
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[BigScience]
- 사전학습된 encoder-decoder 모델 T5를 explicit multi-task learning으로 fine-tuning한 모델, T0
- 다양한 태스크에 대한 zero-shot 성능 일반화 & prompt를 구성하는 word의 다양성 확보 (robustness)
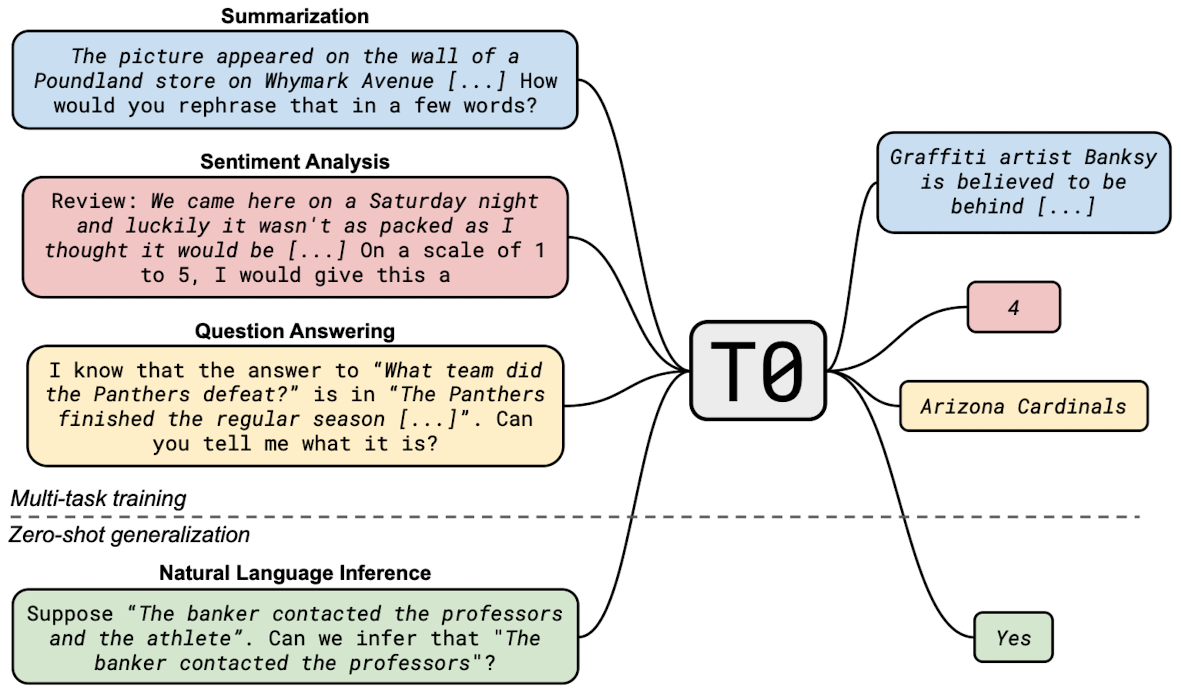
- 배경
- LLM이 새로운 태스크에 대해 뛰어난 zero-shot 성능을 보이는 것이 확인됨
- 그러나 학습 때 접하지 않았던 태스크에 대해 좋은 성능을 보이기 위해선
1) 충분히 큰 사이즈의 모델이 필요하고
2) prompt를 구성하는 단어에 영향을 받지 않게 만들어야 함 - 지금까지는 multitask learning이 이루어진다고 해도 implicit하게, 즉 사전학습 단계에서 corpus 자체를 익히는 방식으로 학습되어 왔음
- Related Works
- Implicit Multitask Learning: 여러 개의 태스크를 한 개의 supervised training process로 섞는 방식. T5가 대표 모델
- Explicit Multitask Learning: prompt diversity, model scale, held-out-task scheme
- Contributions
- Fine-tuned된 모델 T0가 GPT-3에 준하거나 이를 넘어서는 성능을 보임
- '각 데이터셋마다 더 많고 다양한 프롬프트를 사용하는 것 & 다양한 종류의 데이터셋을 프롬프트로 만드는 것'이 모델 학습에 유리하다는 것을 입증
