
관심 있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[The University of Hong Kong, Huawei Noah’s Ark Lab]
- LLM이 능력을 스스로 발전시킬 수 있는 learning framework, SELF (Self-Evolution with Language Feedback)을 제시
- 숫자가 아닌 언어(자연어) 기반의 피드백을 활용한다는 것이 특징
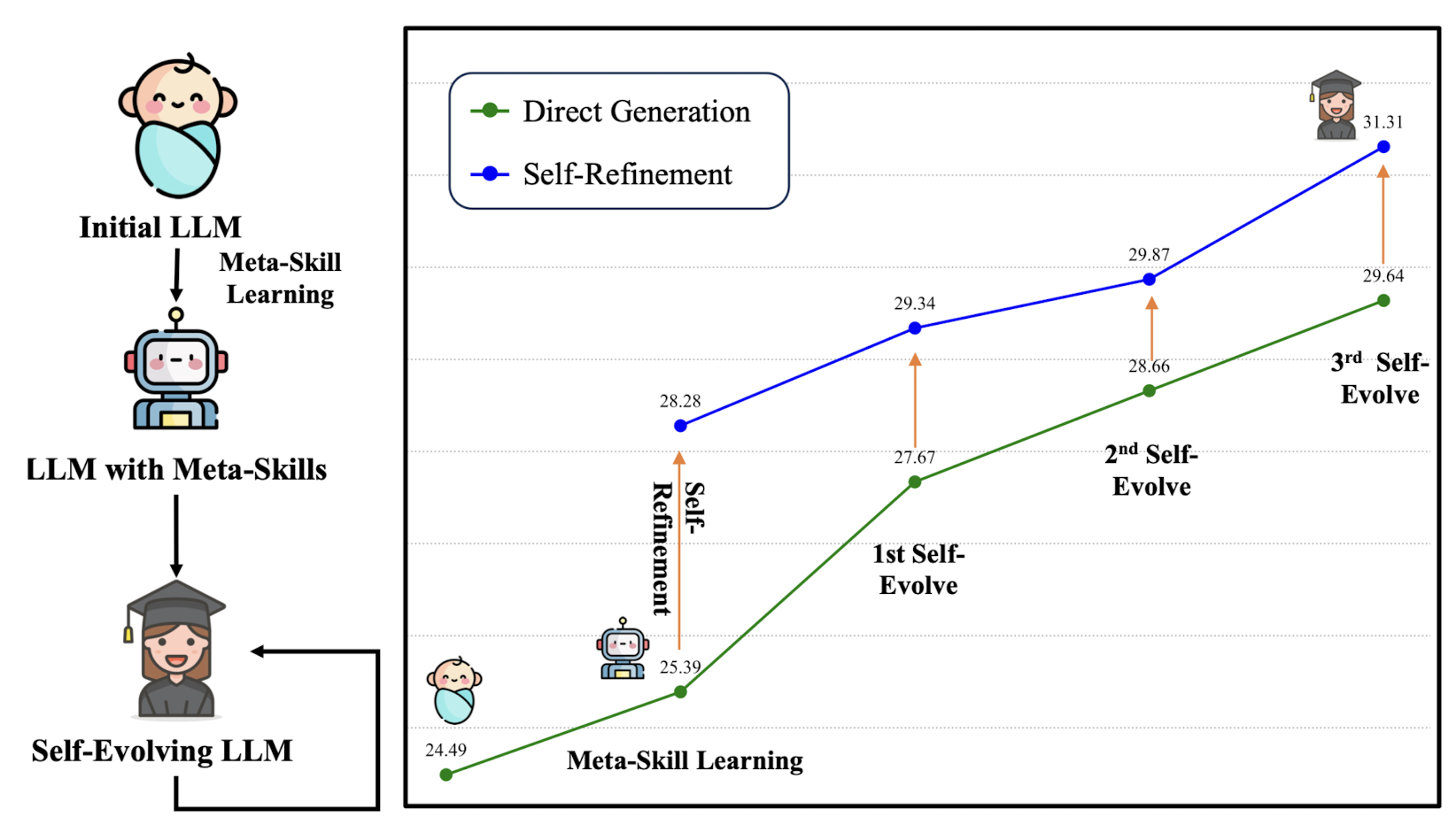
1. Introduction
뛰어난 능력을 지닌 다양한 LLM들이 소개되어 왔지만, 아직까지 LLM이 스스로 발전(진화)하는 것과 관련된 연구가 많지는 않습니다.
사실 그런 게 가능한 프레임워크가 제시된다는 것은 사람들이 걱정/기대하는 AGI로의 한 걸음으로 비칠 수도 있겠죠.
