
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Facebook AI]
- sequence-to-sequence models 사전 학습을 위한 denoising autoencoder, BART
- (1) corrupting text with an arbitrary noising function, (2) learning a model to reconstruct the original text
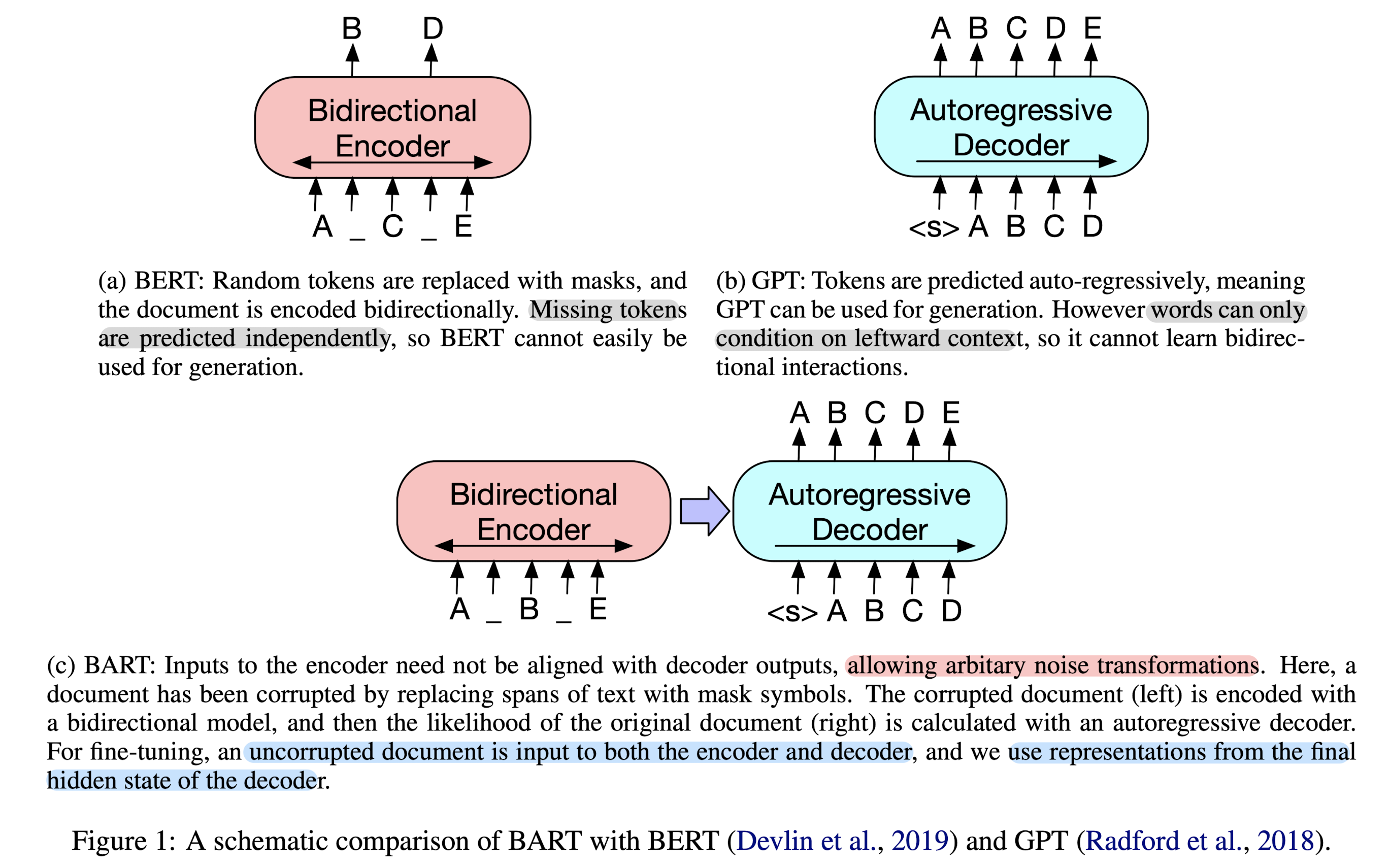
- 배경
- 당시 Masked Language Model (MLM)이 뛰어난 성능을 보이는 것으로 알려져 있었으나 특정 태스크에 한정된 이야기였음
- Related Works
- GPT, ELMo
- BERT, UniLM
- MASS, XL-Net
- Contributions
- 기존 텍스트에 다양한 noise 방식을 적용할 수 있는 유연한 아키텍쳐를 지녔다
- BART 모델은 text generation 뿐만 아니라 comprehension tasks에서도 강점을 보인다(RoBERTa에 준하는 성능).
