
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[LK Lab, KAIST]
- prompt를 LM의 파라미터에 주입하는 방식, Prompt Injection (PI)를 제안
- novel distillation approach, Pseudo-INput Generation (PING)를 제안
- prompt를 input에 prepend하는 기존 방식 대비 우수한 성능 달성
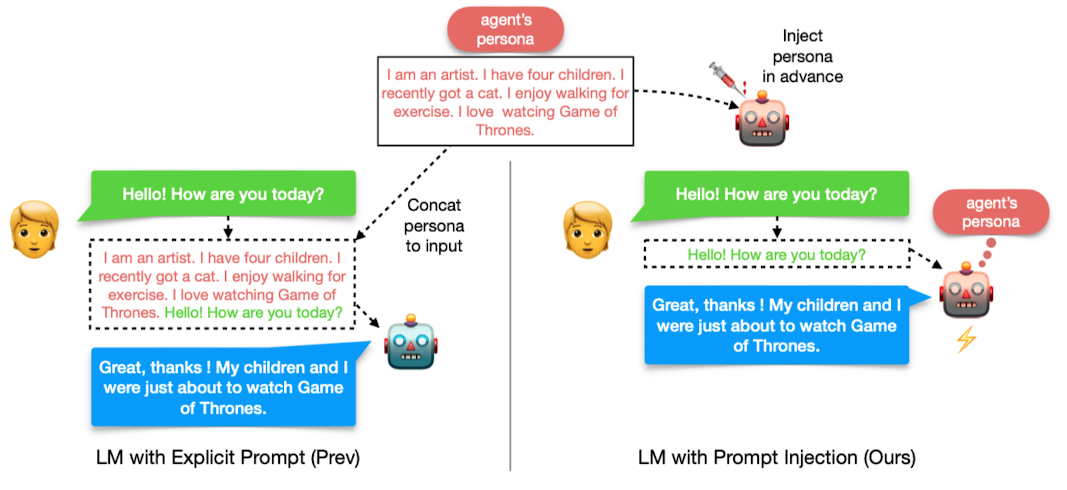
- 배경
- input에 prompt를 attach함으로써(prefixes) LM을 특정 태스크에 맞게 조정하는 것이 가능
- 그러나 이처럼 prompt와 input을 단순 concatenate하는 prompt-dependent 방식은 두 가지 한계가 존재
- 1) 추론 단계에서 너무 많은 computational & memory overhead를 초래
- 2) 입력 sequence의 길이에 제한이 있는 transformer 기반 모델에 detailed description과 같은 long text를 제공하는 것의 난이도가 높음
- Related Works
- Prompting: few-shot & zero-shot learning
- Efficient Transformers for Long Inputs: 기존 transformer는 time & memory 관점에서 quadratic cost 발생
- Persona-dependent Conversation: 챗봇에 persona를 부여하는 것이 대화 품질을 향상시키지만 쉽지는 않음
