
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다. (Language & Knowledge Lab의 Retreival 관련)
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[KAIST, Naver AI, University of Washington, MIT]
- GPT-4의 평가 수준에 준하는 완전한 오픈소스 LLM, Prometheus
- customized score rubric 기반으로 long-form text를 평가할 수 있는 13B 사이즈의 평가자 LLM, Prometheus
- 1K score rubrics, 20K instructions, 100K responses로 구성된 데이터셋, Feedback Collection
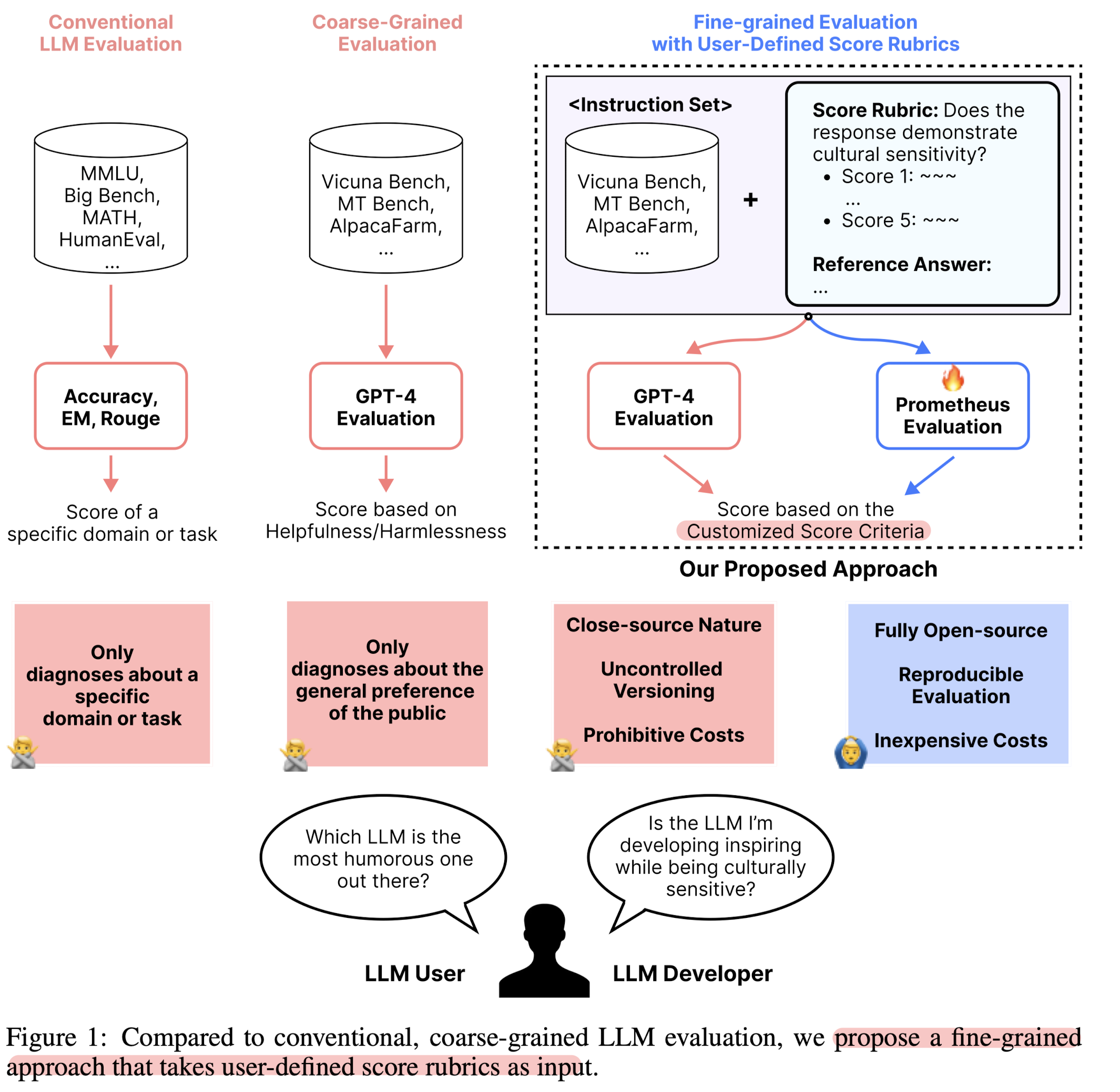
- 배경
- 최근 LLM을 evaluator로 사용하고자 하는 시도가 많으나, 다음과 같은 한계점들이 존재
- 1) Closed-source Nature: 투명성이 부족하다는 문제점
- 2) Uncontrolled Versioning: 재현 가능성에 치명적인 영향
- 3) Prohibitive Costs: 비용적인 문제로 인해 접근성이 낮음
- Related Works
- Reference-based text evaluation
- BLEU, ROUGE, BERTScore, BARTScore 등
- evaluation을 온전히 신뢰하기 어렵다는 한계
- LLM-based text evaluation
- GPT-4 또는 fine-tuned critique LLM을 single diemnsion of preference에 대한 평가자로 활용하기 시작
- 수천개의 unique preference criteria에 반응 가능한 evaluator를 공개
- rubric과 reference answer와 같은 reference materials의 중요성을 확인
- Reference-based text evaluation
- The Feedback Collection Dataset
- Step 1) Creation of the Seed Rubrics: 50개의 초기 seed rubric으로 시작
- Step 2) Augmenting the Seed Rubrics with GPT-4: GPT-4를 통해 1K new score rubrics으로 확장
- Step 3) Crafting Novel Instructions related to the Score Rubrics: 현실적인 instruction으로 augmentation
- Step 4) Crafting Training Instances: reference answers, feedback, score와 같은 나머지 요소에 대한 augmentation

- Fine-Tuning an Evaluator LM
