
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Alibaba, Singapore University]
- 다른 source로부터의 정부를 dynamically incorporating 함으로써 LLM을 augment하는 framework, Chain-of-Knolwedge (CoK)
- CoK는 구조화된 Wikidata나 table 같은 knowledge source도 이용 가능
1. Introduction
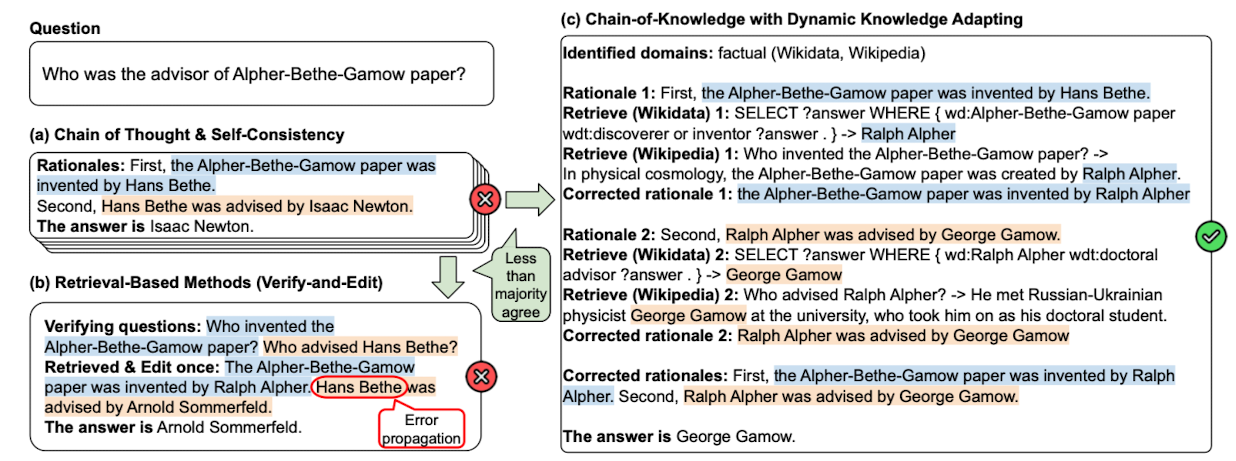
- hallucination 현상과 updated factual knowledge를 반영하지 못하는 것이 LLM의 단점으로 제기되어 왔음
- 이를 해결하기 위해 external knowledge를 방식이나 CoT reasoning 등을 활용
- 그러나 아직까지 1) fixed knowledge source만을 이용 2) retrieval query 생성이 전적으로 LLM에 의존 3) progressive corretion capability 부족, 문제를 겪는 중
2. Realted Works
- Knowledge-Intensive NLP
- 현실 세계에서는 local context를 넘어서는 지식이 요구됨
- 이에 대처하기 위해 retriever-reader system 등이 도입되었음
- Augmented Language Models (ALM)
- 그럴싸해 보이지만 사실이 아닌 출력을 반환하는 hallucination, 그리고 specialized domain expertise에 대한 약점 등을 극복하기 위해 ALM이 도입
3. Contributions
- heterogeneous knowledge source로부터 LLM factual correctness를 향상시키는 프레임워크, Chain-of-Knolwedge (CoK) 제시
- 각 knowledge source에 맞는 query를 생성해주는 Adaptive Query Generator (AQG)를 제안
- CoK는 rationale을 progressively correct하기 때문에 부정확한 정보가 propagate 되는 현상을 최소화 할 수 있음
- 여러 도메인에 걸친 knowledge-intensive task에 대해 실험을 수행함으로써 CoK의 효용을 입증
4. The Chain-of-Knowledge Framework
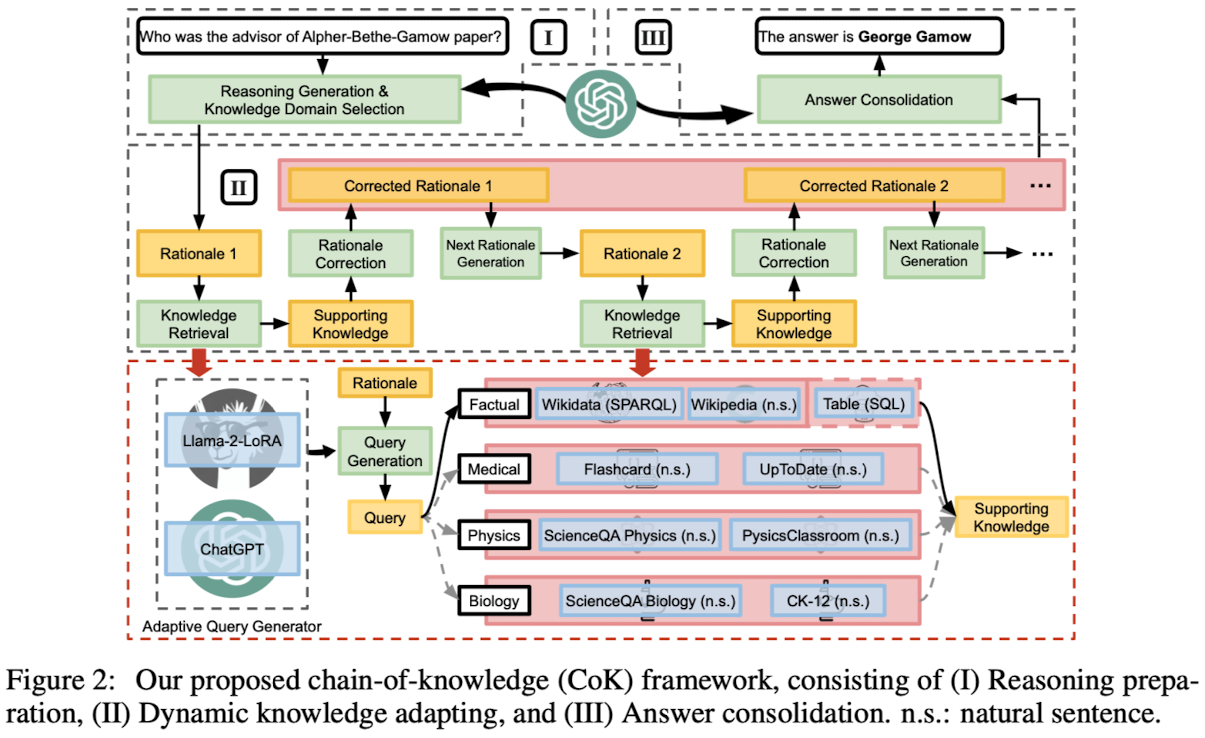
4.1. Reasoning Preparation Stage
- Reasoning Generation
- few-shot chain-of-thought (CoT) prompting 사용
- self-consistency method 활용
- Knowledge Domain Selection
- question과 가장 pertinent knowledge를 retrieve하기 위한 과정
- 4개의 knowledge domains: factual, medical, physics, biology
- 여러 개의 domain이 한 개의 question 답변에 활용될 수 있음
4.2. Dynamic Knowledge Adapting Stage
- Knowledge Retrieval
- Query Generation
- 각 source에 적합한 query language를 연결
- Wikidata는 SPARQL, flashcard는 natural sentence query
- structured & unstructured queries 둘 다 생성할 수 있도록 Adapative Query Generator (AQG)가 사용됨
- Query Execution
- 각 query 종류에 따라 query가 실행
- SPARQL query의 경우 wikidata.org의 API를 활용, natural sentence queries의 경우 sentence similarity matching을 활용 등
- Query Generation
- Rationale Correction
- 사실에 위배되는 내용을 수정함으로써 error propagation을 방지
- Next Rationale Generation
- question과 수정된 rationale을 사용하여 다음 rationale을 생성