- Measuring Generalization to Held-Out Tasks
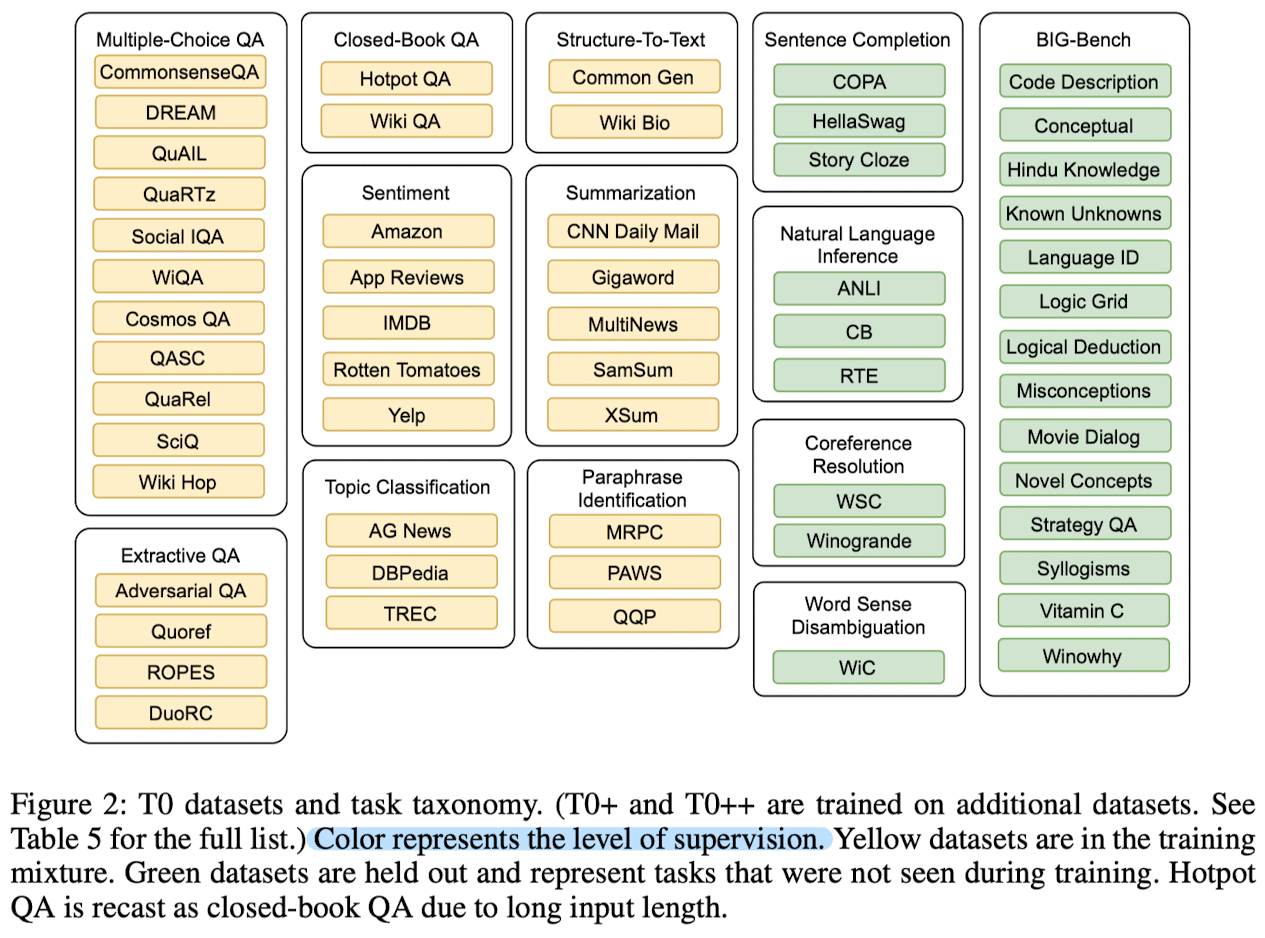
- NLP dataset의 일부를 tasks로 변환
- 영어가 아닌 언어로 작성된 데이터 & 특정 도메인 지식이 필요한 데이터는 제외
- 12 tasks & 62 datasets, Hugging Face datasets library의 데이터셋을 사용
- 학습에 사용한 데이터셋의 개수에 따라 세 모델로 구분: T0, T0, T++
- A Unified Prompt Format
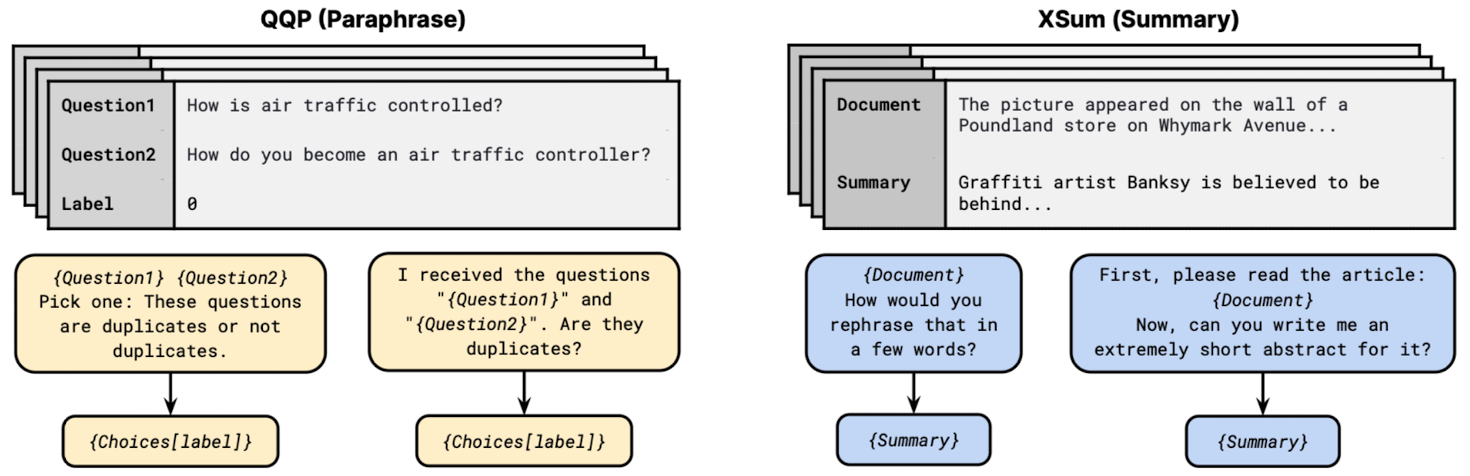
- 모델에 제공되는 모든 데이터셋은 zero-shot experimentation이 가능하도록 natural language prompted form을 갖춤
- prompt는 'input template & target template'로 구성된다고 정의
- 데이터셋에 대해 interactively writing prompts할 수 있도록 interface를 설계
- contributor들이 각자의 스타일대로 다양한 프롬프트를 생성할 수 있도록 격려
- 2073 prompts for 177 datasets로 구성된 Public Pool of Prompts (P3) 로부터 태스크에 맞는 프롬프트 생성
- Benchmark
- Natural Language Inference (NLI), Conference Resolution, Sentence Completion, Word Sense Disambiguation, subset from BIG-bench
- Model & Baseline
