
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다. (Language & Knowledge Lab의 Retreival 관련)
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[KAIST]
- prompt tuning을 통해 얻은 soft prompt의 retrieval이 hard prompt를 사용하는 zero-shot task의 일반화에 도움이 된다는 것을 확인
- T0 모델의 성능을 향상시키기 위해 추가된 파라미터의 수는 전체의 0.007%에 불과함
- Retrieval of Soft Prompt (RoSPr)
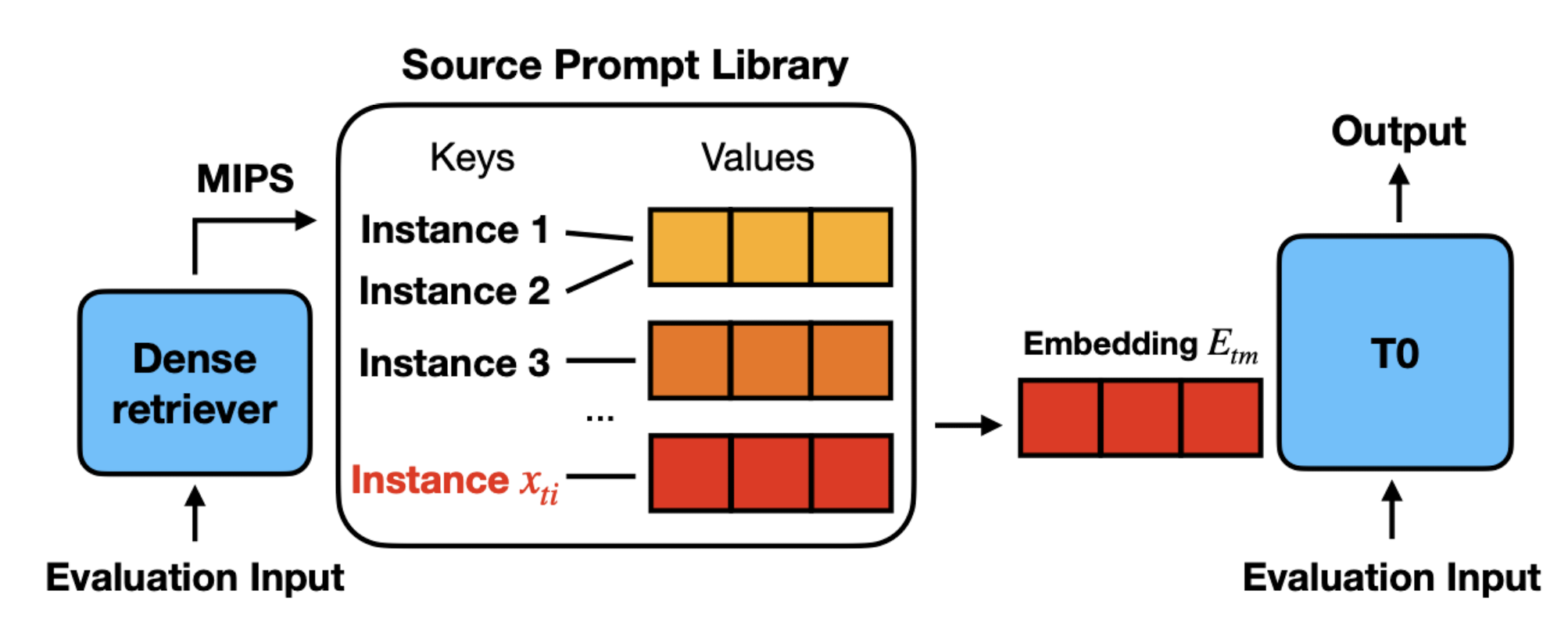
- 배경
- instruction tuning에서 모델 성능 향상시키는 방법은 크게
1) scaling the number of training datasets
2) scaling the model size
로 알려져 있음 - 그러나 두 방식 모두 heavy computation을 요하는 방식이라는 문제점이 있음
- instruction tuning에서 모델 성능 향상시키는 방법은 크게
- Related Works
- Task Generalization with Instruction-Tuning
- prompt & demonstrations는 task generalization에 필수적임
- instruction tuning은 explicit multi-task prompted training on various downstream tasks임
- Source Task Retrieval
- target task와 관련성이 높은 source task를 retrieve하는 것은 더욱 빠르고 정확한 task adapation으로 이어진다는 연구 결과
