
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다. (Language & Knowledge Lab의 Retreival 관련)
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Minjoon Seo]
- 단 하나의 task에 대해 fine-tuned된 expert LM이 300개 이상의 task로 학습된 MT (multitask-prompted fine-tuning) LM을 outperform
- distributed approach의 장점: avoiding negative task transfer, continually learn new tasks, compositional capabilities
- 배경
- instruction을 통해 여러 task에 fine-tuned된 모델을 multitask-prompted fine-tuned LMs, MT LM이라고 부름
- 본 논문에서는 한 개의 모델을 여러 개의 task에 대해 학습시키는 것에 의문을 제기
- Related Works
- Multitask Prompted Fine-tuning of Language Models
- 학습 태스크의 숫자를 scaling하는 것이 모델의 성능 향상과 직결되어 있다고 알려짐
- 본 논문에서는 태스크의 feature가 훨씬 중요한 요소라고 주장
- Retrieving task-specific embeddings
- low-resource scenarios에서 task-specific parameters를 retrieve하는 것이 효율적임
- 본 논문에서는 이를 위해 사용되는 retriever로 MT LMs 대신 vanilla pretrained LM을 사용
- Distributed Training of Language Models
- 각 모델이 각 태스크에 대해 독립적으로 학습
- Multitask Prompted Fine-tuning of Language Models
- Contributions
- 뛰어난 seen task performance
- 새로운 태스크에 대한 continual learning
- 여러 expert LM을 결합하는 compositional instructions

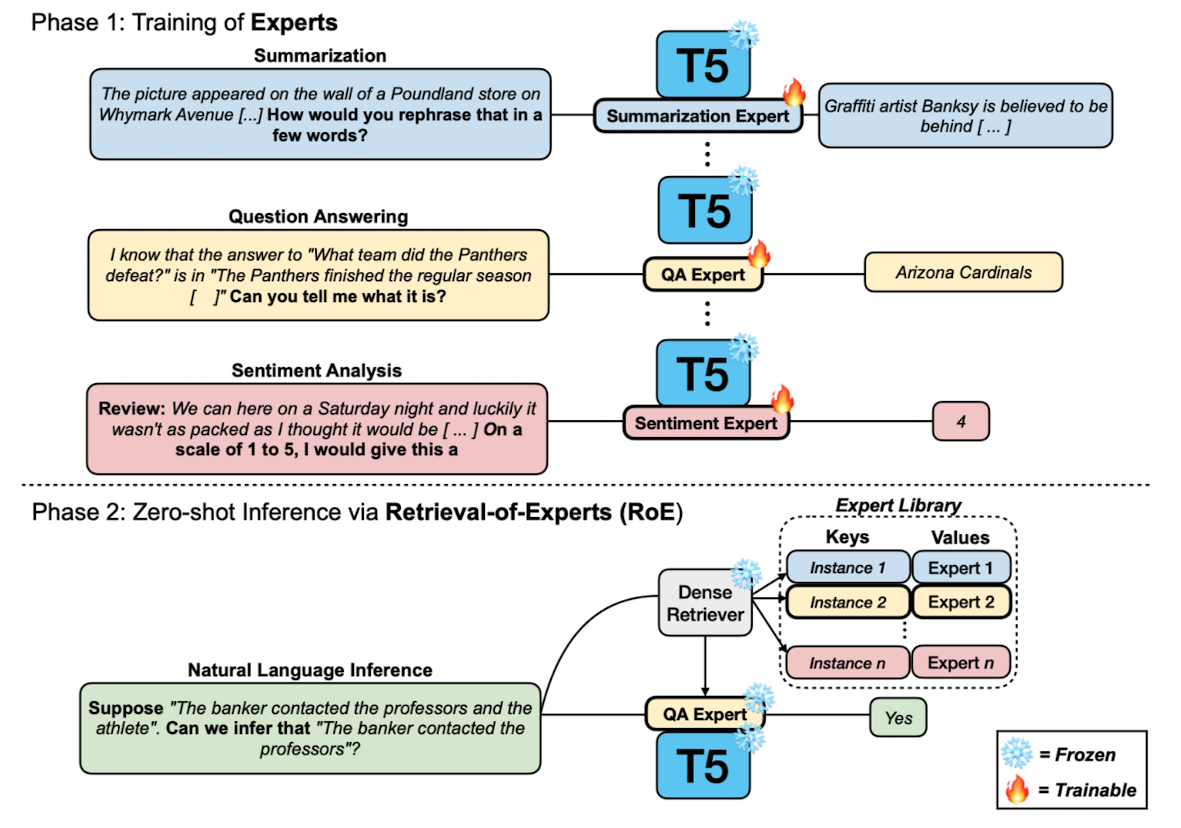
- Expert Language Models
- Training Experts: 각 태스크에 상응하는 prompts로 학습하는 Prompt Experts (PE), 여러 개의 training prompts로 구성된 dataset에 대해 학습하는 Dataset Experts (DE) 둘 다 실험
- Adapters: 기존의 parameter는 freeze하고 추가적인 adapter만 학습하는 parameter efficient 방식
- Retrieval-of-Experts (RoE): Expert Library를 만들고 dense retrieval을 사용하여 관련 expert를 retrieve
- Expert Library: 각 unique expert마다 S개의 training instance를 sample하여 저장
- Retrieval: target task로부터 Q개의 instance를 random select -> 각 Q target query의 embedding representation을 획득 -> MIPS (Maximum Inner Product Search)
- Merging of Experts
- fine-tuned model과 vanilla pretrained LM 차를 비교하는 방식으로 여러 expert를 merge
- 이때 각 expert에 대해 동일한 가중치 부여 (expert의 개수로 나눔)
- Datasets
- 36개의 Dataset Experts (DE)
- 296개의 Prompt Experts (PE)
- Benchmarks
- 4개의 카테고리로 구분되는 11개의 unseen datasets
- 13개의 datasets from BIG-Bench
- 8개의 new generative tasks
- Models
- LM-adapted T5 model
- baselines: MT LMs (T0-3B, T0-11B)
- Result
- 1) Single PE가 T0-3B를 outperform
- 2) RoE가 다른 baseline을 꽤 큰 폭으로 outperform
- 3) Simple RoE 방식이 T0-3B를 outperform
- Limitations
- 11B 보다 큰 사이즈의 모델에 대해서는 실험을 진행하지 못함. 그런데 11B 이상 모델들은 negative task transfer에 덜 susceptible하기 때문에 이러한 연구가 의미 없을 수도 있음
- 이러한 방식의 retrieval 방식은 batch inference를 전제하고 있기 때문에, 다른 상황에서는 적용하지 못할 수 있음
- decomposition을 요하는 더 복잡한 태스크에 대해서는 부적합한 방법일 수 있음
- Training Experts: 각 태스크에 상응하는 prompts로 학습하는 Prompt Experts (PE), 여러 개의 training prompts로 구성된 dataset에 대해 학습하는 Dataset Experts (DE) 둘 다 실험
출처 : https://arxiv.org/abs/2302.03202
Exploring the Benefits of Training Expert Language Models over Instruction Tuning
Recently, Language Models (LMs) instruction-tuned on multiple tasks, also known as multitask-prompted fine-tuning (MT), have shown the capability to generalize to unseen tasks. Previous work has shown that scaling the number of training tasks is the key co
arxiv.org