4.3. Answer Consolidation Stage
LLM은 question과 corrected rationale을 바탕으로 consolidated answer를 생성하도록 prompted
5. The Adaptive Query Generator (AQG)
5.1. Unstructured Query Languages
- general factual knowledge sources
- Wikipedia
- ChatGPT
- domain-specific knowledge sources,
- Flashcard, ScienceQA Physics, ScienceQA Biology
- LLaMA-2-7B, LoRA
5.2. Structured Query Languages
- commonly used query languages
- SQL
- ChatGPT
- less common languages
- SPARQL
- LLaMA-2-7B, LoRA, instruction-tune
6. Experiments
- Model & Baseline
- reasoning preparation & consolidatoin 생성에는 ChatGPT (gpt-3.5-turbo-0613)를 사용
- Standard prompting (Standard), Chain-of-thought (CoT), CoT with self-consistency (CoT-SC), Verify-Edit (VE), ReACT
- Knowledge Sources
- factual: Wikidata, Wikipedia, Wikitables
- medical: medical Flashcard, UpToDate
- physics: ScienceQA Physics, PhysicsClassroom
- biology: ScienceQA Biology, CK-12
- Benchmarks
- FEVER, HotpotQA, FeTaQA, MedMCQA, MMLU
- Results
- CoK가 CoT를 outperform, CoK는 다른 retrieval-based 방식보다도 뛰어남
- 적당한 demonstrations이 중요. 3-shot이 적당한 것으로 확인됨
- 문제를 풀기 위해 여러 개의 domain을 활용하는 것이 성능 향상에 도움이 됨
- 각 도메인에 대해서도 source의 개수를 늘리는 것이 유의미한 성능 향상으로 이어짐
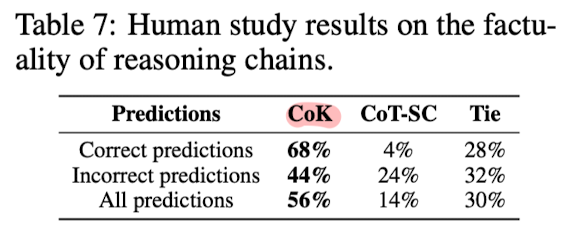
- CoK의 결과물을 옳은 것 50개, 틀린 것 50개를 추출하여 human evaluate한 결과, CoT-SC 대비 압도적으로 타당한 방식이라는 결과가 확인됨

7. 개인적 감상
이런 식의 접근은 verify하는 것과 유사하기 때문에 굉장히 신선한 것이라고 느껴지지는 않았음.
다만 특정 도메인에 대한 한계를 극복하기 위해 적용해보기 좋은 방식이라고 생각함.
가장 중요한 포인트는 structured data를 처리하는 방법이라고 느꼈음.
보통 structured data는 일반 텍스트와 달리 다뤄지지 않거나, 처리하더라도 좋은 결과로 이어지지 못하는 경우가 많은데 여기서는 효율적인 방식을 잘 취했다는 생각이 듦.
단, 특정 도메인에 너무 한정된 방식이라 scalable하지 않다는 생각이 들었음.
위에서 한정한 도메인 네 가지 자체가 대표적인 것이라고 할 수도 있겠지만 이를 벗어나는 것들에 대해서는 어떻게 대응할 수 있을지에 대해서는 전혀 고려되지 않은 듯함.
개인적으로는 RAG 방식과 결합되면 이러한 문제점을 다소 완화할 수 있을 것으로 생각함
출처 : https://arxiv.org/abs/2305.13269
Chain-of-Knowledge: Grounding Large Language Models via Dynamic Knowledge Adapting over Heterogeneous Sources
We present chain-of-knowledge (CoK), a novel framework that augments large language models (LLMs) by dynamically incorporating grounding information from heterogeneous sources. It results in more factual rationales and reduced hallucination in generation.