- 본 논문에서는 training instrance 대신 soft prompt를 retrieve 함으로써 zero-shot 환경에서 source task를 retrieval 할 수 있도록 함
- Task Generalization with Instruction-Tuning
- Contributions
- 추론 동안에 0.007%의 파라미터를 추가하는 것만으로 추론 성능을 크게 향상시켰으며, 이 방법은 scalable 하다는 특징이 있음
- prompt embedding에 상응하는 training instance의 sample로 구성된 Source Prompt Library를 구축
- multiple prompt embedding의 interpolation을 포함하는 Variants of RoSPr
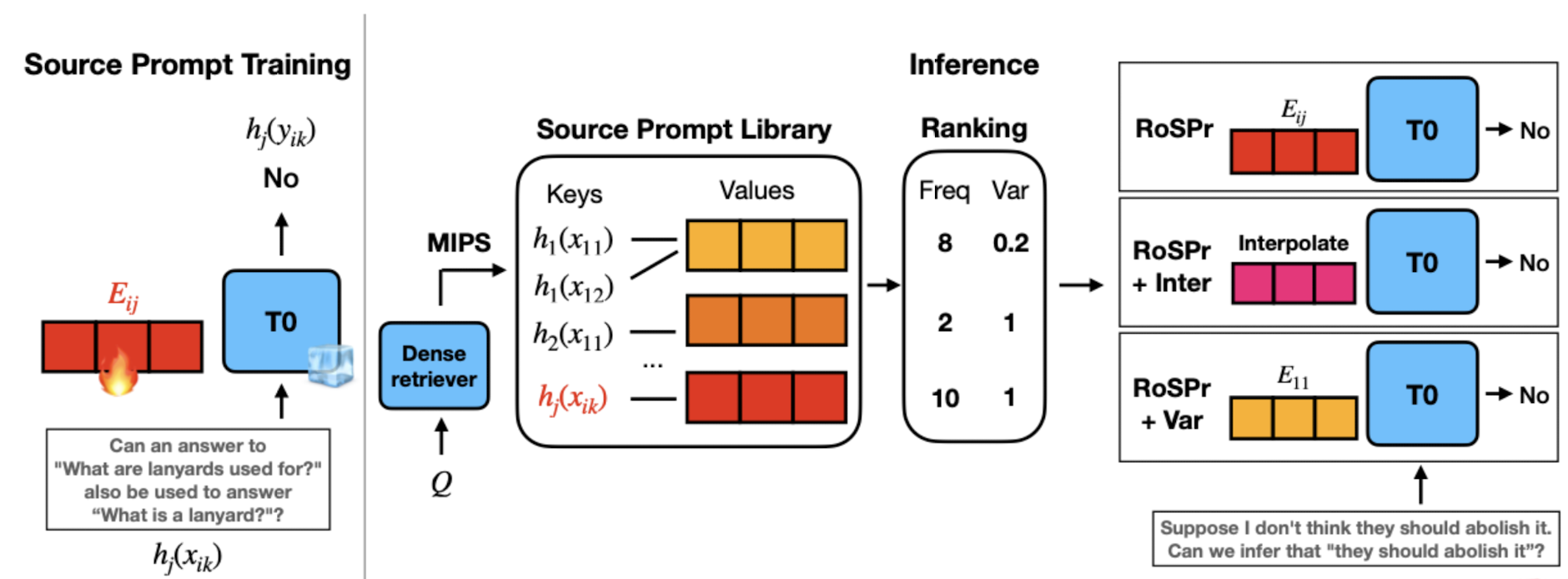
- Method
- 1) Training Source Prompt Embeddings
- T0 모델을 freeze backbone으로 사용하여 soft prompts (source prompt embedding)만을 학습
- Prompt Tuning: 각 데이터셋 D에 포함된 M개의 hard prompt에 대해 soft prompt embedding을 구함
- hard prompted version의 x가 soft embedding과 함께 주어졌을 때, y가 나올 확률을 최대화하는 방식으로 학습
- 2) Zero-Shot Embedding Retrieval
- 관계된 source embedding을 retrieve하고 retrieved candidates 중에서 하나를 select
- sentence-level representation으로 구성된 Source Prompt Library를 구축
-> sentence-level representation은 dense retriever의 last layer의 hidden states에 평균을 취하여 획득 - 각 source prompt embedding마다 n개의 샘플을 라이브러리에 저장
