
오랜만에 재밌는 주제의 세션이 많은 행사를 다녀왔습니다!!
이유는 모르겠지만 최근 AI 관련 행사가 엄~~청나게 많이 몰려 있었는데 (삼성, 구글 등등)..
죄다 평일이라 딱 하루만 잘 골라서 가야 하는 상황이었습니다.
(매일 참석하고 싶었지만 그건 제 마음이고.. 대표님의 마음은 조금 다를 수 있기 때문에.. 😭)
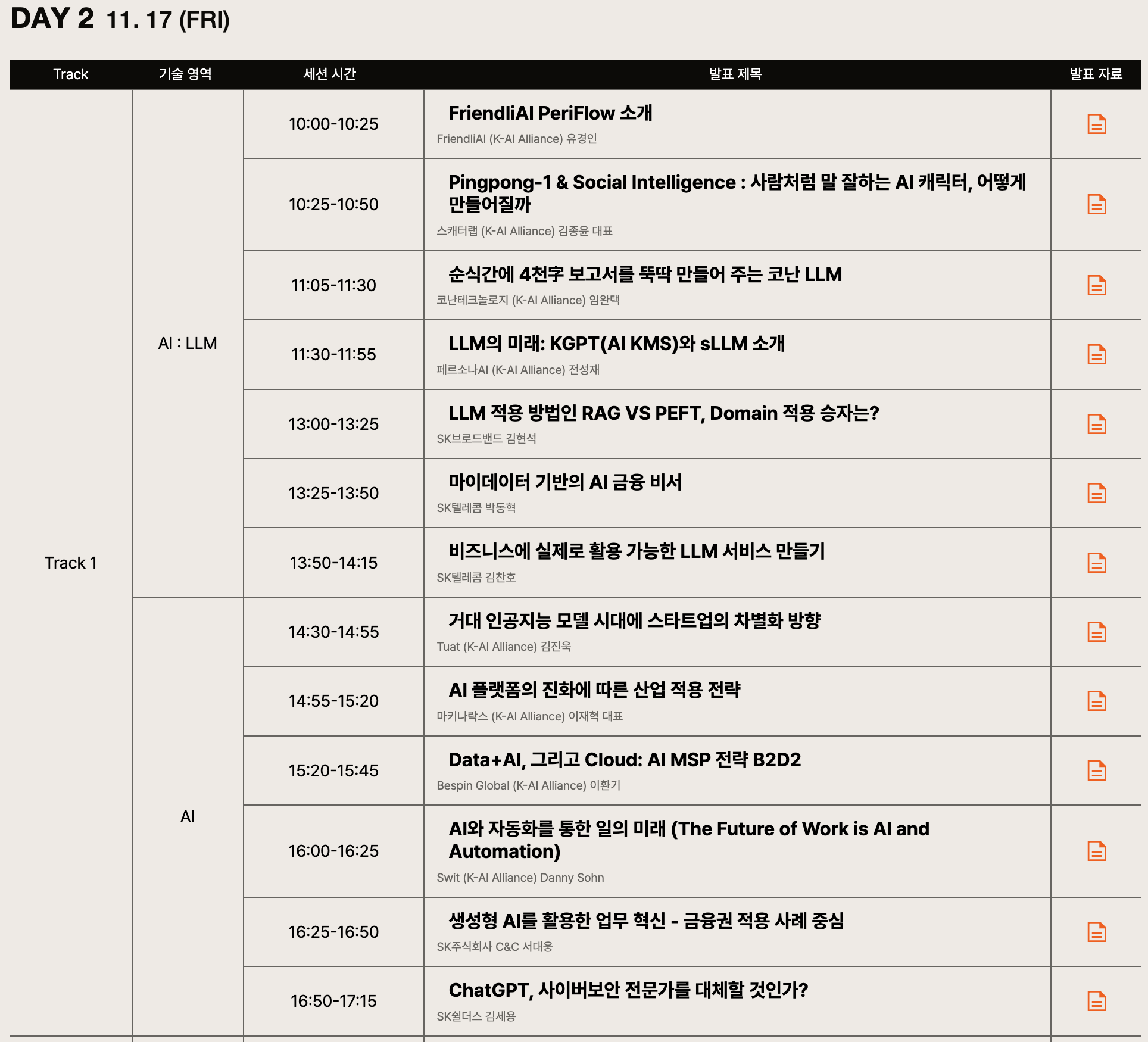
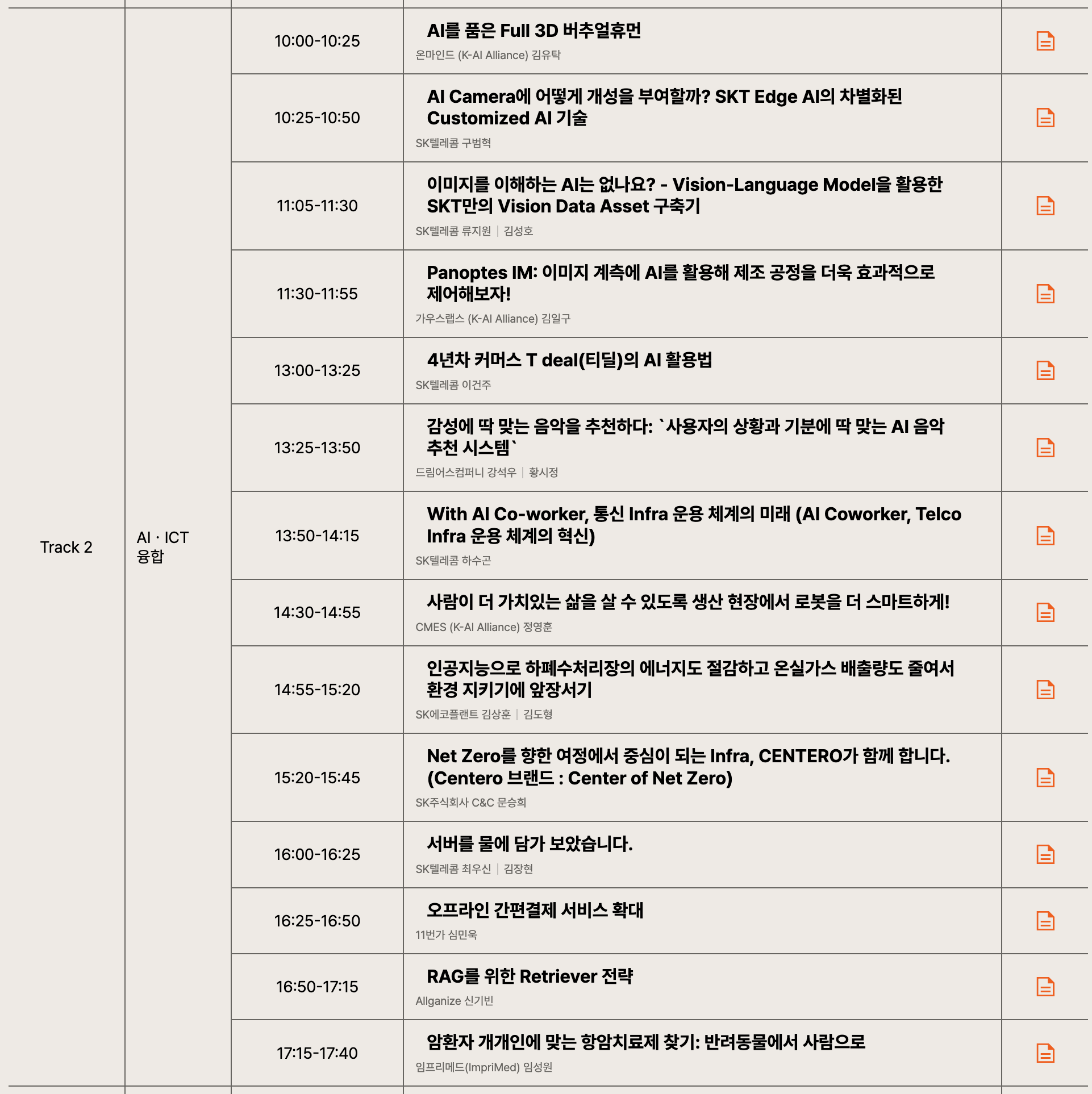
그중에서 다양한 기업들이 자신의 LLM 관련 서비스나 개발 관련 내용을 다루는 SK Tech Summit 2023의 2일차를 다녀오기로 결정했습니다.
11.16 (목) - 11.17 (금) 양일 간 진행되는 행사로, 1일차에는 SK의 자체 LLM인 에이닷 관련 소식이 주를 이루고 있었기 때문에 더 다양한 내용을 다루는 2일차로 마음을 정했죠.
(🔗 세션 리스트 링크)
코엑스에서 행사가 진행되었는데..
가는 길도 너무 험난하고 (길을 잃어버렸습니다..) 사람도 많아서 무척 힘들었던 하루였습니다 😂