- BART: Bidirectional and Auto-Regressive Transformers
- Architecture
- ReLU -> GeLU, 6 layers for encoder & decoder, 인코더 마지막 hidden layer에 대한 cross-attention
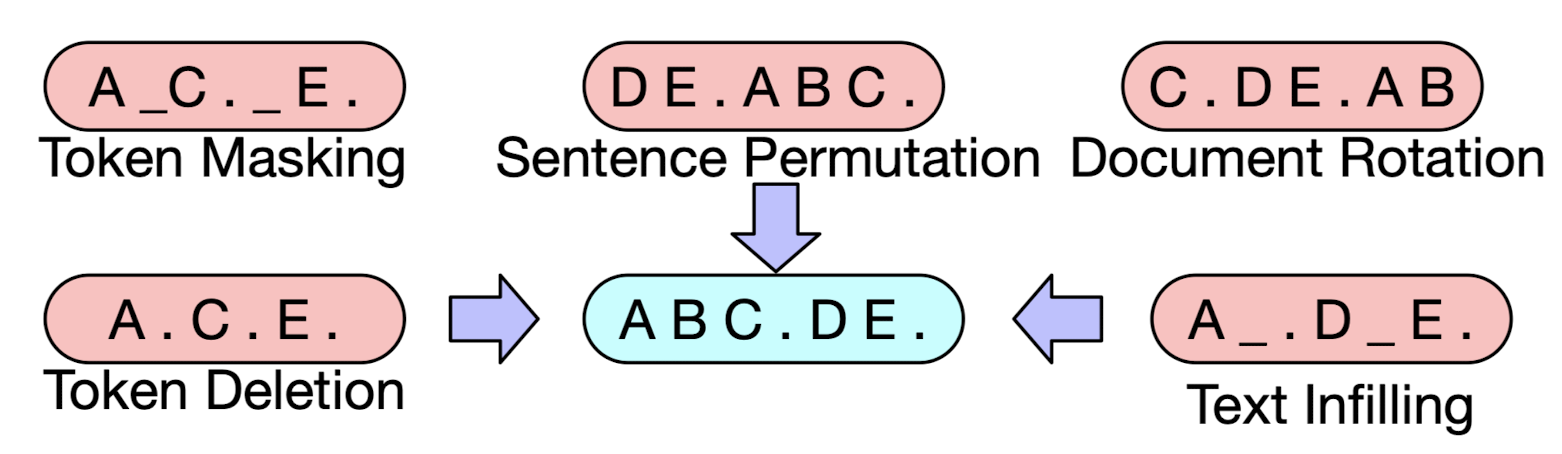
- Pre-training BART
- Token Masking, Token Deletion, Text Infilling, Sentence Permutation, Document Rotation
- Architecture
- Fine-tuning BART
- Sequence Classification Tasks, Token Classification Tasks, Sequence Generation Tasks, Machine Translation
- Comparison Objectives
- Language Model, Permuted Language Model, Masked Language Model, Multitask Masked Language Model, Masked Seq-to-Seq
- Tasks
- SQuAD, MNLI, ELI5, XSum, ConvAI2, CNN/DM
- Results
- 사전 학습 방식의 효과는 태스크의 종류에 크게 의존
- token masking이 중요
- MLM과 Permuted Language Model과 같은 Left-to-right pre-training은 생성에 취약. 대신 SQuAD에 장점
출처 : https://arxiv.org/abs/1910.13461
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
We present BART, a denoising autoencoder for pretraining sequence-to-sequence models. BART is trained by (1) corrupting text with an arbitrary noising function, and (2) learning a model to reconstruct the original text. It uses a standard Tranformer-based
arxiv.org
'Paper Review' 카테고리의 다른 글
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Facebook AI]
- sequence-to-sequence models 사전 학습을 위한 denoising autoencoder, BART
- (1) corrupting text with an arbitrary noising function, (2) learning a model to reconstruct the original text
- 배경
- 당시 Masked Language Model (MLM)이 뛰어난 성능을 보이는 것으로 알려져 있었으나 특정 태스크에 한정된 이야기였음
- Related Works
- GPT, ELMo
- BERT, UniLM
- MASS, XL-Net
- Contributions
- 기존 텍스트에 다양한 noise 방식을 적용할 수 있는 유연한 아키텍쳐를 지녔다
- BART 모델은 text generation 뿐만 아니라 comprehension tasks에서도 강점을 보인다(RoBERTa에 준하는 성능).
- BART: Bidirectional and Auto-Regressive Transformers
- Architecture
- ReLU -> GeLU, 6 layers for encoder & decoder, 인코더 마지막 hidden layer에 대한 cross-attention
- Pre-training BART
- Token Masking, Token Deletion, Text Infilling, Sentence Permutation, Document Rotation
- Architecture
- Fine-tuning BART
- Sequence Classification Tasks, Token Classification Tasks, Sequence Generation Tasks, Machine Translation
- Comparison Objectives
- Language Model, Permuted Language Model, Masked Language Model, Multitask Masked Language Model, Masked Seq-to-Seq
- Tasks
- SQuAD, MNLI, ELI5, XSum, ConvAI2, CNN/DM
- Results
- 사전 학습 방식의 효과는 태스크의 종류에 크게 의존
- token masking이 중요
- MLM과 Permuted Language Model과 같은 Left-to-right pre-training은 생성에 취약. 대신 SQuAD에 장점
출처 : https://arxiv.org/abs/1910.13461
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
We present BART, a denoising autoencoder for pretraining sequence-to-sequence models. BART is trained by (1) corrupting text with an arbitrary noising function, and (2) learning a model to reconstruct the original text. It uses a standard Tranformer-based
arxiv.org