관심있는 NLP 논문을 읽어보고 간단히 정리했습니다. (Language & Knowledge Lab의 Retreival 관련)
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Minjoon Seo]
- semi-parametric video grounded text generation model, SeViT
- video를 외부 data store 취급하여 non-parametric retriever로 접근
- longer video & causal video understanding에서 두각
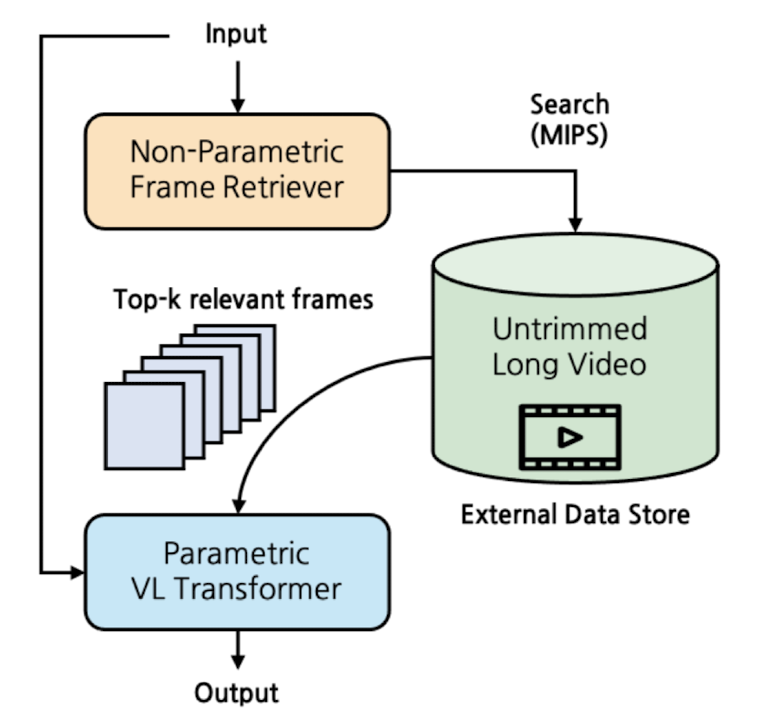
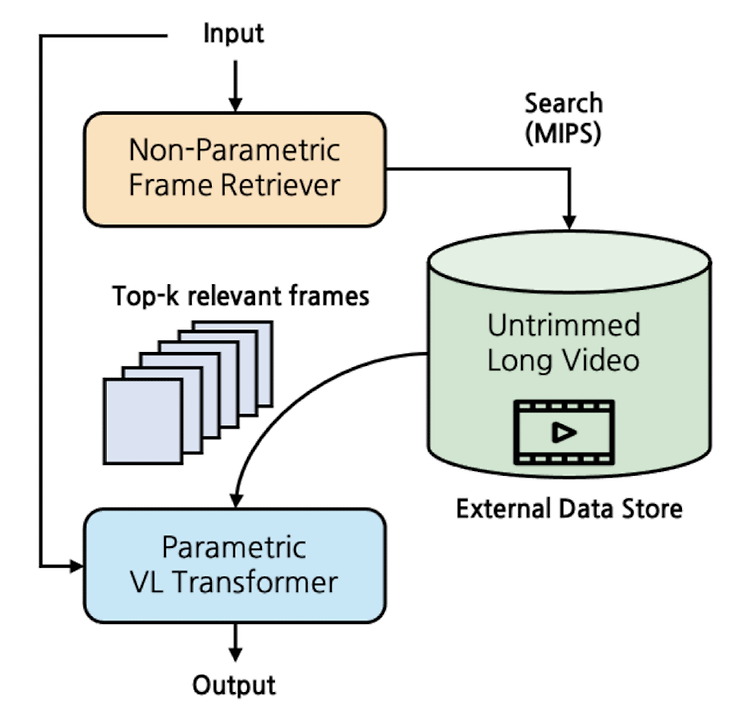
- 배경
- 기존 연구들은 naive frame sampling에 기반하여 sparse video representation의 한계를 지니고 있었음
- Realted Works
- Video-Language Models: leveraging pre-trained 2D/3D vision encoder, end-to-end training
- Semi-Parametric Language Models: RAG framework를 video-language domain에 적용
- Informative Frame Selection
- Contributions
- semi-parametric architecture를 video-language domain에 적용, video를 외부 데이터 store로 활용
- RAG 기반의 SeViT가 long video & causal video understanding에서 강세를 보임
- SeViT가 iVQA, Next-QA, ActivitynetQA에서 SoTA 달성
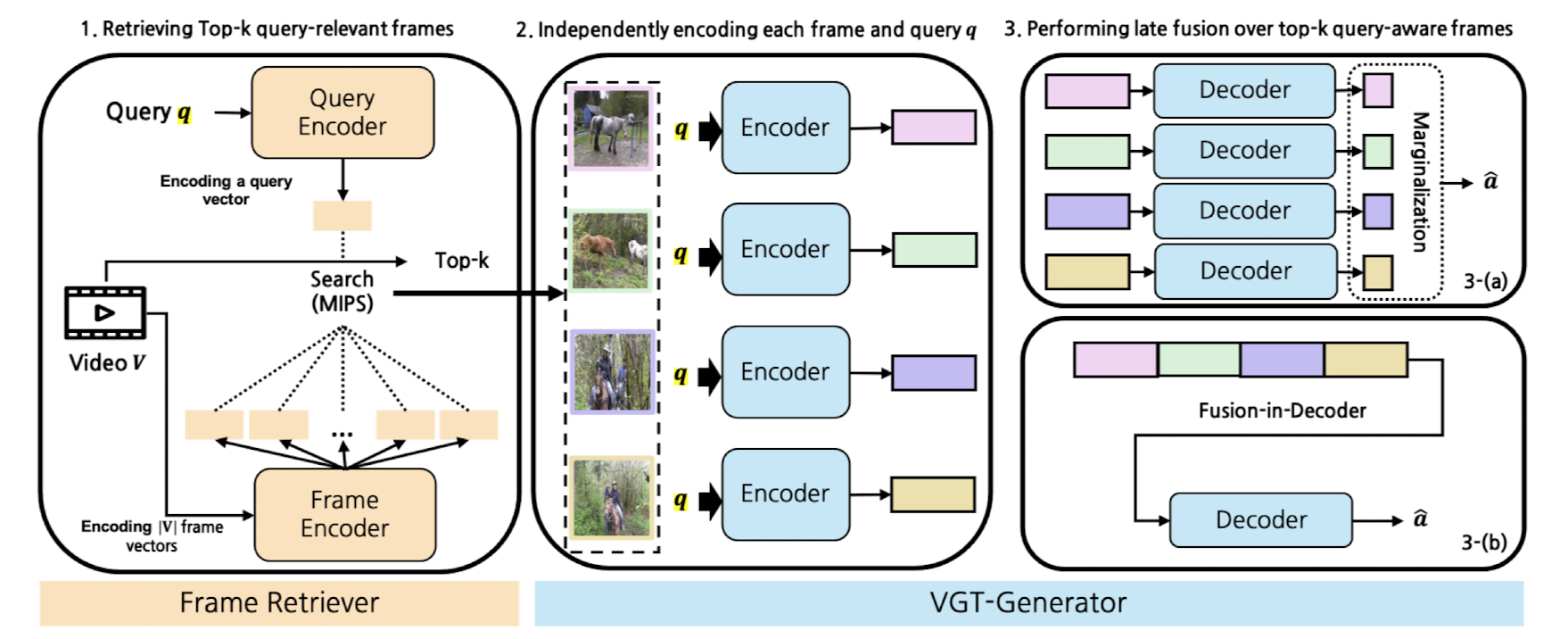
- SeViT
- Frame Retriever: query가 주어졌을 때, relevant frames를 선택
- Video-Grounded Text Generator: Marginalization (MAR), Fusion-in-Decoder (FiD)
- Training: Query-side Fine-Tuning, Retriever Warm-up for FiD, Top-k Annealing
- Retriever: pre-trained CLIP-base/16, VGT-generator: pre-trained OFA-Base
- Benchmarks
- Video QA: TGIF-QA, MSVD-QA, MSRVTT-QA, iVQA, Next-QA, Activitynet-QA
- Video Captioning: MSVD-Caption, MSRVTT-Caption
출처 : https://arxiv.org/abs/2301.11507
Semi-Parametric Video-Grounded Text Generation
Efficient video-language modeling should consider the computational cost because of a large, sometimes intractable, number of video frames. Parametric approaches such as the attention mechanism may not be ideal since its computational cost quadratically in