목차
1. 재밌었던 세션 간단 정리!
2. 전시 부스
3. 너무 아쉬웠던 행사 운영 💢💢💢
4. 대세는 RAG, 핵심은 Data (그런데 사람을 곁들인..)
5. 길 찾기 어려워..
1. 재밌었던 세션 간단 정리!
1) FriendliAI PeriFlow (FriendliAI)
사실 조금 지각하는 바람에 세션 내용은 거의 듣질 못했고요..
전시 부스에서 간단한 설명을 들었었는데, LLM을 운용하기에 좋은 서비스를 제공하는 것 같더라구요!
제대로 이해한 것이 맞다면, 특정 기업이 사용하는 LLM들을 서버에 업로드해서 추론하는 과정 등을 최적화하여 latency를 최대한 낮춘 솔루션을 제공하는 것 같았습니다.
스캐터랩이나 튜닙같은 잘나가는 스타트업들도 해당 서비스를 이용하고 있다고 하네요 😲
2) Pingpong-1 & Social Intelligence: 사람처럼 말 잘하는 AI 캐릭터, 어떻게 만들어질까 (스캐터랩) ⭐️⭐️⭐️⭐️⭐️

인공지능을 공부하는 사람이 아니더라도 한국인이라면 이루다를 한 번쯤은 들어본 적이 있을 것 같아요.