- T0-small 모델을 dense retriever로 사용하여
- 추론시에는 target 태스크로부터 Q개의 query instances를 추출 -> 각 query instance에서 top-N exmaples을 retrieve -> Q * N prompt embeddings
- 3) Interpolation of Prompt Embeddings
- search frequency에 기반한 top-N' 후보 embeddings를 선택하고 weighted sum을 계산
- 어떤 target task fine-tuning도 필요하지 않음
- 4) Variance-based Ranking
- zero-shot classification task에 적용 가능한 scoring method를 도입
- answer choice distribution
- frequency를 Variance로 나누는 식
- 1) Training Source Prompt Embeddings
- Benchmarks
- 4 held-out tasks: Natural Language Inference, Sentence Completion, Conference Resolution, Word Sense Disambiguation -> 11 evaluation datasets
- 14 datasets from BIG-bench
- Baselines
- Zero-shot: T0 (3B), T0 (11B), GPT-3 (175B)
- Fine-tuning
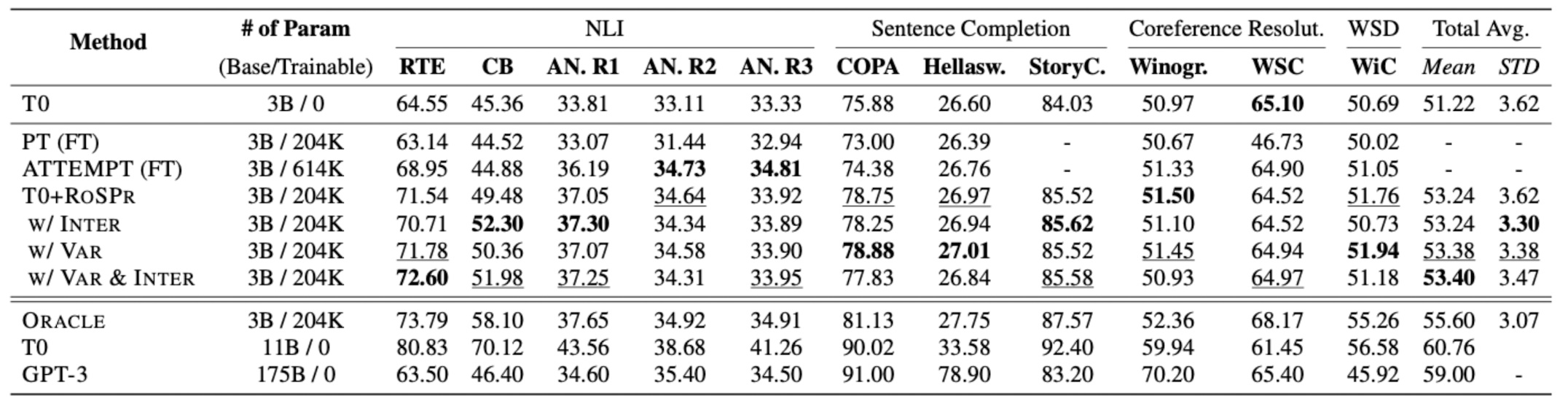
- Results
- RoSPr은 T0의 성능을 효과적으로 향상시킨다.
- INTER (interpolation)와 VAR (Variance-based ranking)은 둘 다 사용되었을 때 RoSPr의 효과를 극대화한다.
- RoSPr의 효과는 challenging task에도 적용 가능하다.