본 논문에서는 SELF라는 self-evolution 프레임워크를 제시합니다.
여기서는 self-feedback과 self-refinement라는 두 개의 meta-skill을 바탕으로 반복적인 학습 및 발전이 가능하도록 만들었습니다.
두드러지는 특징 중 하나는 이 방법론을 학습 뿐만 아니라 추론(inference) 단계에도 적용 가능하다는 것입니다.
2. Related Works
- Self-improvement in Inference
- Self-consistency, online self-improvement
- Autonomous Improvements of LLMs
- Alignment, Reinforcement Learning from Human Feedback (RLHF), RLAIF
3. Method
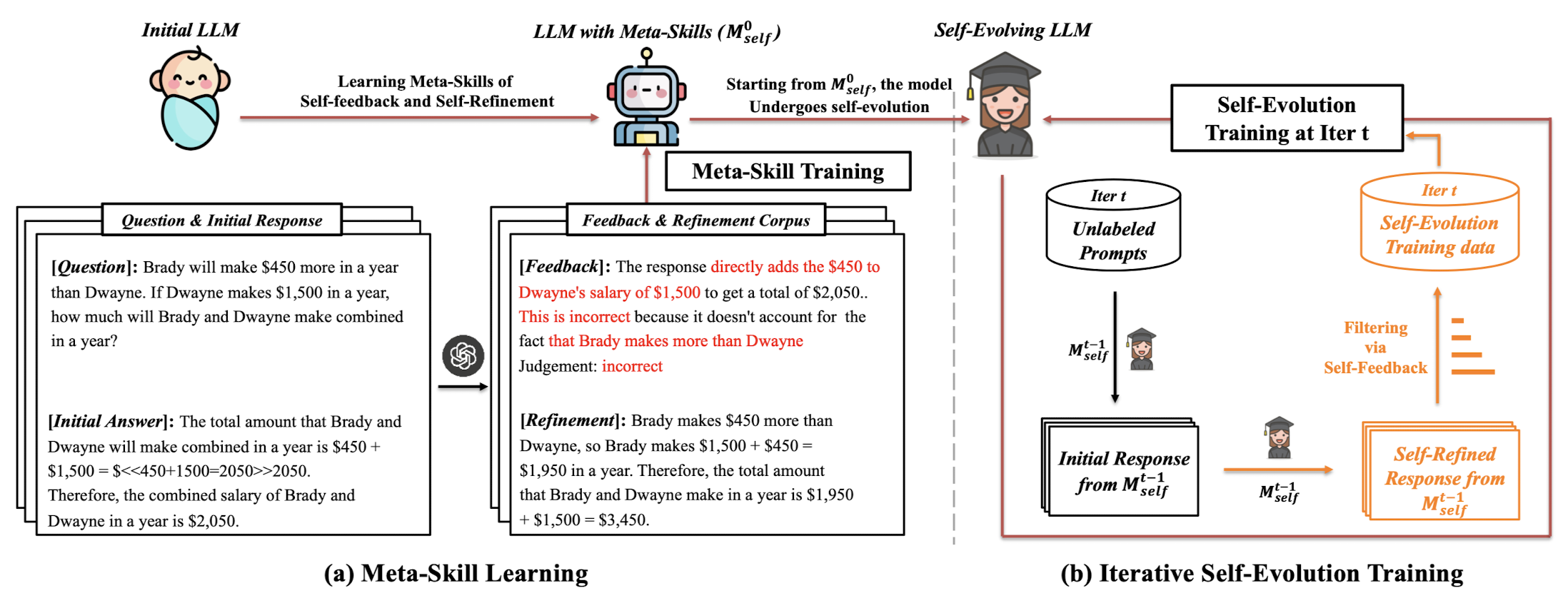
위 그림에서 볼 수 있는 것처럼 SELF는 크게 'Meta-skill Learning 단계'와 'Iterative Self-Evolution Training' 단계로 구분됩니다.
또한 위에서 언급했던 바와 같이 Natural Language Feedback을 활용한다는 것이 특징입니다.
논문에서는 수학적으로 모델링하는 내용을 조금 자세하게 다루고 있는데, 본 포스팅에서는 필수적인 개념과 메서드 정도만 간단히 정리해 보고자 합니다.
3.1. Meta-Skill Learning
주어지는 요소들을 기호로 나타내면 다음과 같습니다.