예전에는 거친 말을 잘하는 심심이가 있었다면, 정말 사람처럼 대화 가능한 인공지능 이루다가 그 자리를 이어 받은 느낌이 있었죠.
그런데 몇 년 전에 이루다 서비스와 관련된 치명적인 문제점들이 밝혀지면서 난리가 났었습니다 ⚠️
개인 정보 유출과 인공 지능의 성적 대상화 관련 이슈였는데요,
요즘 자주 사용되는 표현을 빌리자면 jailbreak 또는 adversarial attack으로 표현할 수도 있겠네요 🚨
학습 당시 사용되었던 정보들을 필터링 없이 다른 사람에게 쉽게 제공해버리는 것이 알려지면서 난리이기도 했고,
특정 프롬프트들을 입력해 이루다를 성적 대상으로 만들어 버린 것이 음지 커뮤니티에 공유되면서 큰 문제점으로 지적되기도 했습니다.
논란이 많았던 이루다는 서비스를 잠정 중단하고 몇 년 뒤 2.0 버전으로 세상에 다시 돌아오게 되었죠.
이때 사용된 모델 이름이 Pingpong 이라고 합니다.
굉장히 재밌었던 포인트는, '대화형 이외의 데이터들을 학습 데이터로 사용하여 기본적인 수준의 knowledge 또는 reasoning ability 등을 향상시켰다', 는 것과 '잘 생성하는 것보다 재미있게 생성하도록 만드는 것이 중요' 하다는 점이었습니다.
대화를 한다고 하더라도 기본적인 소통 능력이 전제되지 않으면 안된다는 것을 깨달았다고 하시네요.
또한 정말 센스있는 답변을 하거나 재미있는 대화가 이뤄지는 것이 목표이기 때문에 자체적인 벤치마크를 구축하여 모델 성능을 확인하고 있다고 합니다.
마지막으로 jailbreak 관련해서는, 오히려 사람들이 그런 것들을 jailbreak에 성공했을 때 더욱 더 즐거움(?)을 느끼는 경향이 있어서 웬만한 내용들은 그대로 쓸 수 있게 내버려 두고 있다고 밝히신 점이 아주 흥미로웠습니다 ㅋㅋㅋㅋ
또 대표님이 엄청 유쾌하시고 발표를 재밌게 하셔서 너무 재밌었어요!

3) 순식간에 4천자 보고서를 뚝딱 만들어 주는 코난 LLM (코난테크놀로지)
기업 입장에서는 LLM을 활용하고 싶어도 결국 보안 이슈때문에 사용하지 못하는 경우가 많다고 합니다.
