
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Naver Clova, KAIST AI]
- 여러 턴의 대화 중에서도 유저에 대한 최신 정보를 잘 불러오는 long term conversations을 위한 데이터셋 구축
- 불필요하거나 더이상 쓸모가 없어진 memory는 삭제하는 방식으로 long term conversation을 효과적으로 유지

- Backgrounds
- human interaction의 관점에서 memory는 대화를 유지하기 위해 가장 중요한 메커니즘 중 하나
- 그러나 효과적으로 memory를 관리하거나 업데이트하는 것이 쉽지 않은 상황
- Related Works
- Personalized Dialogue System: dialogue history로부터 user profile을 직접적으로 추출하는 것이 대세
- Long-term Memory in Conversation: 구조화되지 않은 텍스트 데이터를 memory로 사용하려는 시도가 이뤄졌음
- Contributions
- 정보를 최신으로 유지하는 dynamic memory를 이용해 long-term donversation을 적절히 수행
- 구조화되지 않은 텍스트 형식에 대한 novel memory management mechanism을 제시
- 최초의 Korean long-term dialogue dataset 공개
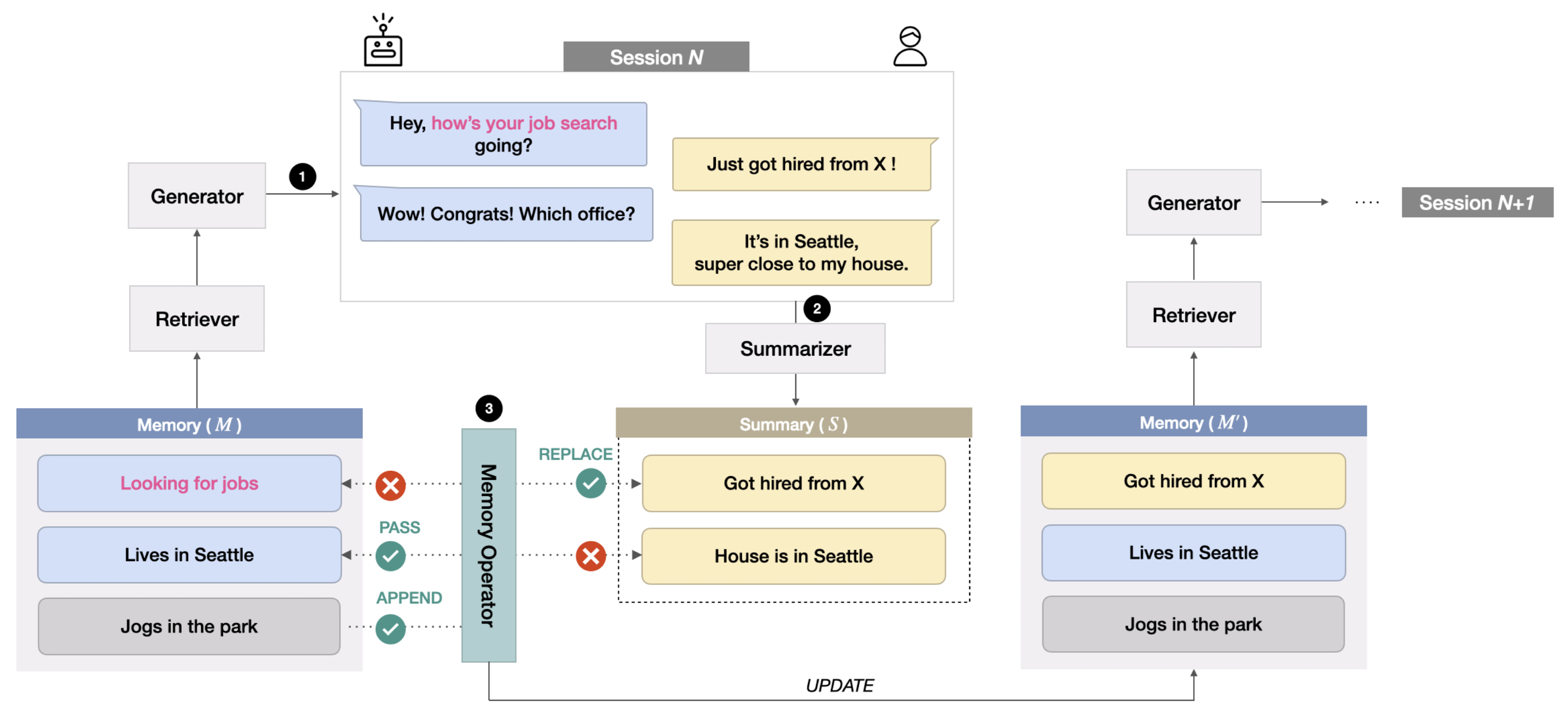
- Dataset Construction
- CareCall dataset 기반으로 multi-session setting
- Dialogue Summary: 15 turn 이상의 데이터 600개를 추출하여 모델을 학습
- 모델은 HyperCLOVA 6.9B를 backbone으로 사용했고 P(S | D) 방식으로 fine-tune
- 이때 D는 chatbot과 user의 발화를 담은 Dialogue, S는 각 세션마다 D를 요약한 데이터
- Memory Grounded Dialogue
- 이전 memory (M)가 주어졌을 때 dialogue를 생성하도록 모델 학습 진행. P(D | M)
- Model & Algorithm
- 모델 학습은 dialogue와 memory가 주어졌을 때, chatbot이 생성하는 utterance의 오차를 줄이는 방향으로 진행
- 이때 사용되는 backbone 모델은 Hyper-CLOVA 6.9B을 사용
- Memory Retrieval은 context persona matching (CPM) 을 사용
- Dialogue Summarzation에도 HyperCLOVA 6.9B 모델이 사용됨
- Memory Update는 Pass (P), Relpace (R), Append (A), Delete (D) 중 하나를 선택하는 방식


- Results
- From scratch, NLI zero-shot, NLI transfer (fine-tune) 세 방식으로 비교
- NLI transfer 방식이 가장 좋은 성능을 보임

출처 : https://arxiv.org/abs/2210.08750
Keep Me Updated! Memory Management in Long-term Conversations
Remembering important information from the past and continuing to talk about it in the present are crucial in long-term conversations. However, previous literature does not deal with cases where the memorized information is outdated, which may cause confus
arxiv.org