
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Samsung Research]
- strong LLM을 사용하여 낮은 품질의 데이터를 자동적으로 거르는 simple & effective data selection strategy.
- 52K Alpaca 데이터셋으로부터 정제한 9K 고품질 데이터셋으로 학습한 모델, AlpaGasus
- 다른 instruction-tuning data에도 적용 가능하며, 학습 속도는 빠르면서도 더 좋은 학습 결과를 보임
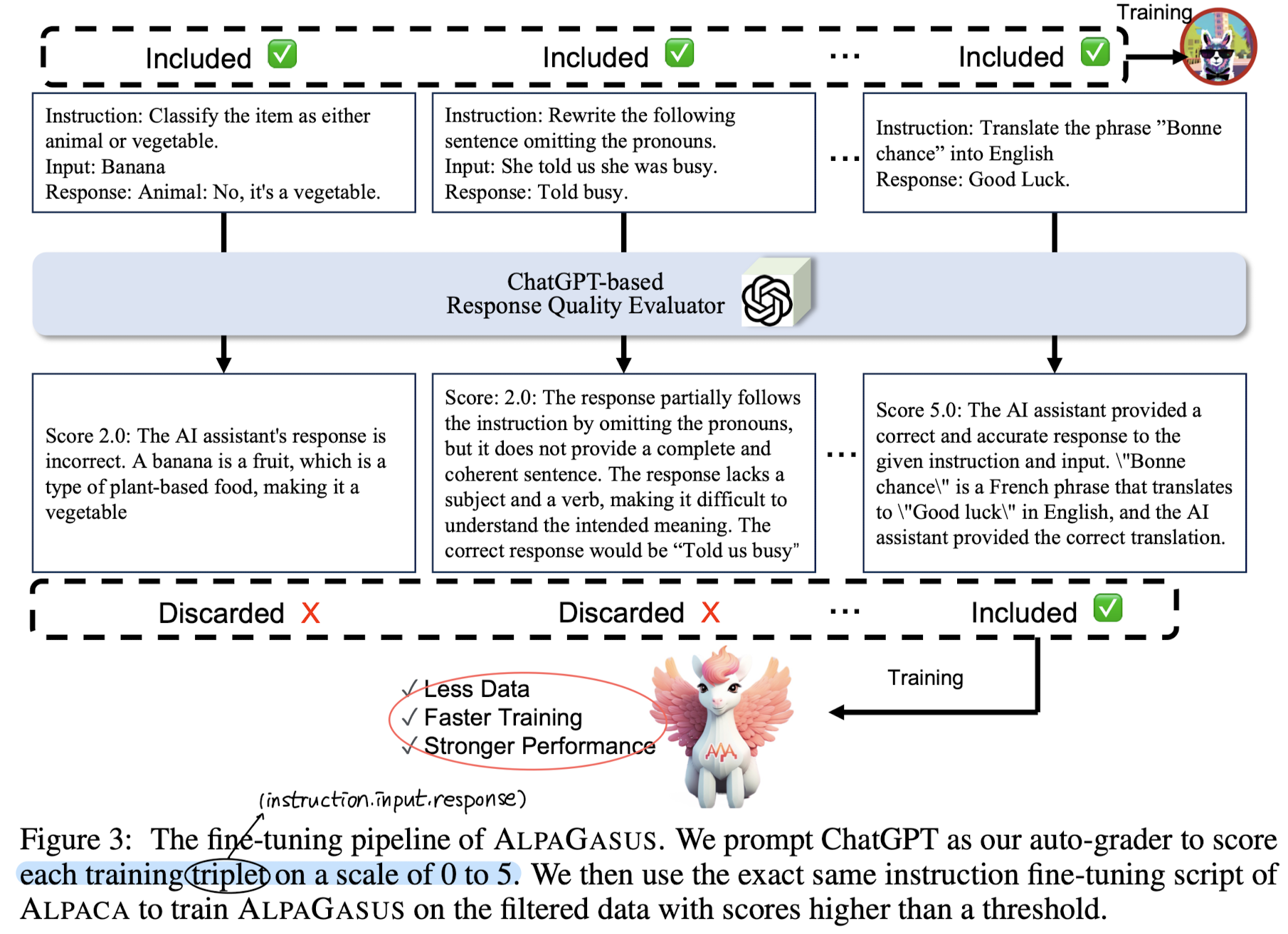
- 배경
- 언어 모델 학습에 있어서 데이터 품질의 중요성은 점점 더 높아지고 있는 추세
- instruction 데이터셋을 사람이 직접 생성하는 것은 많은 비용을 필요로 하여, 최근 LLM을 활용하는 방식이 인기
- 그러나 LLM을 이용해서 생성된 데이터에도 필연적으로 instruction과 관계가 없거나 부정확한 answer가 포함되기 마련
- Related Works
- Open-sourced Instructoin-following models: instruction-tuning datasets은 크게 두 가지 방식으로 구축됨
- 사람이 생성한 instruction & response 쌍을 모으는 crowdsourcing
- teacher LLM으로부터의 distillation을 목표로 하는 machine-generated ITF sets
- Data-centric AI
- 데이터의 품질이 모델 성능/수준을 결정짓는다
- Transformer architecture의 등장 이후로, 모델 아키텍쳐는 큰 변화가 없다고 보는 견해
- Evaluation of LLMs
- 기존 벤치마크의 범위가 굉장히 한정된 편
- Open-sourced Instructoin-following models: instruction-tuning datasets은 크게 두 가지 방식으로 구축됨
- Contributions
- Alapaca 데이터셋에서 고품질 데이터셋을 잘 추출하여 학습한 모델, AlpaGasus가 뛰어난 성능을 보임
- 여기에 사용된 data-filtering approach는 scalability & automation 둘 다 가능
- 다른 instruction fine-tuning 데이터셋이나 LLM에도 일반화 가능한 방식을 제시
- Method
- 평가 기준이 되는 [dimension]은 유저에게 선호되는 특성인 'helpfulness' 또는 'accuracy'를 뜻하는데 본 논문에서는 후자를 택함
- Data Rating and Filtering