이를 위해 코난 LLM은 자체 백본 모델에 고객이 원하는 데이터를 추가 학습한 모델을 운용해주는 서비스를 제공한다고 하네요.
개인적으로는 모델을 어떻게 학습시켰는지, 데이터셋을 어떻게 구축했는지에 대해 궁금했는데 그런 내용을 크게 다루지는 않았던 것으로 기억합니다.
기억나는 것 하나만 꼽자면, Chinchilla 모델처럼 모델의 사이즈를 키우는 것보다 더 많은 데이터를 학습에 활용하는 것이 중요하다는 것을 전제로 깔고 모델을 학습시켰다고 하네요.
데이터셋 사이즈가 수십 기가에 달한다고 언급하셨던 것으로 기억하는데, 확실히 데이터의 중요성이 더욱 더 대두되는 듯한 느낌을 받았습니다.
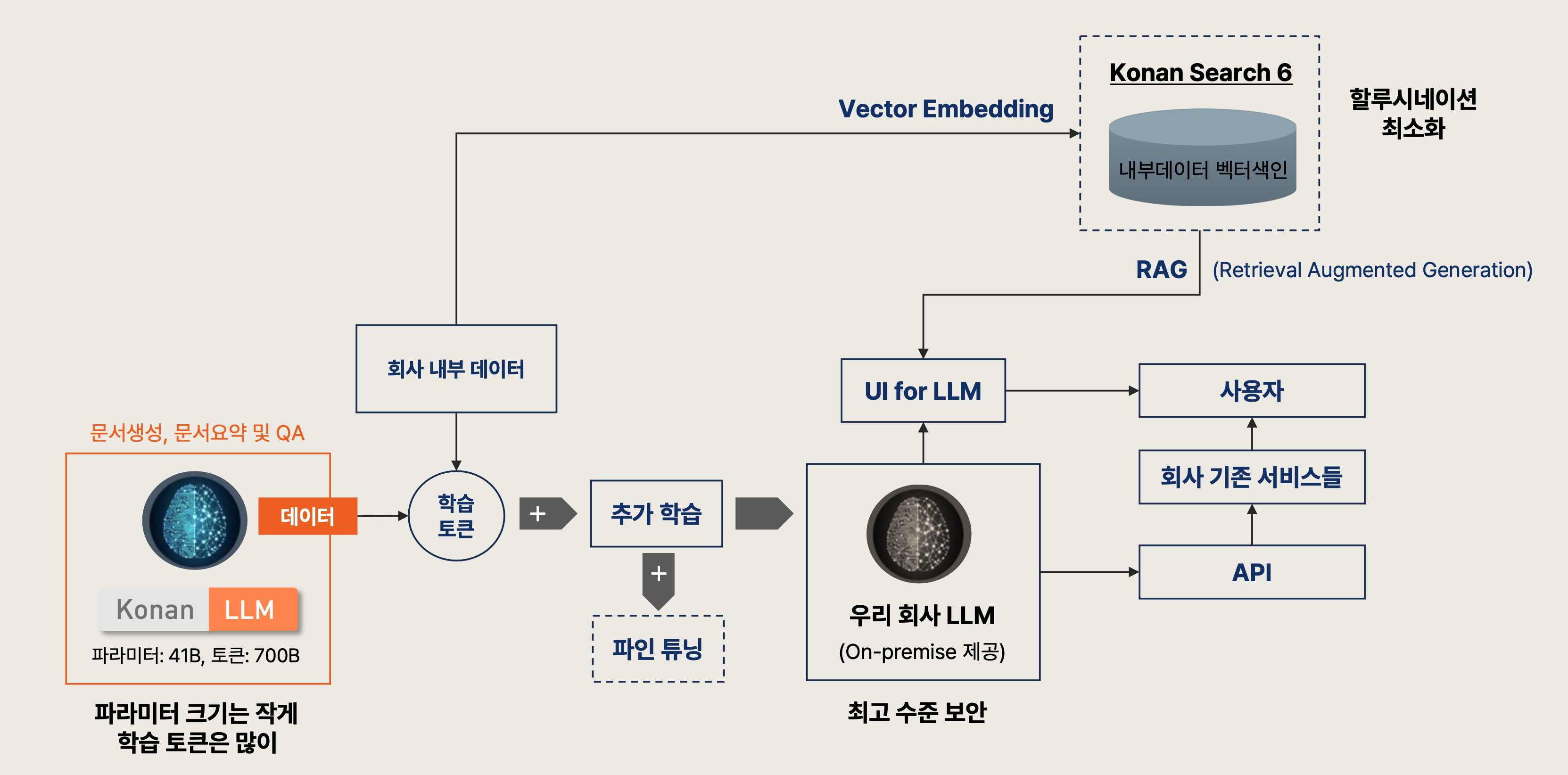
그리고 클라우드가 아닌 On-premise 방식으로 B2B 사업을 진행 중이라고 들었는데,
자체적으로 sLLM을 만들어 쓸 것이 아니라면 확실히 좋은 솔루션이 될 수 있겠구나 싶었습니다.
세션 제목과 달리 어떻게 저렇게 긴 길이의 보고서를 잘 쓸 수 있을지에 대한 내용은 거의 다뤄지지 않은 것 같아 아쉬웠습니다.
4) LLM의 미래: KGPT (AI KMS)와 sLLM 소개 (페르소나AI)
knowledge 기반의 RAG를 핵심 기술로 볼 수 있을 것 같습니다.
여러 세션에서 RAG를 강조했는데, 기존 MIPS 방식을 이용하면 실제 retrieved된 문서들이 질문에 대한 답변에 적절한지 검증할 길이 없다는 것을 문제로 지적했습니다.
그래서 요약된 정보를 graph based knowledge로 변환하는 기술이 있어 이를 활용한다고 하네요.
또한 Deep Compression을 구성하는 세 단계, Pruning -> Quantization -> Huffman Encoding에 대해서도 다루었습니다.
저도 처음 접하는 내용들이라 잘 몰랐었는데,
마지막 Huffman Encoding 대신 Knowledge Distillation 방식을 취하는 것에 대한 연구를 진행 중이라고 했습니다.