- Semantic Parsing: 자연어 query를 데이터 베이스에 적용 가능한 SQL query에 매핑하는 등의 방법
- Zero-shot Learning with Task Instructions: multi-task prompted training을 통해 모델의 일반화 성능을 향상시킬 수 있음
- Contributions
- long prompts가 주어지는 scenarios에서 computation & memory efficient한 방법 Prompt Injection (PI)를 제시
- 일부 케이스에서 PI의 성능이 상한선(unconstrained) 수준에 이르는 것을 확인
- long prompts를 모델에 injection하는 것이 PI를 통해 달성될 수 있음을 확인
- Prompt Injection
- 기존: 프롬프트 z, 입력 시퀀스 x를 합쳐 y를 반환하는 LM은 f로 표시 -> 기존 방식 대신에 프롬프트 z를 LM에 inject하는 방식
- 프롬프트 z를 여러 sub-프롬프트로 쪼개어 반복적으로 PI process를 진행 (multiple epochs)
- 프롬프트가 LM에 한 번 injected되면 추론 단계에서 해당 프롬프트를 입력 시퀀스에 반복적으로 붙여줄 필요가 없음
- 성능을 평가하는 PI score는 min-max scaling을 통해 획득
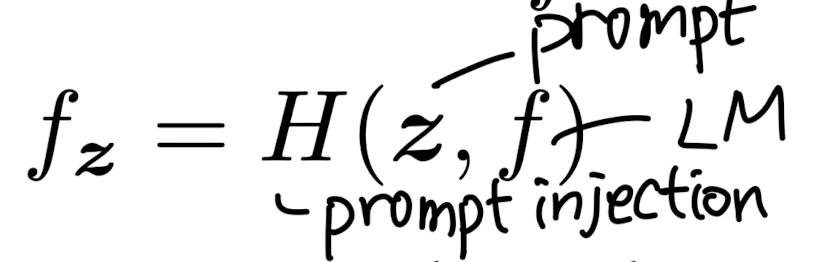
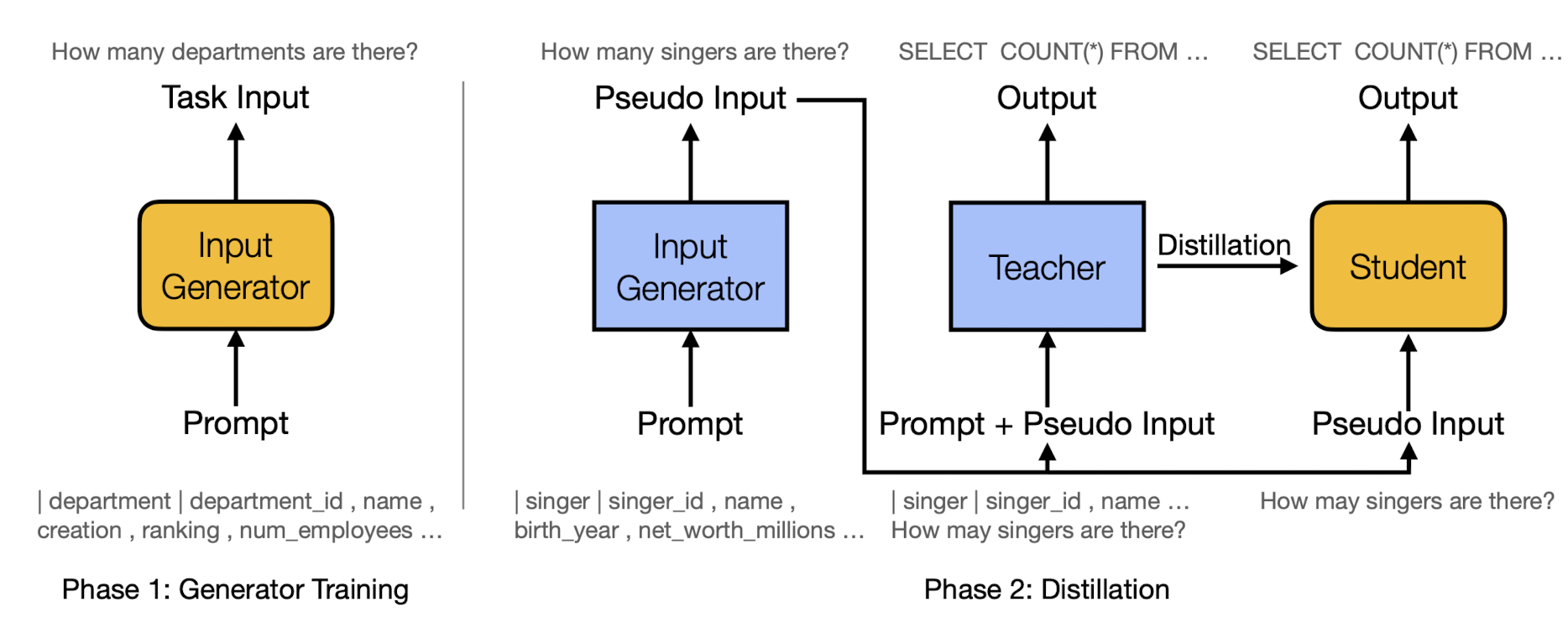
- Method for Prompt Injection
