
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다. (Language & Knowledge Lab의 Retreival 관련)
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[KAIST]
- 각 instruciton에 대해 coarse-level scoring을 skill set-level scoring로 분해
- human & mode based 평가에 대한 fine-grained evaluation protocol, FLASK
- fine-graininess of evaluation은 holistic view를 획득하는데 중요
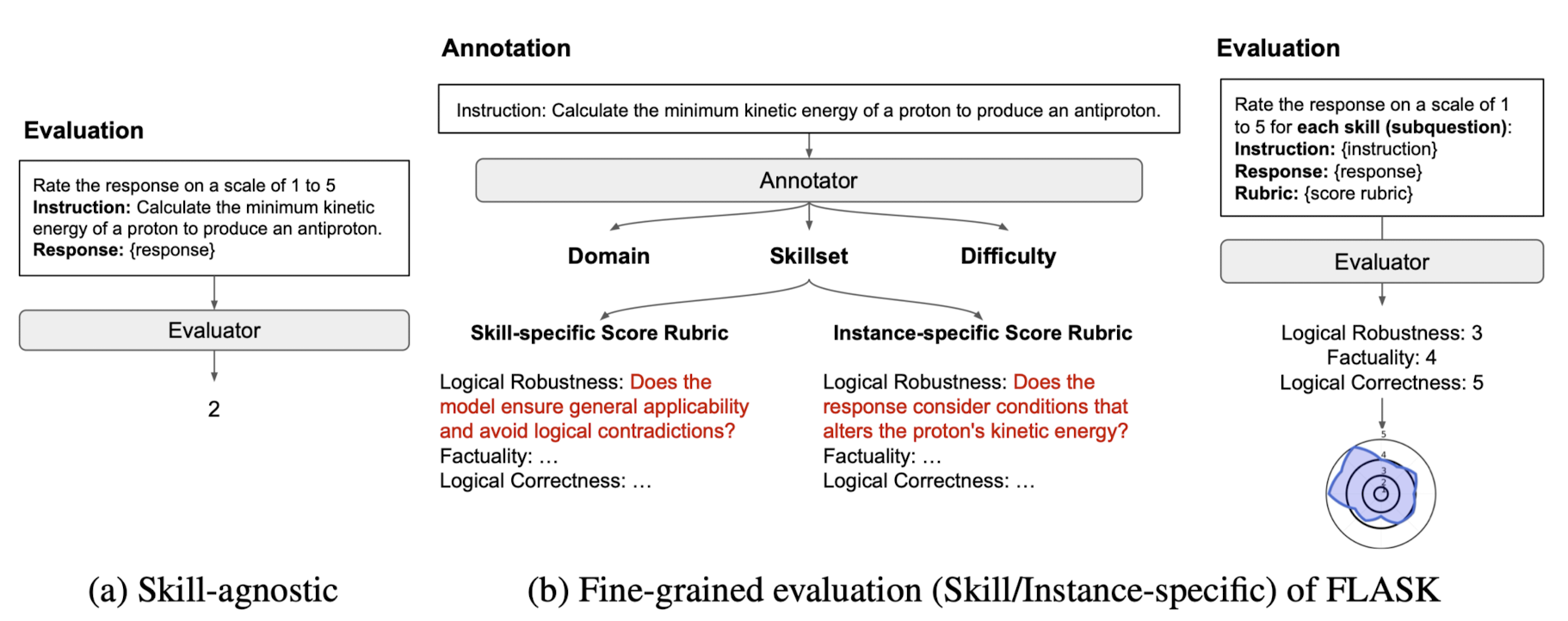
- 배경
- 기존 LLM 평가 방식은 single metric이라서 LLM의 능력을 평가하기에 불충분
- 또한 surface form에 대해 sensitive하기 때문에 task-wise 한 평가 방식이었음
- Contributions
- 현재 오픈 소스 LLM들은 Logical Thinking과 Background Knowledge에서 proprietary LLM에 비해 현저히 열등한 성능을 보여줌
- Logical Correctness와 Logical Efficiency는 다른 스킬들에 비해 더 큰 모델 사이즈를 필요로 하는 경향이 짙음
- SoTA인 proprietary LLM들 역시 FLASK-Hard에 대해서는 다른 스킬 대비 50%의 성능 하락을 보임
- Related Works
- Holistic Evaluation of LLMs: accuracy, ROUGE, instance-wise fine-grained multi-metric setting
- Alignment of LLMs: instruction tuning, RLHF
- FLASK
- Skill Set Categorization: 총 12개의 skills
- Logical Thinking, Background Knowledge, Problem Handling, User Alignment
- Evaluation Data Construction
- 122개의 데이터셋으로부터 1,740개의 instance를 생성
- essential skills to follow the instruction, target domains, the difficulty level of the instructions를 포함하는 metadata에 대해 annotate
- Evaluation Process
- 각 instance에 대한 annotated metadata를 활용하여 target model의 fine-grained manner의 response를 분석
- { evaluation instruction, reference answer, response of target model, pre-defined score rubric for each selected skill } 가 주어지면 skill-specific score rubric에 따라 1~5점을 할당
- FLASK-Hard
- Level 5에 해당하는 expert-level knowledge, 89개의 instance를 생성
- 각 스킬에 대한 instance-specific score rubric을 제공
- Skill Set Categorization: 총 12개의 skills
- Results
- Fine-graininess leads to a high correlation between human-based and model-based evaluation
- Fine-grained evaluation mitigates the bias of model-based evaluation
- Open-source models significantly underperform proprietary models on particular skills
- Some skills require larger model sizes
출처 : https://arxiv.org/abs/2307.10928