- LLaMA-2-Chat (7B & 13B)에 대해 fine-tuning
- feedback과 score 사이에 [RESULT] 와 같은 토큰을 넣어줘서 추론 시 degneration을 방지
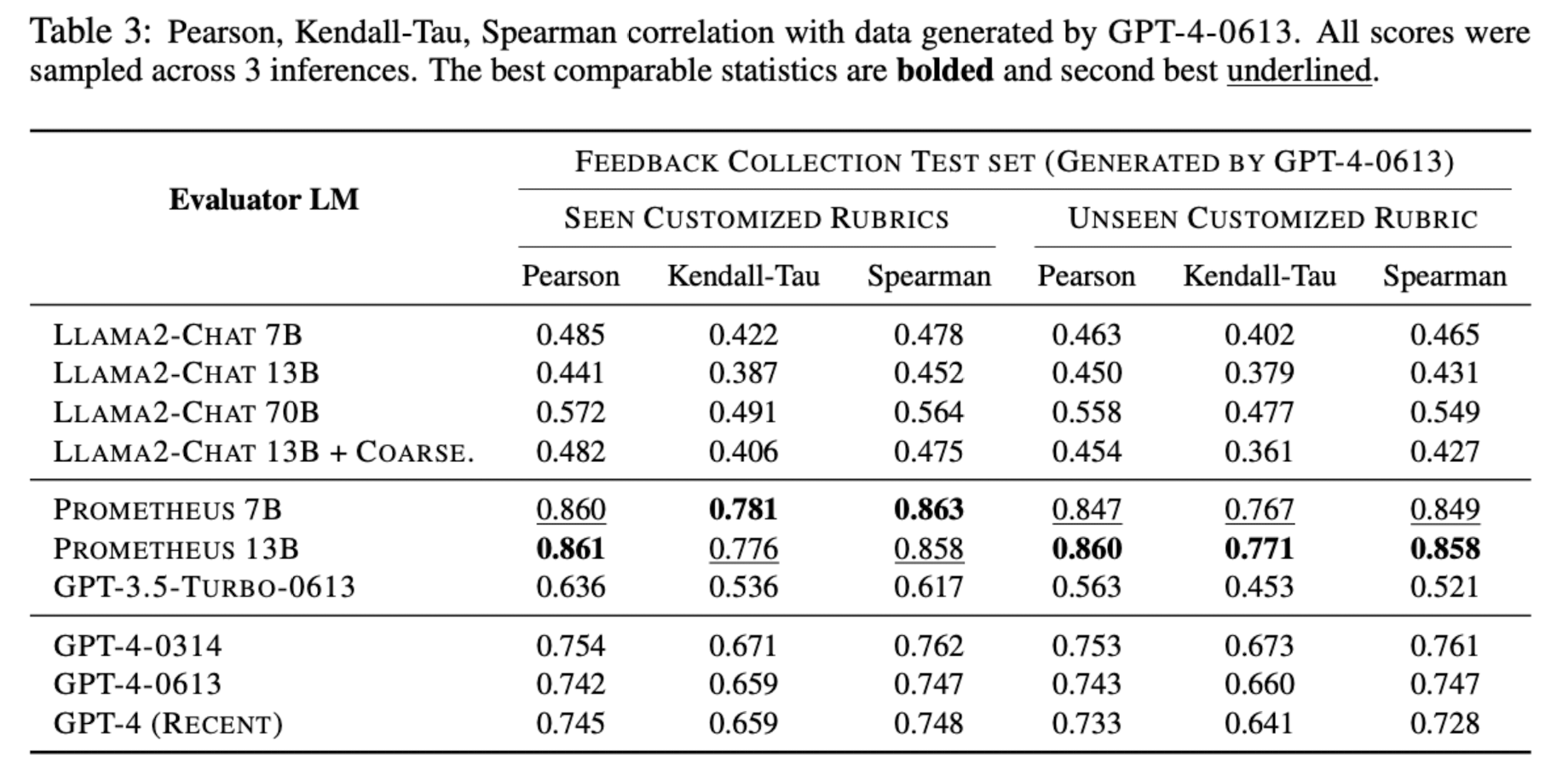
- Benchmarks
- Feedback Bench, Vicuna Bench, MT Bench, Flask Eval
- Baselines
- LLaMA2-Chat-{7, 13, 70}B, LLaMA-2Chat-13B + Coarse, GPT-3.5-Turbo-0613, GPT-4-{0314, 0613, Recent}, StanfordNLP Reward Model, ALMOST Reward Model
출처 : https://arxiv.org/abs/2310.0849
Prometheus: Inducing Fine-grained Evaluation Capability in Language Models
Recently, using a powerful proprietary Large Language Model (LLM) (e.g., GPT-4) as an evaluator for long-form responses has become the de facto standard. However, for practitioners with large-scale evaluation tasks and custom criteria in consideration (e.g
arxiv.org
'Paper Review' 카테고리의 다른 글
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다. (Language & Knowledge Lab의 Retreival 관련)
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[KAIST, Naver AI, University of Washington, MIT]
- GPT-4의 평가 수준에 준하는 완전한 오픈소스 LLM, Prometheus
- customized score rubric 기반으로 long-form text를 평가할 수 있는 13B 사이즈의 평가자 LLM, Prometheus
- 1K score rubrics, 20K instructions, 100K responses로 구성된 데이터셋, Feedback Collection
- 배경
- 최근 LLM을 evaluator로 사용하고자 하는 시도가 많으나, 다음과 같은 한계점들이 존재
- 1) Closed-source Nature: 투명성이 부족하다는 문제점
- 2) Uncontrolled Versioning: 재현 가능성에 치명적인 영향
- 3) Prohibitive Costs: 비용적인 문제로 인해 접근성이 낮음
- Related Works
- Reference-based text evaluation