- Continued Pre-training: target prompt에 대해 LM의 기존 objective를 유지하여 추가 학습
- Curriculumn Learning: 이때 mask의 비율을 난이도로 판단하고 점진적으로 난이도를 높이는 방식으로 학습
- PING
- 1) input generator가 task-specific 학습 데이터를 생성
- 2) input generator는 frozen하여 unseen prompts로부터 pseudo-inputs을 생성. 이는 프롬프트와 함께 teacher model에 주어지고, puseduo-inputs은 student 모델에 전달
- Datasets
- Persona-Chat, Spider, WSC / RTE / COPA
- Baseline
- T5, Fusion-in-Decoder (FiD), Linear Transformer
- Results
- Inference Efficiency: PI는 prompt 길이에 독립적이라 효율적임. FLOP 기준 최대 280배 효율적
- Model Performance: 방법론별 모델 성능은 입력 시퀀스의 복잡도에 달려 있음
- Long Prompts Injection: 13,000 토큰이 되는 위키피디아 문서를 제대로 이해한 결과를 cherry picking하여 제시
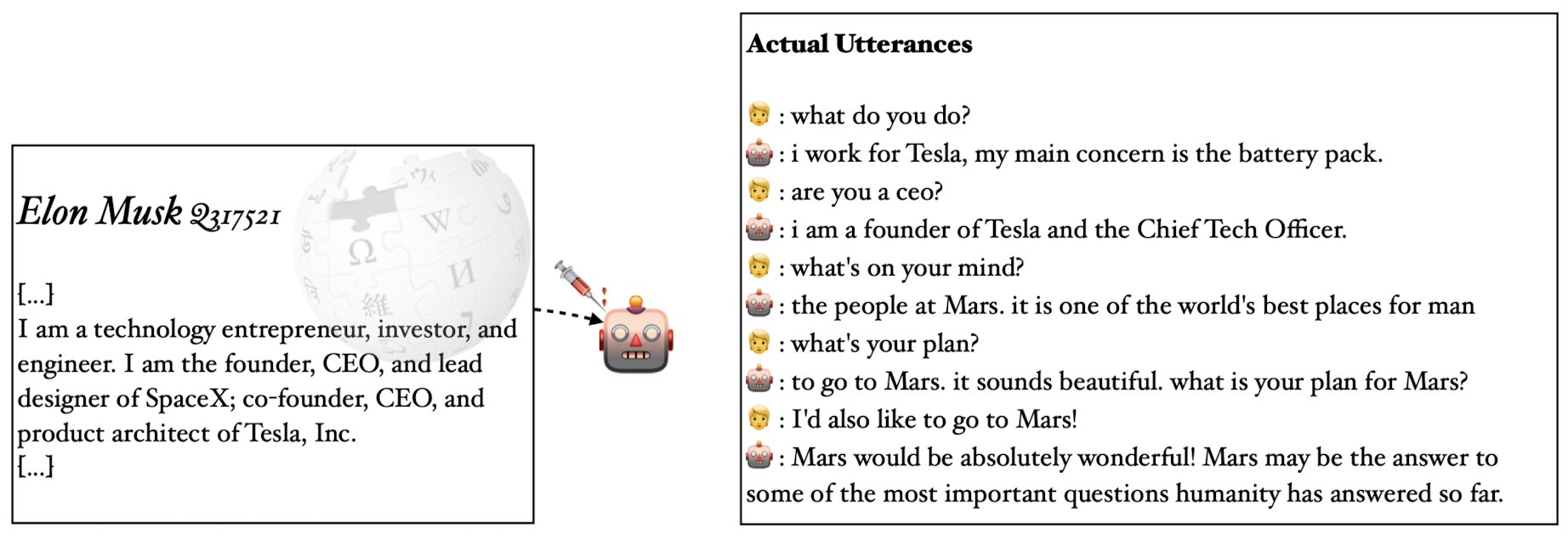
- 개인적 감상
- transformer 기반의 모델들이 지닌 한계를 극복하는 참신한 시도인 것 같으나 완전히 고정된 프롬프트를 주입시켜 놓은 것이라 일반화 성능이 많이 부족할 것 같다는 의문이 바로 드는 방식..