- x = (instruction, input, response) triplet으로 이루어진 데이터셋 V, 여기에 속하는 부분 데이터셋 S, 오픈 소스 LLM θ
- API LLM G(), rating prompt p_{G}, score G(x, p_{G})
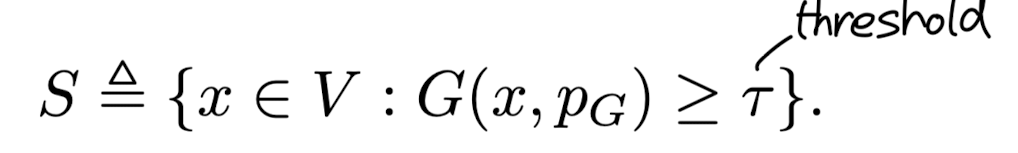

- Baseline
- Alpaca, Text-Davinci-003, ChatGPT, Claude
- Benchmarks
- MMLU, DROP, Humaneval, BBH
- Evaluation Metrics
- API LLM J()로 θ_{S}, θ_{V}를 평가
- F(z; θ_{V}), F(z; θ_{S})는 테스트 데이터셋 D로부터의 instruction z에 대한 response를 뜻함. 이에 대한 모델의 Judge로 얻은 스코어를 비교
- LLM judge에 position bias가 존재한다는 것이 문제로 지적되어 두 모델의 답변 순서를 바꾸어 결과를 종합
- Win: AlpaGasus가 두 번 이김 or 한 번 이기고 한 번 비김
Tie: AlpaGasus가 두 번 비김 or 한 번 이기거나 한 번 짐
Lose: AlpaGasus가 두 번 짐 or 한 번 비기거나 한 번 짐

- Results
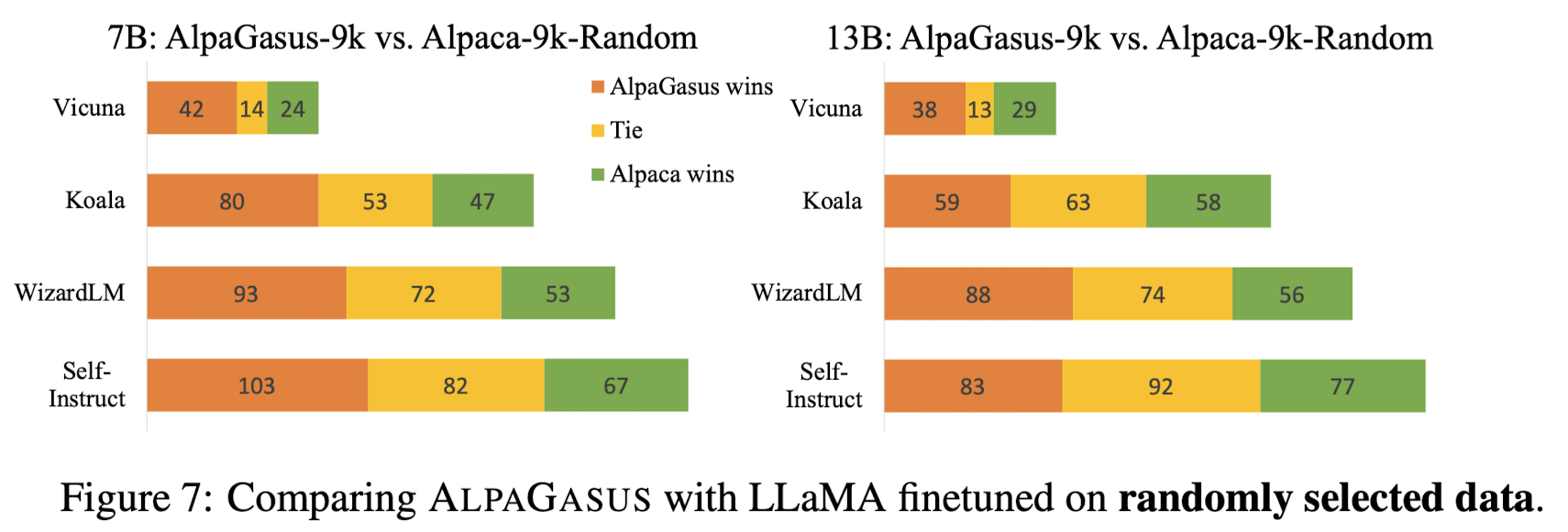
- AlpaGasus-9K가 Alpaca-52K를 압도
- Quality-Guided Filtering (4.5점 이상) 이 Random Filtering 보다 효과적
- data filering Threshold는 4.5점으로 설정하는 것이 가장 적절
- 3/6k/9k selected dataset 사이즈 중에서 9k가 최고 성능 & 6k이면 Alpaca와 유사한 성능 (최소치)
AlpaGasus: Training A Better Alpaca with Fewer Data
Large language models~(LLMs) strengthen instruction-following capability through instruction-finetuning (IFT) on supervised instruction/response data. However, widely used IFT datasets (e.g., Alpaca's 52k data) surprisingly contain many low-quality instanc
arxiv.org
'Paper Review' 카테고리의 다른 글
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Samsung Research]
- strong LLM을 사용하여 낮은 품질의 데이터를 자동적으로 거르는 simple & effective data selection strategy.
