
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Tencent AI Lab]
- noisy & irrelevant document, 그리고 unknown scenarios에 대한 RALM의 robustness를 개선한 approach, Chain-of-Noting (CoN)
- ChatGPT를 사용하여 training data 생성 후 LLaMA-2 7B 모델 학습

- 배경
- LLM의 능력을 활용하는 방법으로 외부 knowledge source를 이용하는 RAG 방식이 도입. Retrieval-Augmented Language Models (RALMs)
- Information Retrieval (IR) 시스템이 항상 신뢰도 높은 정보를 보장하지 않음
- 또한 SoTA LLM들도 여전히 fact-oriented questions을 처리할 때 hallucinate하는 경향이 뚜렷함
- 두 가지 측면에서 RALMs의 robustness를 향상시키고자 함: Noise Robustness, Unknown Robustness
- Related Works
- Retrieval-Augmented Language Models
- 외부 knowledge sources로부터의 specificity & detail을 모델에게 제공
- Robustness of RALMs: random 또는 irrelevant contexts가 QA performance에 미치는 영향
- Chain-of-X Approaches in Large Language Models (LLMs)
- 복잡한 문제를 일련의 intermediate steps으로 decompose
- 그러나 아직까지 noisy & unknown scenarios에 대한 robustness를 개선하는 연구는 이뤄지지 않음
- Retrieval-Augmented Language Models
- Contributions
- RALMs의 robustness를 향상시키는 novel methodology, Chain-of-Noting (CoN) 도입
- CoN을 위한 initial training data를 생성하기 위해 ChatGPT를 활용
- 여러 open-domain QA benchmarks에서 traditional RALMs를 능가하는 성능

- Chain-of-Note (CoN)
- retrieved documents에 대한 sequential reading notes를 생성함으로써 retrieved 문서와 query의 연관성, 그리고 추출된 정보의 정확성을 systematic evaluation
- 1) Note Design
- (a) Relevant -> Find the answer: retrieved information만으로 답을 도출할 수 있는 경우
- (b) Irrelevant -> Infer the answer: retrieved information만으로는 답을 도출하기 어려우나, context를 기반으로 inherent knowledge를 이용하여 답을 도출할 수 있는 경우
- (c) Irrelevant -> Answer Unknown: 완전히 무관한 정보만이 retrieved 되었거나 모델이 답변하기에 불충분한 지식만을 지녔을 경우
- 2) Data Collections
- NQ 벤치마크로부터 10k questions을 랜덤하게 추출
- ChatGPT를 활용하여 notes data를 생성
- 생성된 데이터의 일부(subset)에 대해 human evaluations
- 모델의 dapatability를 확인하기 위한 세 개의 추가 open-domain datasets: TriviaQA, WebQA, RealTimeQA
- 3) Model Training
- instruction, question, documents를 concatenate하여 prompt로 만듦
- in-house LLaMA-2 7B 모델은 standard supervised 방식으로 notes & answer를 생성하도록 학습
- Weighted Loss on Notes and Answers: 학습 시간 50%는 entire notes & answer sequence에 대한 loss를 계산하고, 나머지 50%는 answer에 대해서만 loss를 계산
- Baseline
- LLaMA-2 w/o IR, DPR + LLaMA-2, DPR + LLaMA-2 with Chain-of-Note
- Metrics
- Exact Match (EM), F1 score, Reject Rate (RR)
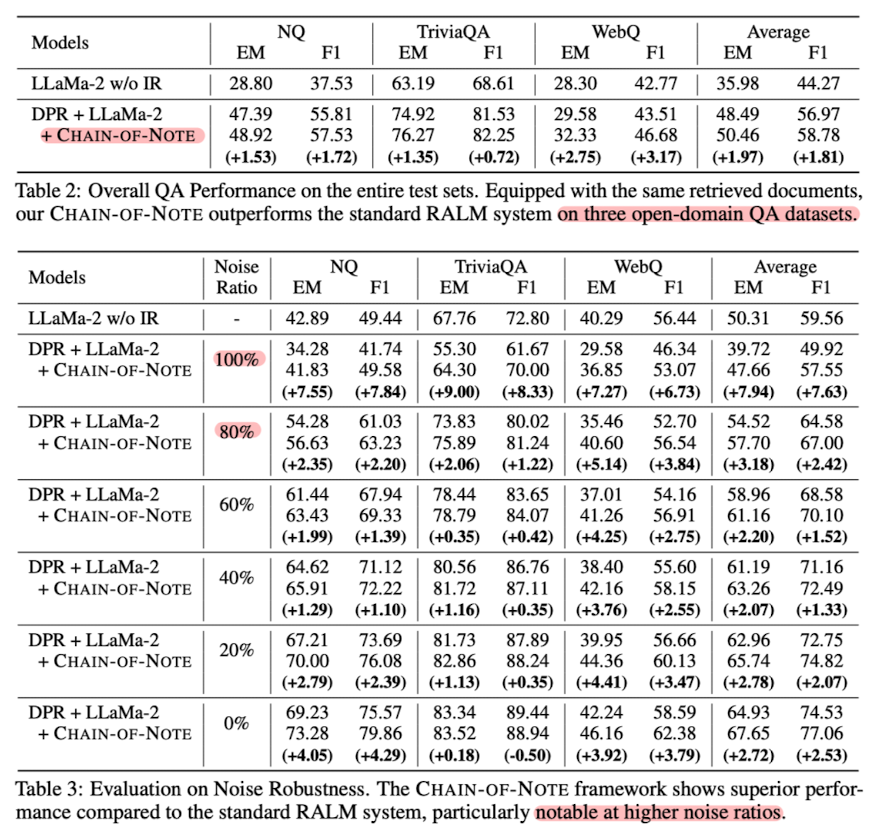
- Results
- 여러 open-domain QA에 대해서 CoN을 적용한 것이 가장 좋은 성능을 보이는 것으로 확인
- Noise Robustness 확인 결과, random document를 noise로 사용하는 것이 retrieval을 통해 획득한 document를 noise로 사용하는 것보다 더 robust
- Unknown Robustenss에서 (특히 RealTimeQA) 우수한 성능을 보임
출처 : https://arxiv.org/abs/2311.09210
Chain-of-Note: Enhancing Robustness in Retrieval-Augmented Language Models
Retrieval-augmented language models (RALMs) represent a substantial advancement in the capabilities of large language models, notably in reducing factual hallucination by leveraging external knowledge sources. However, the reliability of the retrieved info