'Paper Review' 카테고리의 다른 글
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다. (Language & Knowledge Lab의 Retreival 관련)
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[KAIST]
- 각 instruciton에 대해 coarse-level scoring을 skill set-level scoring로 분해
- human & mode based 평가에 대한 fine-grained evaluation protocol, FLASK
- fine-graininess of evaluation은 holistic view를 획득하는데 중요
- 배경
- 기존 LLM 평가 방식은 single metric이라서 LLM의 능력을 평가하기에 불충분
- 또한 surface form에 대해 sensitive하기 때문에 task-wise 한 평가 방식이었음
- Contributions
- 현재 오픈 소스 LLM들은 Logical Thinking과 Background Knowledge에서 proprietary LLM에 비해 현저히 열등한 성능을 보여줌
- Logical Correctness와 Logical Efficiency는 다른 스킬들에 비해 더 큰 모델 사이즈를 필요로 하는 경향이 짙음
- SoTA인 proprietary LLM들 역시 FLASK-Hard에 대해서는 다른 스킬 대비 50%의 성능 하락을 보임
- Related Works
- Holistic Evaluation of LLMs: accuracy, ROUGE, instance-wise fine-grained multi-metric setting
- Alignment of LLMs: instruction tuning, RLHF
- FLASK
- Skill Set Categorization: 총 12개의 skills
- Logical Thinking, Background Knowledge, Problem Handling, User Alignment
- Evaluation Data Construction
- 122개의 데이터셋으로부터 1,740개의 instance를 생성
- essential skills to follow the instruction, target domains, the difficulty level of the instructions를 포함하는 metadata에 대해 annotate
- Evaluation Process
- 각 instance에 대한 annotated metadata를 활용하여 target model의 fine-grained manner의 response를 분석
- { evaluation instruction, reference answer, response of target model, pre-defined score rubric for each selected skill } 가 주어지면 skill-specific score rubric에 따라 1~5점을 할당
- FLASK-Hard
- Level 5에 해당하는 expert-level knowledge, 89개의 instance를 생성
- 각 스킬에 대한 instance-specific score rubric을 제공
- Skill Set Categorization: 총 12개의 skills
- Results
- Fine-graininess leads to a high correlation between human-based and model-based evaluation
- Fine-grained evaluation mitigates the bias of model-based evaluation
- Open-source models significantly underperform proprietary models on particular skills
- Some skills require larger model sizes
출처 : https://arxiv.org/abs/2307.10928