arxiv.org
'Paper Review' 카테고리의 다른 글
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Alibaba, Singapore University]
- 다른 source로부터의 정부를 dynamically incorporating 함으로써 LLM을 augment하는 framework, Chain-of-Knolwedge (CoK)
- CoK는 구조화된 Wikidata나 table 같은 knowledge source도 이용 가능
1. Introduction
- hallucination 현상과 updated factual knowledge를 반영하지 못하는 것이 LLM의 단점으로 제기되어 왔음
- 이를 해결하기 위해 external knowledge를 방식이나 CoT reasoning 등을 활용
- 그러나 아직까지 1) fixed knowledge source만을 이용 2) retrieval query 생성이 전적으로 LLM에 의존 3) progressive corretion capability 부족, 문제를 겪는 중
2. Realted Works
- Knowledge-Intensive NLP
- 현실 세계에서는 local context를 넘어서는 지식이 요구됨
- 이에 대처하기 위해 retriever-reader system 등이 도입되었음
- Augmented Language Models (ALM)
- 그럴싸해 보이지만 사실이 아닌 출력을 반환하는 hallucination, 그리고 specialized domain expertise에 대한 약점 등을 극복하기 위해 ALM이 도입
3. Contributions
- heterogeneous knowledge source로부터 LLM factual correctness를 향상시키는 프레임워크, Chain-of-Knolwedge (CoK) 제시
- 각 knowledge source에 맞는 query를 생성해주는 Adaptive Query Generator (AQG)를 제안
- CoK는 rationale을 progressively correct하기 때문에 부정확한 정보가 propagate 되는 현상을 최소화 할 수 있음
- 여러 도메인에 걸친 knowledge-intensive task에 대해 실험을 수행함으로써 CoK의 효용을 입증
4. The Chain-of-Knowledge Framework
4.1. Reasoning Preparation Stage
- Reasoning Generation
- few-shot chain-of-thought (CoT) prompting 사용
- self-consistency method 활용
- Knowledge Domain Selection
- question과 가장 pertinent knowledge를 retrieve하기 위한 과정
- 4개의 knowledge domains: factual, medical, physics, biology
- 여러 개의 domain이 한 개의 question 답변에 활용될 수 있음
4.2. Dynamic Knowledge Adapting Stage
- Knowledge Retrieval
- Query Generation
- 각 source에 적합한 query language를 연결
- Wikidata는 SPARQL, flashcard는 natural sentence query
- structured & unstructured queries 둘 다 생성할 수 있도록 Adapative Query Generator (AQG)가 사용됨
- Query Execution
- 각 query 종류에 따라 query가 실행
- SPARQL query의 경우 wikidata.org의 API를 활용, natural sentence queries의 경우 sentence similarity matching을 활용 등
- Query Generation
- Rationale Correction
- 사실에 위배되는 내용을 수정함으로써 error propagation을 방지
- Next Rationale Generation
- question과 수정된 rationale을 사용하여 다음 rationale을 생성
