 볼 수 있을 것 같습니다.
그런 경우는 물론 본질적으로 모델의 파라미터 업데이트 없이 성능 개선한다는 목적을 달성하진 못하지만 서비스 관점에서 적절한 균형을 이루게되는 것이 아닐까 싶습니다.
출처 : https://arxiv.org/abs/2310.01714
Large Language Models as Analogical Reasoners
Chain-of-thought (CoT) prompting for language models demonstrates impressive performance across reasoning tasks, but typically needs labeled exemplars of the reasoning process. In this work, we introduce a new prompting approach, Analogical Prompting, desi
arxiv.org