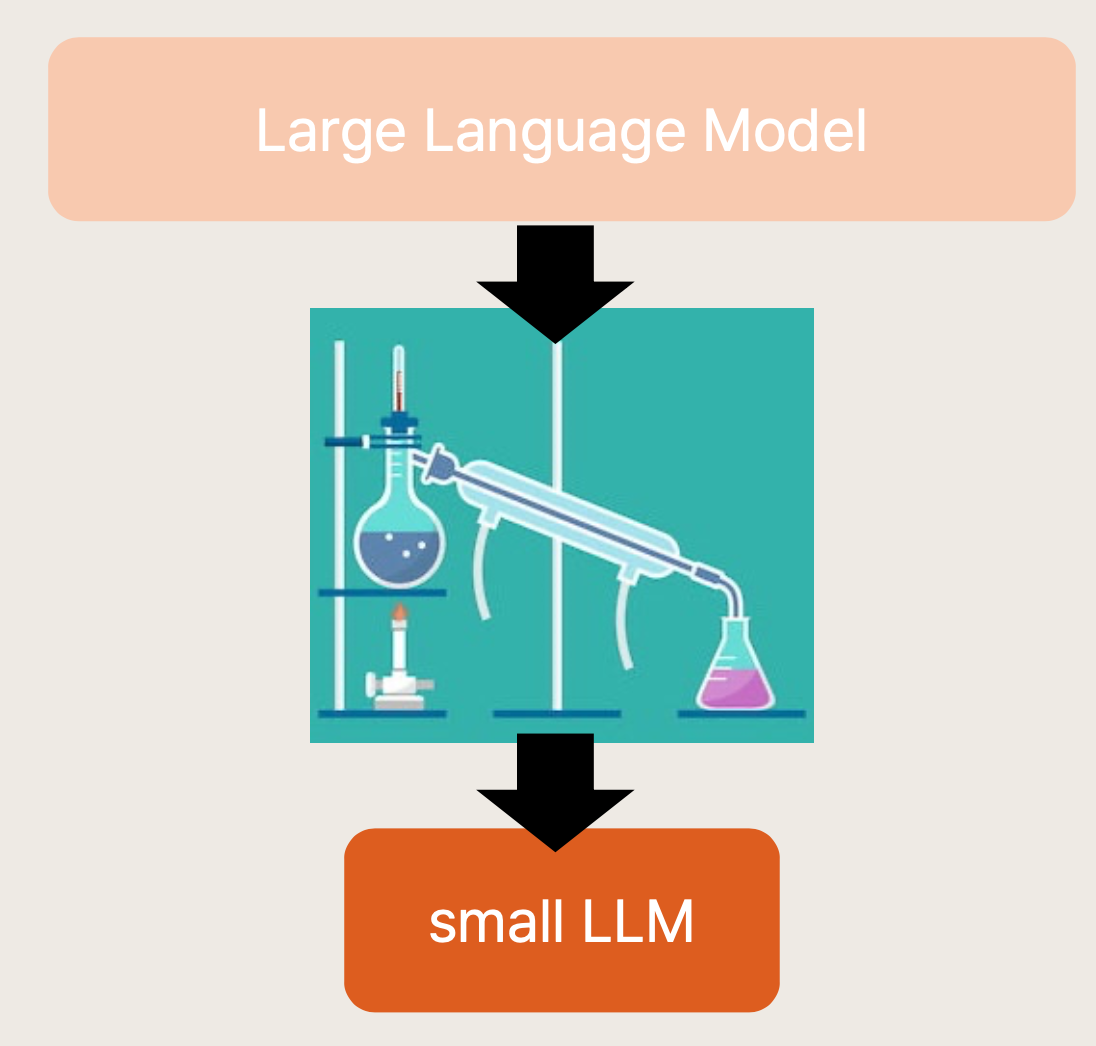
이 세션을 통해서는 알게 된 것보다 알아야 할 것들이 더욱 늘어난 듯한 기분이었습니다 🔥
5) 감성에 딱 맞는 음악을 추천하다: '사용자의 상황과 기분에 딱 맞는 AI 음악 추천 시스템' (드림어스 컴퍼니)
음악 어플 FLO에서 어떤 방식으로 음악을 추천하게 되는지에 대한 설명이 주된 내용이었습니다.
사람이 직접 플레이리스트를 만드는 것은 귀찮고.. 알아서 해줬으면 좋겠다 싶을 때가 많았죠.
저도 그래서 유튜브 뮤직을 듣고 있습니다 🎶
(한 곡만 재생해도 알아서 목록 만들어주는 것이 너무 편해서..)
기존 추천 방식은 '협업 필터링'이라고 하네요.
즉, 나와 유사한 성향을 가진 유저가 듣는 음악과 비슷한 것을 추천해주는 방식을 뜻합니다.
그러나 사람들이 듣는 대부분의 노래는 특정 곡으로 한정되는 경우가 많아 장기 사용자들의 불만이 쌓일 수밖에 없는 구조라고 하네요.
이를 해결하기 위해서, 텍스트 / 오디오 (30초 단위) 데이터를 수집하여 학습했는데, 이때도 Contrastive Learning 방식이 사용됩니다.
재밌는 것은 협업 필터링 이외에도 비슷한 음색을 추천해줄 수 있는 Content-Based filtering (CBF)이 사용된다는 점이었습니다.
또 충격적인 것은 의외로 텍스트 데이터에 '가사'가 포함되지 않는다는 것입니다.
제목이나 곡의 분위기와 상반되는 가사가 워낙 많아서 학습에 방해가 된다고 하네요 😂
개인적으로는 이 서비스가 처음 출시되었을 때 크러쉬가 나오는 광고가 참 재밌고 유쾌하게 만들어졌다고 생각했던 기억이 있어서 재밌는 세션이었던 것 같네요!
6) RAG를 위한 Retriever 전략 (Allganize)
가장 인상깊었던 것은 Document Parsing과 관련된 내용이었습니다.
Table을 모델이 어떻게 인식할 수 있을지에 대한 방법이 딱히 없는 것 같다고 느꼈는데요,
Table에 담긴 정보를 text로 변환하는 방식으로 문제를 해결했다고 합니다.