4.3. Answer Consolidation Stage
LLM은 question과 corrected rationale을 바탕으로 consolidated answer를 생성하도록 prompted
5. The Adaptive Query Generator (AQG)
5.1. Unstructured Query Languages
- general factual knowledge sources
- Wikipedia
- ChatGPT
- domain-specific knowledge sources,
- Flashcard, ScienceQA Physics, ScienceQA Biology
- LLaMA-2-7B, LoRA
5.2. Structured Query Languages
- commonly used query languages
- SQL
- ChatGPT
- less common languages
- SPARQL
- LLaMA-2-7B, LoRA, instruction-tune
6. Experiments
- Model & Baseline
- reasoning preparation & consolidatoin 생성에는 ChatGPT (gpt-3.5-turbo-0613)를 사용
- Standard prompting (Standard), Chain-of-thought (CoT), CoT with self-consistency (CoT-SC), Verify-Edit (VE), ReACT
- Knowledge Sources
- factual: Wikidata, Wikipedia, Wikitables
- medical: medical Flashcard, UpToDate
- physics: ScienceQA Physics, PhysicsClassroom
- biology: ScienceQA Biology, CK-12
- Benchmarks
- FEVER, HotpotQA, FeTaQA, MedMCQA, MMLU
- Results
- CoK가 CoT를 outperform, CoK는 다른 retrieval-based 방식보다도 뛰어남
- 적당한 demonstrations이 중요. 3-shot이 적당한 것으로 확인됨
- 문제를 풀기 위해 여러 개의 domain을 활용하는 것이 성능 향상에 도움이 됨
- 각 도메인에 대해서도 source의 개수를 늘리는 것이 유의미한 성능 향상으로 이어짐
- CoK의 결과물을 옳은 것 50개, 틀린 것 50개를 추출하여 human evaluate한 결과, CoT-SC 대비 압도적으로 타당한 방식이라는 결과가 확인됨
7. 개인적 감상
이런 식의 접근은 verify하는 것과 유사하기 때문에 굉장히 신선한 것이라고 느껴지지는 않았음.
다만 특정 도메인에 대한 한계를 극복하기 위해 적용해보기 좋은 방식이라고 생각함.
가장 중요한 포인트는 structured data를 처리하는 방법이라고 느꼈음.
보통 structured data는 일반 텍스트와 달리 다뤄지지 않거나, 처리하더라도 좋은 결과로 이어지지 못하는 경우가 많은데 여기서는 효율적인 방식을 잘 취했다는 생각이 듦.
단, 특정 도메인에 너무 한정된 방식이라 scalable하지 않다는 생각이 들었음.
위에서 한정한 도메인 네 가지 자체가 대표적인 것이라고 할 수도 있겠지만 이를 벗어나는 것들에 대해서는 어떻게 대응할 수 있을지에 대해서는 전혀 고려되지 않은 듯함.
개인적으로는 RAG 방식과 결합되면 이러한 문제점을 다소 완화할 수 있을 것으로 생각함
출처 : https://arxiv.org/abs/2305.13269
Chain-of-Knowledge: Grounding Large Language Models via Dynamic Knowledge Adapting over Heterogeneous Sources
We present chain-of-knowledge (CoK), a novel framework that augments large language models (LLMs) by dynamically incorporating grounding information from heterogeneous sources. It results in more factual rationales and reduced hallucination in generation.
arxiv.org