- BLEU, ROUGE, BERTScore, BARTScore 등
- evaluation을 온전히 신뢰하기 어렵다는 한계
- LLM-based text evaluation
- GPT-4 또는 fine-tuned critique LLM을 single diemnsion of preference에 대한 평가자로 활용하기 시작
- 수천개의 unique preference criteria에 반응 가능한 evaluator를 공개
- rubric과 reference answer와 같은 reference materials의 중요성을 확인
- Reference-based text evaluation
- The Feedback Collection Dataset
- Step 1) Creation of the Seed Rubrics: 50개의 초기 seed rubric으로 시작
- Step 2) Augmenting the Seed Rubrics with GPT-4: GPT-4를 통해 1K new score rubrics으로 확장
- Step 3) Crafting Novel Instructions related to the Score Rubrics: 현실적인 instruction으로 augmentation
- Step 4) Crafting Training Instances: reference answers, feedback, score와 같은 나머지 요소에 대한 augmentation
- Fine-Tuning an Evaluator LM
- LLaMA-2-Chat (7B & 13B)에 대해 fine-tuning
- feedback과 score 사이에 [RESULT] 와 같은 토큰을 넣어줘서 추론 시 degneration을 방지
- Benchmarks
- Feedback Bench, Vicuna Bench, MT Bench, Flask Eval
- Baselines
- LLaMA2-Chat-{7, 13, 70}B, LLaMA-2Chat-13B + Coarse, GPT-3.5-Turbo-0613, GPT-4-{0314, 0613, Recent}, StanfordNLP Reward Model, ALMOST Reward Model
출처 : https://arxiv.org/abs/2310.0849
Prometheus: Inducing Fine-grained Evaluation Capability in Language Models
Recently, using a powerful proprietary Large Language Model (LLM) (e.g., GPT-4) as an evaluator for long-form responses has become the de facto standard. However, for practitioners with large-scale evaluation tasks and custom criteria in consideration (e.g
arxiv.org