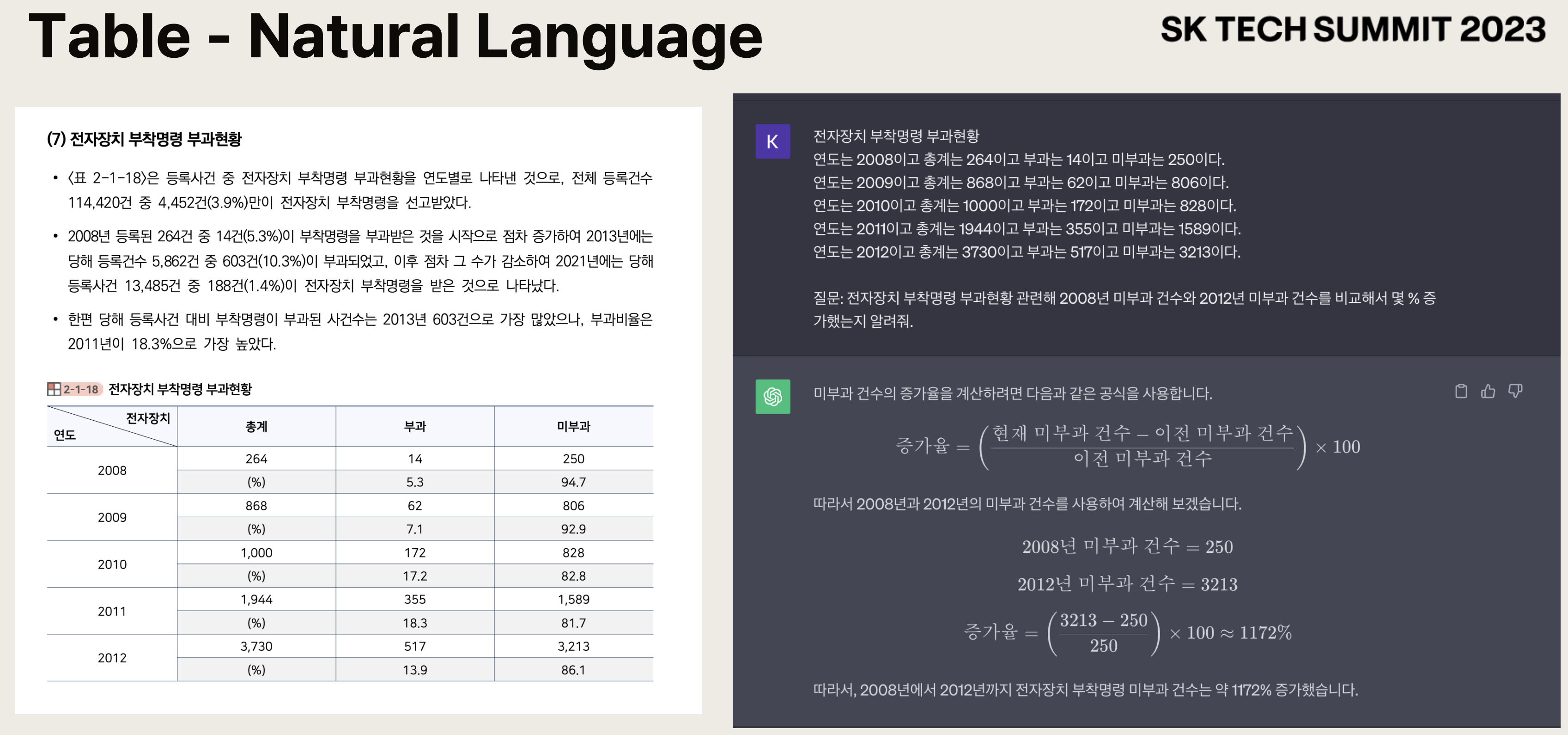
이때 이를 가로(행방향)로 읽어야 할지, 세로(열방향)로 읽어야 할지 등에 대해서는 유사도와 같은 꼼수를 쓸 수 있다고 언급하셨습니다.
예를 들어 열 별로 벡터화 한 것의 유사도가 굉장히 높다면 행으로 읽어야 한다는 뜻이다, 라고 하셨죠.
또한 Retrieve 결과를 너무 많이 가져오게 되면 비용 문제가 발생하기 때문에 top 3 또는 top 5가 적절한 것으로 보고 계신다 했습니다.
재밌었던 것은 encoder 전략입니다.
Cross-Encoder의 경우 성능은 좋지만 Latency 문제로 인해 현업에서는 고려 대상이 전혀 아니라고 했습니다.
따라서 Bi-Encoder를 사용해야 하는데, 매번 새로운 데이터를 업데이트 해줘야 하는지에 대한 문제가 있어 Question에 대해서만 학습하는 기형적인 구조가 생겨난다고 설명했습니다.