출처 : https://arxiv.org/abs/2210.03029
Efficiently Enhancing Zero-Shot Performance of Instruction Following Model via Retrieval of Soft Prompt
Enhancing the zero-shot performance of instruction-following models requires heavy computation, either by scaling the total number of training datasets or the model size. In this work, we explore how retrieval of soft prompts obtained through prompt tuning
arxiv.org
'Paper Review' 카테고리의 다른 글
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다. (Language & Knowledge Lab의 Retreival 관련)
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[KAIST]
- prompt tuning을 통해 얻은 soft prompt의 retrieval이 hard prompt를 사용하는 zero-shot task의 일반화에 도움이 된다는 것을 확인
- T0 모델의 성능을 향상시키기 위해 추가된 파라미터의 수는 전체의 0.007%에 불과함
- Retrieval of Soft Prompt (RoSPr)
- 배경
- instruction tuning에서 모델 성능 향상시키는 방법은 크게
1) scaling the number of training datasets
2) scaling the model size
로 알려져 있음 - 그러나 두 방식 모두 heavy computation을 요하는 방식이라는 문제점이 있음
- instruction tuning에서 모델 성능 향상시키는 방법은 크게
- Related Works
- Task Generalization with Instruction-Tuning
- prompt & demonstrations는 task generalization에 필수적임
- instruction tuning은 explicit multi-task prompted training on various downstream tasks임
- Source Task Retrieval
- target task와 관련성이 높은 source task를 retrieve하는 것은 더욱 빠르고 정확한 task adapation으로 이어진다는 연구 결과
- 본 논문에서는 training instrance 대신 soft prompt를 retrieve 함으로써 zero-shot 환경에서 source task를 retrieval 할 수 있도록 함
- Task Generalization with Instruction-Tuning
- Contributions
- 추론 동안에 0.007%의 파라미터를 추가하는 것만으로 추론 성능을 크게 향상시켰으며, 이 방법은 scalable 하다는 특징이 있음
- prompt embedding에 상응하는 training instance의 sample로 구성된 Source Prompt Library를 구축
- multiple prompt embedding의 interpolation을 포함하는 Variants of RoSPr
- Method
- 1) Training Source Prompt Embeddings
- T0 모델을 freeze backbone으로 사용하여 soft prompts (source prompt embedding)만을 학습
- Prompt Tuning: 각 데이터셋 D에 포함된 M개의 hard prompt에 대해 soft prompt embedding을 구함
- hard prompted version의 x가 soft embedding과 함께 주어졌을 때, y가 나올 확률을 최대화하는 방식으로 학습
- 2) Zero-Shot Embedding Retrieval
- 관계된 source embedding을 retrieve하고 retrieved candidates 중에서 하나를 select
- sentence-level representation으로 구성된 Source Prompt Library를 구축
-> sentence-level representation은 dense retriever의 last layer의 hidden states에 평균을 취하여 획득 - 각 source prompt embedding마다 n개의 샘플을 라이브러리에 저장
- T0-small 모델을 dense retriever로 사용하여
- 추론시에는 target 태스크로부터 Q개의 query instances를 추출 -> 각 query instance에서 top-N exmaples을 retrieve -> Q * N prompt embeddings
- 3) Interpolation of Prompt Embeddings
- search frequency에 기반한 top-N' 후보 embeddings를 선택하고 weighted sum을 계산
- 어떤 target task fine-tuning도 필요하지 않음
- 4) Variance-based Ranking
- zero-shot classification task에 적용 가능한 scoring method를 도입
- answer choice distribution
- frequency를 Variance로 나누는 식
- 1) Training Source Prompt Embeddings
- Benchmarks
- 4 held-out tasks: Natural Language Inference, Sentence Completion, Conference Resolution, Word Sense Disambiguation -> 11 evaluation datasets
- 14 datasets from BIG-bench
- Baselines
- Zero-shot: T0 (3B), T0 (11B), GPT-3 (175B)
- Fine-tuning
- Results
- RoSPr은 T0의 성능을 효과적으로 향상시킨다.
- INTER (interpolation)와 VAR (Variance-based ranking)은 둘 다 사용되었을 때 RoSPr의 효과를 극대화한다.
- RoSPr의 효과는 challenging task에도 적용 가능하다.
출처 : https://arxiv.org/abs/2210.03029
Efficiently Enhancing Zero-Shot Performance of Instruction Following Model via Retrieval of Soft Prompt
Enhancing the zero-shot performance of instruction-following models requires heavy computation, either by scaling the total number of training datasets or the model size. In this work, we explore how retrieval of soft prompts obtained through prompt tuning
arxiv.org