
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다. (Language & Knowledge Lab의 Retreival 관련)
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[KAIST AI, Korea University, NAVER Cloud]
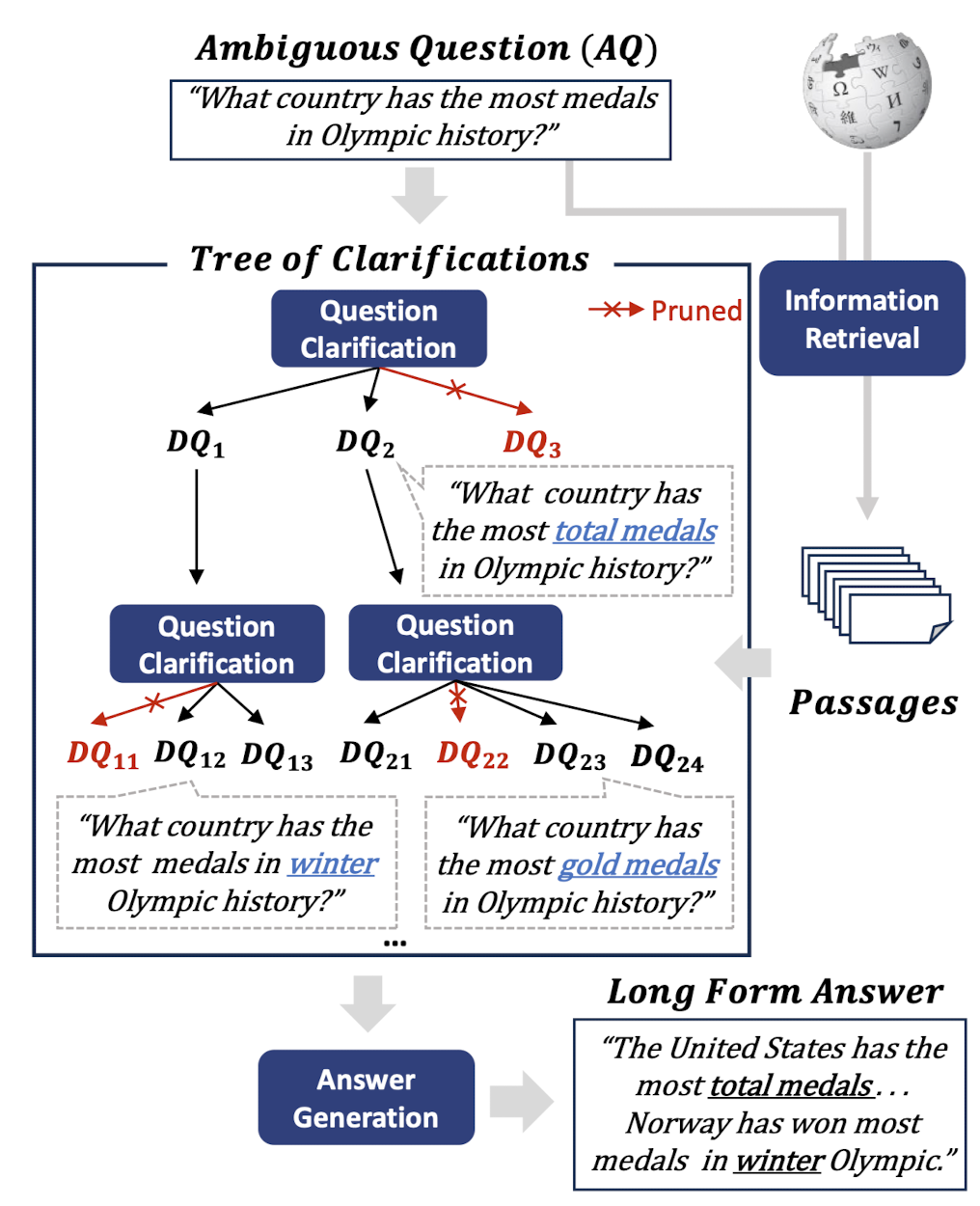
- Ambiguous Question (AQ)에 대한 tree of Disambiguated Question (DQ)을 recursively construct, ToC
- few-shot prompting을 통해 exernal knowledge을 이용 -> long-form answer를 생성
- 배경
- 기존에는 주어진 AQ에 대한 모든 DQ를 구하고, 이에 대한 long-form answer를 생성
- 한계 1) AQ는 multiple dimensions of ambiguity를 고려하여 clarified 되어야 한다
- 한계 2) 많은 knowledge는 DQ와 각 답변을 indentify할 필요가 있다
- Related Works
- ODQA task, LLM-based methods
- Contributions
- LLM은 트리 구조의 AQ에 대한 clarification을 다양한 path를 통해 탐색. 이때 불필요한 DQ를 prune하는 능력이 수반됨
- LLM과 retrieval system을 결합하여 AQ에 대한 long-form answer를 생성하는 최초의 방식
- Tree of Clarifications
- 1) Retrieval-Augmented Clarification (RAC)
- Wikipedia document를 탐색하기 위한 두 개의 retreival systems: 최신 dense retriever인 ColBERT, retrieved Wikipedia passages의 다양성을 보존하기 위한 Bing search engine
- 각 시스템에서 획득한 passage를 합쳐 200개 이상의 passage를 생성
- 이에 대해 SentenceBERT를 활용하여 rerank & choose top-k passages, augment them to a prompt
- 2) Tree Structure (TS)
- AQ인 root node로부터 시작하여 RAC를 재귀적으로 실행하며 child nodes를 생성
- 각 expansion step에서 현재 query에 대해 passage가 reranked
- valid node의 최대 숫자에 이르거나 최대 깊이에 이르면 과정 종료
- 3) Pruning with Self-Verification
- 타겟 노드의 정답과 루트 노드의 AQ 사이의 factual coherency를 체크
- LLM으로 하여금 현재 노드에 대한 pruned or not을 결정하게끔 prompting
- 4) Answer Generation
- 모든 valid node를 aggregate하고 AQ에 대한 comprehensive long-form answer를 생성
- 노드의 숫자가 불충분하면 pruning step에서 제거된 것들 중 root node에 가장 가까운 순서대로 복구
- 1) Retrieval-Augmented Clarification (RAC)
- Benchmarks
- ASQA: long-from QA dataset, 6K ambiguous questions
- Metrics
- 1) Disambig-F1 (D-F1)
- 2) ROUGE-L (R-L)
- 3) DR score
- intermediate ndoe를 validate하기 위해서는 Answer-F1를 사용
- Baselines
- finetuned T5-large / in-context learning GPT-3


- Results
- ToC가 fully-supervised & few-shot prompting baselines을 outperform
- retrieval systems를 통합하는 것은 정확하고 다양한 dismabiguations에 크게 기여
- pruning method는 트리로부터 유용한 disambiguations를 파악하는데 크게 도움
- Limitations
- 다른 종류나 다른 사이즈의 LLM에 대한 실험 결과 부족
- 오직 ASQA 벤치마크 하나에 대해서만 성능 확인
- multiple prompting의 비용이 상당한 편 (무시할 수준이 아니라고 언급)
- CoT와 같은 최신 prompting method를 적용해 보았음에도 불구하고 성능 향상은 없었음
출처 : https://arxiv.org/abs/2310.14696
Tree of Clarifications: Answering Ambiguous Questions with Retrieval-Augmented Large Language Models
Questions in open-domain question answering are often ambiguous, allowing multiple interpretations. One approach to handling them is to identify all possible interpretations of the ambiguous question (AQ) and to generate a long-form answer addressing them
arxiv.org