- T5 모델은 input text에 없는 토큰을 생성하는 objective를 갖고 있기 때문에 backbone으로 사용하기에 부적합
- standard language modeling objective를 가지고 C4로부터 100B additional tokens에 대해 T5를 학습시킨, LM-adapted T5 model (T5+LM)을 backbone 모델 사용
- T5+LM, T0, GPT-3
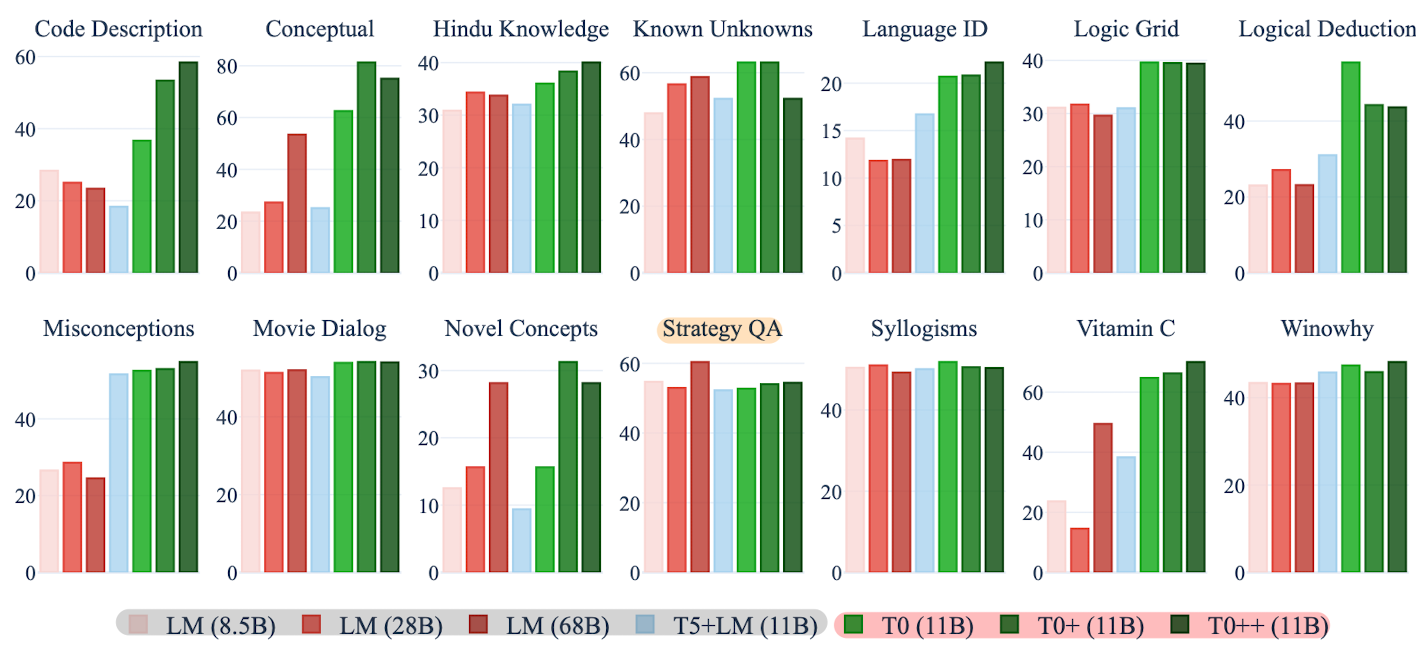
- Results
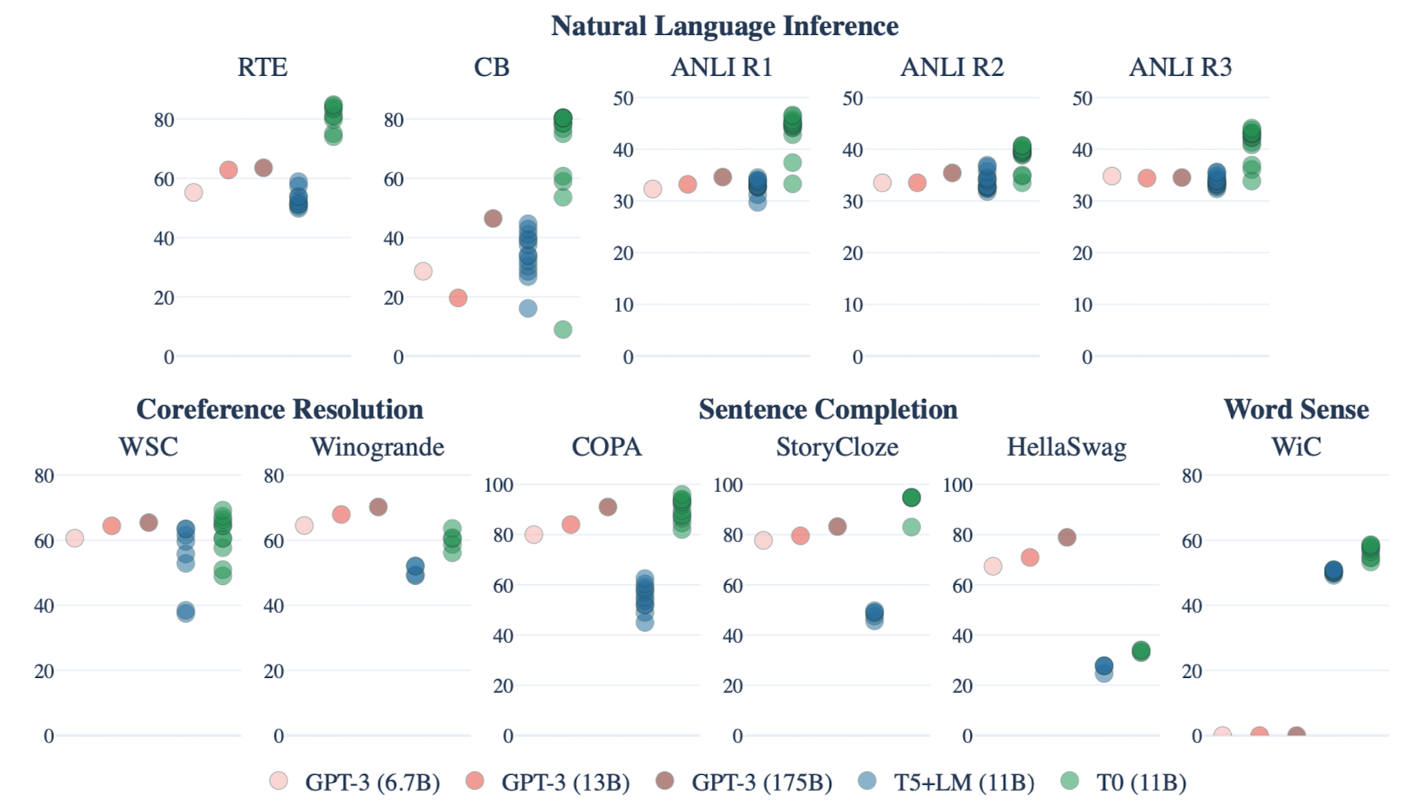
- multitask prompted training이 기존 동일한 모델 및 prompt 기반 학습 보다 우월한 성능을 보임
- 심지어 11개의 held-out datasets 중 9개에서 GPT-3를 능가하는 성능을 보임
- 단, Winogrande & HellaSwag 데이터셋에 대해서는 약세를 보임
- 데이터셋마다 여러 개의 prompt를 사용할수록 도움이 된다는 것을 확인
- 데이터셋 자체를 여러 개 쓰는 것도 도움이 되지만 필연적인 성능 향상으로 이어지지는 않음
출처 : https://arxiv.org/abs/2110.08207
Multitask Prompted Training Enables Zero-Shot Task Generalization
Large language models have recently been shown to attain reasonable zero-shot generalization on a diverse set of tasks (Brown et al., 2020). It has been hypothesized that this is a consequence of implicit multitask learning in language models' pretraining