arxiv.org
'Paper Review' 카테고리의 다른 글
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다. (Language & Knowledge Lab의 Retreival 관련)
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Minjoon Seo]
- semi-parametric video grounded text generation model, SeViT
- video를 외부 data store 취급하여 non-parametric retriever로 접근
- longer video & causal video understanding에서 두각
- 배경
- 기존 연구들은 naive frame sampling에 기반하여 sparse video representation의 한계를 지니고 있었음
- Realted Works
- Video-Language Models: leveraging pre-trained 2D/3D vision encoder, end-to-end training
- Semi-Parametric Language Models: RAG framework를 video-language domain에 적용
- Informative Frame Selection
- Contributions
- semi-parametric architecture를 video-language domain에 적용, video를 외부 데이터 store로 활용
- RAG 기반의 SeViT가 long video & causal video understanding에서 강세를 보임
- SeViT가 iVQA, Next-QA, ActivitynetQA에서 SoTA 달성
- SeViT
- Frame Retriever: query가 주어졌을 때, relevant frames를 선택
- Video-Grounded Text Generator: Marginalization (MAR), Fusion-in-Decoder (FiD)
- Training: Query-side Fine-Tuning, Retriever Warm-up for FiD, Top-k Annealing
- Retriever: pre-trained CLIP-base/16, VGT-generator: pre-trained OFA-Base
- Benchmarks
- Video QA: TGIF-QA, MSVD-QA, MSRVTT-QA, iVQA, Next-QA, Activitynet-QA
- Video Captioning: MSVD-Caption, MSRVTT-Caption
출처 : https://arxiv.org/abs/2301.11507
Semi-Parametric Video-Grounded Text Generation
Efficient video-language modeling should consider the computational cost because of a large, sometimes intractable, number of video frames. Parametric approaches such as the attention mechanism may not be ideal since its computational cost quadratically in
arxiv.org