arxiv.org
'Paper Review' 카테고리의 다른 글
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Tencent AI Lab]
- noisy & irrelevant document, 그리고 unknown scenarios에 대한 RALM의 robustness를 개선한 approach, Chain-of-Noting (CoN)
- ChatGPT를 사용하여 training data 생성 후 LLaMA-2 7B 모델 학습
- 배경
- LLM의 능력을 활용하는 방법으로 외부 knowledge source를 이용하는 RAG 방식이 도입. Retrieval-Augmented Language Models (RALMs)
- Information Retrieval (IR) 시스템이 항상 신뢰도 높은 정보를 보장하지 않음
- 또한 SoTA LLM들도 여전히 fact-oriented questions을 처리할 때 hallucinate하는 경향이 뚜렷함
- 두 가지 측면에서 RALMs의 robustness를 향상시키고자 함: Noise Robustness, Unknown Robustness
- Related Works
- Retrieval-Augmented Language Models
- 외부 knowledge sources로부터의 specificity & detail을 모델에게 제공
- Robustness of RALMs: random 또는 irrelevant contexts가 QA performance에 미치는 영향
- Chain-of-X Approaches in Large Language Models (LLMs)
- 복잡한 문제를 일련의 intermediate steps으로 decompose
- 그러나 아직까지 noisy & unknown scenarios에 대한 robustness를 개선하는 연구는 이뤄지지 않음
- Retrieval-Augmented Language Models
- Contributions
- RALMs의 robustness를 향상시키는 novel methodology, Chain-of-Noting (CoN) 도입
- CoN을 위한 initial training data를 생성하기 위해 ChatGPT를 활용
- 여러 open-domain QA benchmarks에서 traditional RALMs를 능가하는 성능
- Chain-of-Note (CoN)
- retrieved documents에 대한 sequential reading notes를 생성함으로써 retrieved 문서와 query의 연관성, 그리고 추출된 정보의 정확성을 systematic evaluation
- 1) Note Design
- (a) Relevant -> Find the answer: retrieved information만으로 답을 도출할 수 있는 경우
- (b) Irrelevant -> Infer the answer: retrieved information만으로는 답을 도출하기 어려우나, context를 기반으로 inherent knowledge를 이용하여 답을 도출할 수 있는 경우
- (c) Irrelevant -> Answer Unknown: 완전히 무관한 정보만이 retrieved 되었거나 모델이 답변하기에 불충분한 지식만을 지녔을 경우
- 2) Data Collections
- NQ 벤치마크로부터 10k questions을 랜덤하게 추출
- ChatGPT를 활용하여 notes data를 생성
- 생성된 데이터의 일부(subset)에 대해 human evaluations
- 모델의 dapatability를 확인하기 위한 세 개의 추가 open-domain datasets: TriviaQA, WebQA, RealTimeQA
- 3) Model Training
- instruction, question, documents를 concatenate하여 prompt로 만듦
- in-house LLaMA-2 7B 모델은 standard supervised 방식으로 notes & answer를 생성하도록 학습
- Weighted Loss on Notes and Answers: 학습 시간 50%는 entire notes & answer sequence에 대한 loss를 계산하고, 나머지 50%는 answer에 대해서만 loss를 계산
- Baseline
- LLaMA-2 w/o IR, DPR + LLaMA-2, DPR + LLaMA-2 with Chain-of-Note
- Metrics
- Exact Match (EM), F1 score, Reject Rate (RR)
- Results
- 여러 open-domain QA에 대해서 CoN을 적용한 것이 가장 좋은 성능을 보이는 것으로 확인
- Noise Robustness 확인 결과, random document를 noise로 사용하는 것이 retrieval을 통해 획득한 document를 noise로 사용하는 것보다 더 robust
- Unknown Robustenss에서 (특히 RealTimeQA) 우수한 성능을 보임
출처 : https://arxiv.org/abs/2311.09210
Chain-of-Note: Enhancing Robustness in Retrieval-Augmented Language Models
Retrieval-augmented language models (RALMs) represent a substantial advancement in the capabilities of large language models, notably in reducing factual hallucination by leveraging external knowledge sources. However, the reliability of the retrieved info
arxiv.org