- cherry picking한 케이스를 제외하면 확실히 결과물이 아쉬울 것 같다는 느낌이 듦
Prompt Injection: Parameterization of Fixed Inputs
Recent works have shown that attaching prompts to the input is effective at conditioning Language Models (LM) to perform specific tasks. However, prompts are always included in the input text during inference, thus incurring substantial computational and m
arxiv.org
'Paper Review' 카테고리의 다른 글
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[LK Lab, KAIST]
- prompt를 LM의 파라미터에 주입하는 방식, Prompt Injection (PI)를 제안
- novel distillation approach, Pseudo-INput Generation (PING)를 제안
- prompt를 input에 prepend하는 기존 방식 대비 우수한 성능 달성
- 배경
- input에 prompt를 attach함으로써(prefixes) LM을 특정 태스크에 맞게 조정하는 것이 가능
- 그러나 이처럼 prompt와 input을 단순 concatenate하는 prompt-dependent 방식은 두 가지 한계가 존재
- 1) 추론 단계에서 너무 많은 computational & memory overhead를 초래
- 2) 입력 sequence의 길이에 제한이 있는 transformer 기반 모델에 detailed description과 같은 long text를 제공하는 것의 난이도가 높음
- Related Works
- Prompting: few-shot & zero-shot learning
- Efficient Transformers for Long Inputs: 기존 transformer는 time & memory 관점에서 quadratic cost 발생
- Persona-dependent Conversation: 챗봇에 persona를 부여하는 것이 대화 품질을 향상시키지만 쉽지는 않음
- Semantic Parsing: 자연어 query를 데이터 베이스에 적용 가능한 SQL query에 매핑하는 등의 방법
- Zero-shot Learning with Task Instructions: multi-task prompted training을 통해 모델의 일반화 성능을 향상시킬 수 있음
- Contributions
- long prompts가 주어지는 scenarios에서 computation & memory efficient한 방법 Prompt Injection (PI)를 제시
- 일부 케이스에서 PI의 성능이 상한선(unconstrained) 수준에 이르는 것을 확인
- long prompts를 모델에 injection하는 것이 PI를 통해 달성될 수 있음을 확인
- Prompt Injection
- 기존: 프롬프트 z, 입력 시퀀스 x를 합쳐 y를 반환하는 LM은 f로 표시 -> 기존 방식 대신에 프롬프트 z를 LM에 inject하는 방식
- 프롬프트 z를 여러 sub-프롬프트로 쪼개어 반복적으로 PI process를 진행 (multiple epochs)
- 프롬프트가 LM에 한 번 injected되면 추론 단계에서 해당 프롬프트를 입력 시퀀스에 반복적으로 붙여줄 필요가 없음
- 성능을 평가하는 PI score는 min-max scaling을 통해 획득
- Method for Prompt Injection
- Continued Pre-training: target prompt에 대해 LM의 기존 objective를 유지하여 추가 학습
- Curriculumn Learning: 이때 mask의 비율을 난이도로 판단하고 점진적으로 난이도를 높이는 방식으로 학습
- PING
- 1) input generator가 task-specific 학습 데이터를 생성
- 2) input generator는 frozen하여 unseen prompts로부터 pseudo-inputs을 생성. 이는 프롬프트와 함께 teacher model에 주어지고, puseduo-inputs은 student 모델에 전달
- Datasets
- Persona-Chat, Spider, WSC / RTE / COPA
- Baseline
- T5, Fusion-in-Decoder (FiD), Linear Transformer
- Results
- Inference Efficiency: PI는 prompt 길이에 독립적이라 효율적임. FLOP 기준 최대 280배 효율적
- Model Performance: 방법론별 모델 성능은 입력 시퀀스의 복잡도에 달려 있음
- Long Prompts Injection: 13,000 토큰이 되는 위키피디아 문서를 제대로 이해한 결과를 cherry picking하여 제시
- 개인적 감상
- transformer 기반의 모델들이 지닌 한계를 극복하는 참신한 시도인 것 같으나 완전히 고정된 프롬프트를 주입시켜 놓은 것이라 일반화 성능이 많이 부족할 것 같다는 의문이 바로 드는 방식..
- cherry picking한 케이스를 제외하면 확실히 결과물이 아쉬울 것 같다는 느낌이 듦
Prompt Injection: Parameterization of Fixed Inputs
Recent works have shown that attaching prompts to the input is effective at conditioning Language Models (LM) to perform specific tasks. However, prompts are always included in the input text during inference, thus incurring substantial computational and m
arxiv.org