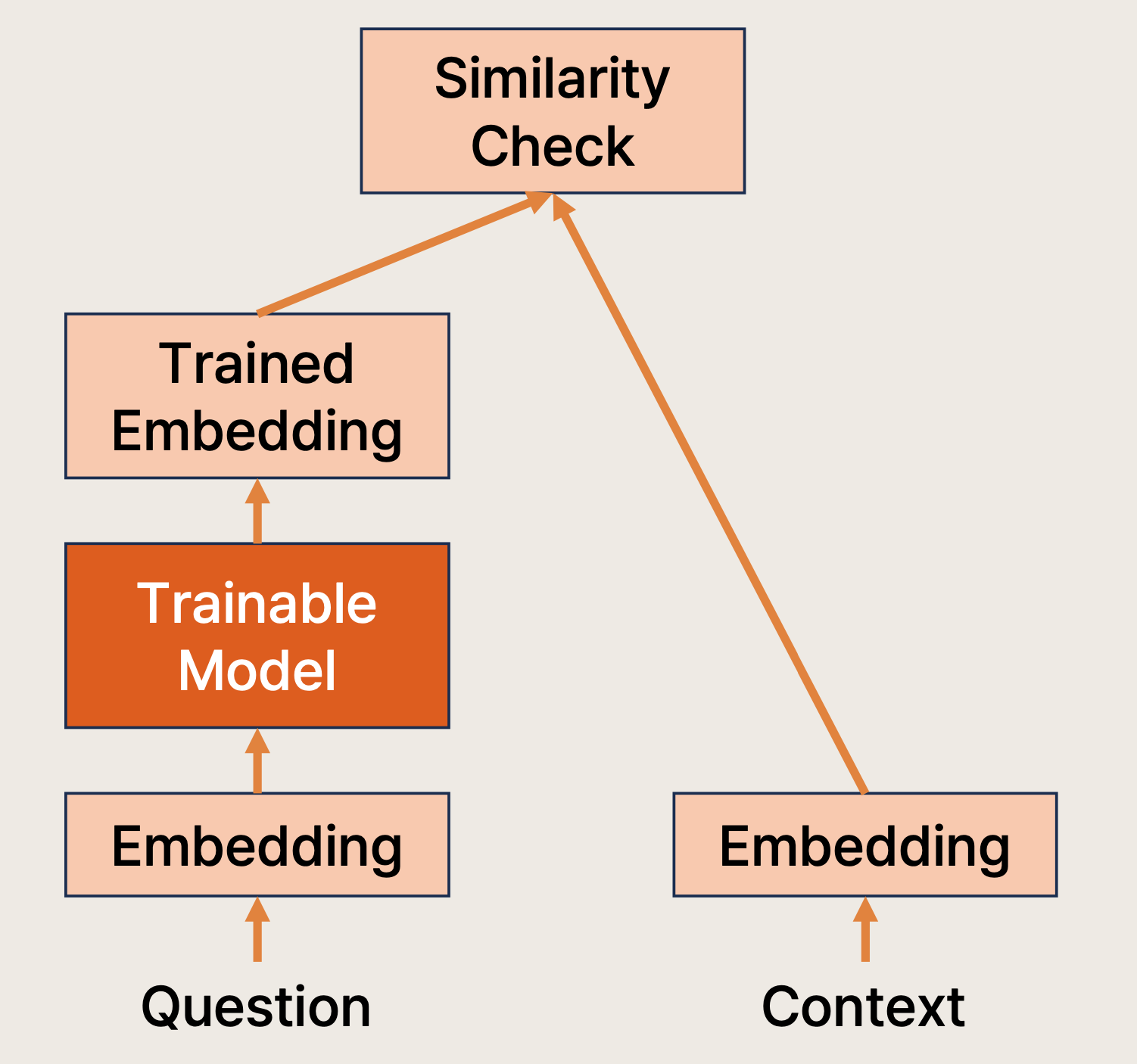
또한 Retrieve를 위해서 constrastive learning이 자주 사용되는데, 이를 위한 negative sample을 구축하는 방식에 대해서도 간단히 언급했습니다.
2. 전시 부스
이런 행사에서는 또 여러 기업들이나 부서에서 나와 자신들의 제품과 서비스가 어떤 것인지 소개하는 전시 부스를 방문하는 것이 큰 재미인 듯합니다.
생각보다 에이닷 관련 서비스가 엄청나게 많아서 놀라웠어요 😲
생중계되는 스포츠 영상 (야구)에서 핵심 클립들을 추출하고 이를 합쳐 하이라이트 영상까지 제공하는 서비스가 이미 운영중이라고 하네요..!
또 보고서 제작 관련 서비스들도 있었는데, 아직까지는 정형 데이터 위주여서 아쉽다는 의견도 있었습니다.
(다들 보고서 쓰는 것에 질려버린..ㅋㅋㅋ)
또한 시각 장애인들을 위한 어플리케이션도 성능이 굉장히 좋은 편이라 신기했습니다.
카메라로 보이는 내용들을 음성으로 들려주는 것인데 일부가 잘린 이미지에 대해서도 예측을 잘한다는 점이 돋보였던 것 같네요.
개인적으로 가장 기억에 남는 것은 A.Sleep 이었습니다!

워치에서도 관련 앱들이 없는지 한~~~참을 뒤져보고 찾던 기억이 있었는데 결국엔 만족스런 (무료) 앱을 찾지 못해 포기했던 기억이 있거든요..🥲
그런데 이 기능은 딱 '소리'만을 가지고 분석을 한다고 하네요.
솔직히 숨소리가 작거나 얌전히 자는 사람들 대상으로 이게 되나... 싶은 의문이 들긴 했는데..
설명해주시는 분 말씀으로는 1m 정도의 거리여도 충분히 탐지가 된다고 하니.. 잘 때 바로 써보려고 합니다 ㅎㅎ
(뛰어난 석박님들께서 연구하신 결과라고 하니 일단 오케이)
3. 너무 아쉬웠던 행사 운영.. 💢💢💢
아마 행사 참여하셨던 분들이라면 모~~두가 공감하셨을 것 같아요.