- 52K Alpaca 데이터셋으로부터 정제한 9K 고품질 데이터셋으로 학습한 모델, AlpaGasus
- 다른 instruction-tuning data에도 적용 가능하며, 학습 속도는 빠르면서도 더 좋은 학습 결과를 보임
- 배경
- 언어 모델 학습에 있어서 데이터 품질의 중요성은 점점 더 높아지고 있는 추세
- instruction 데이터셋을 사람이 직접 생성하는 것은 많은 비용을 필요로 하여, 최근 LLM을 활용하는 방식이 인기
- 그러나 LLM을 이용해서 생성된 데이터에도 필연적으로 instruction과 관계가 없거나 부정확한 answer가 포함되기 마련
- Related Works
- Open-sourced Instructoin-following models: instruction-tuning datasets은 크게 두 가지 방식으로 구축됨
- 사람이 생성한 instruction & response 쌍을 모으는 crowdsourcing
- teacher LLM으로부터의 distillation을 목표로 하는 machine-generated ITF sets
- Data-centric AI
- 데이터의 품질이 모델 성능/수준을 결정짓는다
- Transformer architecture의 등장 이후로, 모델 아키텍쳐는 큰 변화가 없다고 보는 견해
- Evaluation of LLMs
- 기존 벤치마크의 범위가 굉장히 한정된 편
- Open-sourced Instructoin-following models: instruction-tuning datasets은 크게 두 가지 방식으로 구축됨
- Contributions
- Alapaca 데이터셋에서 고품질 데이터셋을 잘 추출하여 학습한 모델, AlpaGasus가 뛰어난 성능을 보임
- 여기에 사용된 data-filtering approach는 scalability & automation 둘 다 가능
- 다른 instruction fine-tuning 데이터셋이나 LLM에도 일반화 가능한 방식을 제시
- Method
- 평가 기준이 되는 [dimension]은 유저에게 선호되는 특성인 'helpfulness' 또는 'accuracy'를 뜻하는데 본 논문에서는 후자를 택함
- Data Rating and Filtering
- x = (instruction, input, response) triplet으로 이루어진 데이터셋 V, 여기에 속하는 부분 데이터셋 S, 오픈 소스 LLM θ
- API LLM G(), rating prompt p_{G}, score G(x, p_{G})
- Baseline
- Alpaca, Text-Davinci-003, ChatGPT, Claude
- Benchmarks
- MMLU, DROP, Humaneval, BBH
- Evaluation Metrics
- API LLM J()로 θ_{S}, θ_{V}를 평가
- F(z; θ_{V}), F(z; θ_{S})는 테스트 데이터셋 D로부터의 instruction z에 대한 response를 뜻함. 이에 대한 모델의 Judge로 얻은 스코어를 비교
- LLM judge에 position bias가 존재한다는 것이 문제로 지적되어 두 모델의 답변 순서를 바꾸어 결과를 종합
- Win: AlpaGasus가 두 번 이김 or 한 번 이기고 한 번 비김
Tie: AlpaGasus가 두 번 비김 or 한 번 이기거나 한 번 짐
Lose: AlpaGasus가 두 번 짐 or 한 번 비기거나 한 번 짐
- Results
- AlpaGasus-9K가 Alpaca-52K를 압도
- Quality-Guided Filtering (4.5점 이상) 이 Random Filtering 보다 효과적
- data filering Threshold는 4.5점으로 설정하는 것이 가장 적절
- 3/6k/9k selected dataset 사이즈 중에서 9k가 최고 성능 & 6k이면 Alpaca와 유사한 성능 (최소치)
AlpaGasus: Training A Better Alpaca with Fewer Data
Large language models~(LLMs) strengthen instruction-following capability through instruction-finetuning (IFT) on supervised instruction/response data. However, widely used IFT datasets (e.g., Alpaca's 52k data) surprisingly contain many low-quality instanc
arxiv.org