arxiv.org
'Paper Review' 카테고리의 다른 글
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[BigScience]
- 사전학습된 encoder-decoder 모델 T5를 explicit multi-task learning으로 fine-tuning한 모델, T0
- 다양한 태스크에 대한 zero-shot 성능 일반화 & prompt를 구성하는 word의 다양성 확보 (robustness)
- 배경
- LLM이 새로운 태스크에 대해 뛰어난 zero-shot 성능을 보이는 것이 확인됨
- 그러나 학습 때 접하지 않았던 태스크에 대해 좋은 성능을 보이기 위해선
1) 충분히 큰 사이즈의 모델이 필요하고
2) prompt를 구성하는 단어에 영향을 받지 않게 만들어야 함 - 지금까지는 multitask learning이 이루어진다고 해도 implicit하게, 즉 사전학습 단계에서 corpus 자체를 익히는 방식으로 학습되어 왔음
- Related Works
- Implicit Multitask Learning: 여러 개의 태스크를 한 개의 supervised training process로 섞는 방식. T5가 대표 모델
- Explicit Multitask Learning: prompt diversity, model scale, held-out-task scheme
- Contributions
- Fine-tuned된 모델 T0가 GPT-3에 준하거나 이를 넘어서는 성능을 보임
- '각 데이터셋마다 더 많고 다양한 프롬프트를 사용하는 것 & 다양한 종류의 데이터셋을 프롬프트로 만드는 것'이 모델 학습에 유리하다는 것을 입증
- Measuring Generalization to Held-Out Tasks
- NLP dataset의 일부를 tasks로 변환
- 영어가 아닌 언어로 작성된 데이터 & 특정 도메인 지식이 필요한 데이터는 제외
- 12 tasks & 62 datasets, Hugging Face datasets library의 데이터셋을 사용
- 학습에 사용한 데이터셋의 개수에 따라 세 모델로 구분: T0, T0, T++
- A Unified Prompt Format
- 모델에 제공되는 모든 데이터셋은 zero-shot experimentation이 가능하도록 natural language prompted form을 갖춤
- prompt는 'input template & target template'로 구성된다고 정의
- 데이터셋에 대해 interactively writing prompts할 수 있도록 interface를 설계
- contributor들이 각자의 스타일대로 다양한 프롬프트를 생성할 수 있도록 격려
- 2073 prompts for 177 datasets로 구성된 Public Pool of Prompts (P3) 로부터 태스크에 맞는 프롬프트 생성
- Benchmark
- Natural Language Inference (NLI), Conference Resolution, Sentence Completion, Word Sense Disambiguation, subset from BIG-bench
- Model & Baseline
- T5 모델은 input text에 없는 토큰을 생성하는 objective를 갖고 있기 때문에 backbone으로 사용하기에 부적합
- standard language modeling objective를 가지고 C4로부터 100B additional tokens에 대해 T5를 학습시킨, LM-adapted T5 model (T5+LM)을 backbone 모델 사용
- T5+LM, T0, GPT-3
- Results
- multitask prompted training이 기존 동일한 모델 및 prompt 기반 학습 보다 우월한 성능을 보임
- 심지어 11개의 held-out datasets 중 9개에서 GPT-3를 능가하는 성능을 보임
- 단, Winogrande & HellaSwag 데이터셋에 대해서는 약세를 보임
- 데이터셋마다 여러 개의 prompt를 사용할수록 도움이 된다는 것을 확인
- 데이터셋 자체를 여러 개 쓰는 것도 도움이 되지만 필연적인 성능 향상으로 이어지지는 않음
출처 : https://arxiv.org/abs/2110.08207
Multitask Prompted Training Enables Zero-Shot Task Generalization
Large language models have recently been shown to attain reasonable zero-shot generalization on a diverse set of tasks (Brown et al., 2020). It has been hypothesized that this is a consequence of implicit multitask learning in language models' pretraining
arxiv.org