저는 행사 관련 홍보글을 보고 바로 사전신청을 했는데, 사전 신청을 행사 시작 전날까지 받더라고요..?
게다가 현장 등록도 가능하다고 해서 굉장히 의아했었죠 🧐

결국 현장은 수많은 사람들로 가득차 세션을 듣기가 힘들 정도였습니다 💢

아니 뭐.. 줄을 어디까지 서있는 건지 ㅋㅋㅋㅋ
첫 번째 트랙을 기다리는 줄이라고 올라온 사진인데요..
실제 세션이 진행되는 내부에는 좌우 벽에 사람들이 쫙 늘어서있고.. 중앙에는 바닥에 앉은 사람들로 가득했습니다...
그런데 밖에는 들어오고 싶은 분들이 이만큼이나 깔려있고 ㅋㅋㅋㅋ
운영진이 스스로의 인기나 세션에 대한 매력도를 과소평가했다고 해야할지...
답도 없는 숫자의 인원이 몰려 굉장히 힘들었습니다.
오후에 사람이 많이 빠지기 전까지는 어디서 뭘 듣거나 잠깐 쉬거나 하기가 너무 어려웠던 것 같네요.
지금까지 참석해봤던 행사 중 이렇게까지 불편하고 불쾌한 느낌은 처음 받아본 것 같아요..
세션도 좋고 전시 부스 설명도 마음에 들었지만 운영이 정말 너무 아쉽다는 생각이 떠나질 않더라고요.
4. 대세는 RAG, 핵심은 Data (그런데 사람을 곁들인..)
정말 여러 세션과 기술 관련 내용에서 RAG (Retrieval Augmented Generation)을 강조했습니다.
LLM이 널리 활용되는 시점에서 가장 치명적인 문제인 hallucination을 잡고, 최신 정보까지 반영할 수 있도록 하는 유용한 방법인 것이죠.
그렇다고 하더라도 이렇게 많이 다룰 줄 몰랐습니다..!
뭔가 지금 시점에, '언어 모델 모르시나요? ChatGPT 몰라요? LLM 안들어봤어요?' 라는 소리가 절로 나오는 것처럼 앞으로 RAG도 그정도의 키워드가 되려나 싶을 정도였어요.
(물론 인공지능에 관심 갖고 있다는 전제하에서요!)
그리고 데이터에 대한 중요성도 정말 많이 언급되었습니다.
문제 해결을 위한 시나리오나 방법론들은 어느 정도 확보가 된 상황인데, 이를 적용하기 위한 데이터가 없다는게 큰 문제라는 것이죠.
물론 LLM을 활용함으로써 그런 문제도 다소 해결할 수 있다는 관점이 많지만 학습에 필요한 데이터의 양이 어지간히 많다 보니 고품질의 데이터를 확보하는 것이 여러 기업이 직면한 가장 큰 문제라는 생각이 듭니다.
결국 이를 위해서는 사람이 갈려들어가서.. 고품질의 데이터셋을 확보하고..
그걸로 학습을 해보는 모험 (그렇게 만들어도 잘 안될 수 있기 때문에)을 시도해야 하는 것이죠.
문제 해결에 필요한 질 좋은 데이터를 빠르게 잘 확보하는 것이 정말 중요한 시대인 것 같네요.
5. 길 찾기 어려워...
예전에도 다른 행사로 인해 방문해봤던 곳이라 생각하고 금방 갈 줄 알았는데 길이 너무 어렵더라고요..


이유는 모르겠지만.. 처음엔 위 사진에 나타난 호텔로 가게 되어서 여기가 어디지..? 한참 헤매고 겨우 도착할 수 있었어요.
코엑스에 이미 다른 행사들도 많이 진행중이어서 더 헷갈렸던 것 같네요 ㅋㅋㅋㅋ

1층에서 QR 인증 이후 행사장을 찾아가다가 PyTorch Korea를 운영하시는 정환님을 만나 후드집업과 에코백도 받을 수 있었습니다 ㅎㅎ
(집에 와서 입어 보니 이젠 XL도 무리가... 😭)

행사 마치고 나와서 돌아가는 길에, 아침에 봤던 인터콘티넨탈 호텔을 다시 보니 이렇게 예쁘게 해두었더라고요! 🎄
벌써 크리스마스 시즌이 다 되었다니.. 참으로 마음이 불편하네요 😇
세션 관련 발표 자료는 '🔗 세션 리스트 링크'에서 다운로드 받을 수 있습니다!
'후기' 카테고리의 다른 글
| TOEIC/TEPS 동시 준비 2주 만에 955/409점 달성한 후기 (6) | 2024.03.04 |
|---|---|
| 2023년 회고록: 성장하지 못한 낙동강 오리알 🦆🥚 (7) | 2023.12.31 |
| 2023 OSSCA (오픈소스 컨트리뷰션 아카데미) 파이토치 및 파이토치 라이트닝 문서 번역 참여 후기 (0) | 2023.11.24 |
| LG Aimers 3기 오프라인 해커톤 후기(STAFF) (1) | 2023.09.18 |
| TensorFlow Korea LLM Day 후기 (23.07.13 (목)) feat. 인공지능위크 2023 (0) | 2023.07.15 |