- unlabeled prompt $p$, 초기 모델 $M_{init}$, 초기 모델이 생성한 response $r$
- annotator $L$이 $r$에 대해 생성한 feedback $f$, 이 feedback을 바탕으로 생성한 refined answer $\hat{r}$
이를 합쳐서 만든 데이터셋 $D_{meta}$는 $(p,r,f,\hat{r})$ 쌍으로 구성됩니다.
우리가 학습시키고자 하는 모델은 이 $D_{meta}$에 대해서 학습하게 됩니다.
이 학습을 통해 $M_{init}$을 $M_{meta}$로 발전시키고자 합니다.
여기에 사용되는 training objective는 다음과 같습니다. (MLE 방식을 따릅니다)
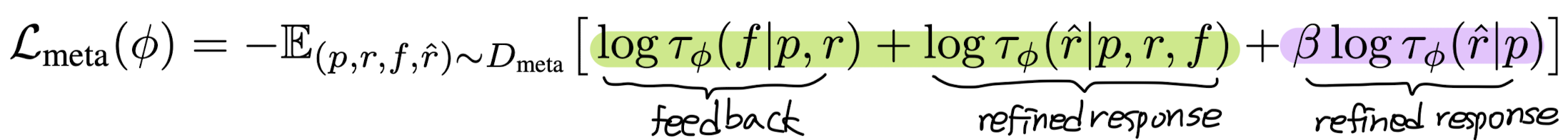
여기서 $\tau_{\phi}(y|x)$가 의미하는 것은 auto-regressive language model에 의해 발생하는 확률 분포입니다.
저자의 설명에 따르면 초록색으로 칠한 부분은 self-feedback에 해당하는 것이고, 보라색으로 칠한 부분은 self-refinement에 해당합니다. 후자의 경우 특히 모델이 문제를 처리하는 Chain-of-Thought (CoT) 방식을 학습할 수 있도록 설계되어 있습니다. (추가 수식은 논문 참고)
3.2. Self-Evolution Training Process
위 학습을 통해 얻은 모델 $M_{meta}$은 여러 interation 동안 self-evolution training process를 거치게 됩니다.
$M^{t}_{evol}$은 $M_{meta}$로부터 출발하여 $t^{th}$의 iteration에 training을 거친 모델로 해석됩니다.
이때 사용되는 데이터셋을 $D^{t}_{evol}$로 표기합니다.
그런데 이 데이터셋의 품질을 보장하기 위해서 filtering을 거치게 됩니다.
또한 추가 학습을 하는 동안 기존 학습된 내용들을 잊어버리는 catastrophic forgetting 이슈를 방지하기 위해 meta-skill을 학습할 때 사용했던 $D_{meta}$ 데이터셋도 함께 학습에 활용했다고 합니다.
이 단계에서의 objective 수식을 발췌한 것은 다음과 같습니다.
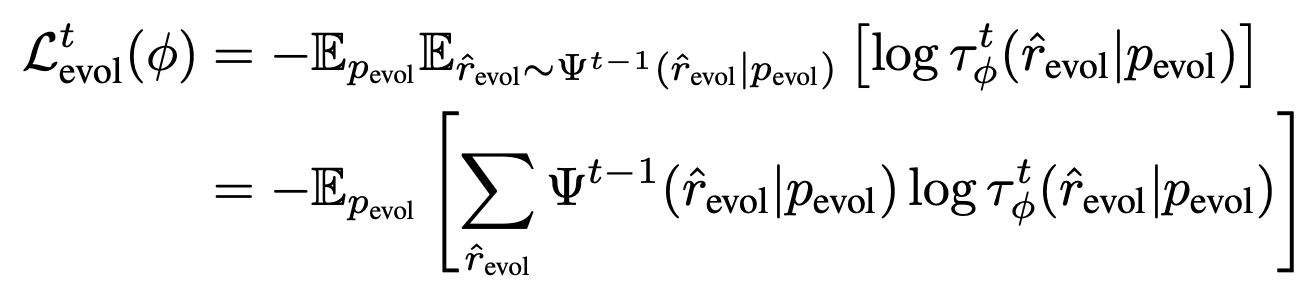
수식에서 $\Psi^{t-1}$이 의미하는 것은 위에서 생략한 CoT 관련 내용입니다.
$t-1$ 시점 이전까지 해당 rationale이 등장하게 된 확률을 곱하여 구하게 되는데 자세한 내용은 논문을 참고하시기 바랍니다.
어쨌든 이것이 의미하는 것은 $\Psi$의 확률 분포에 $\phi$의 확률 분포가 align 될 수 있도록 하는 KL divergence optimization이 됩니다.
4. Experiments & Results
- Inference Setting
- Direct Response vs. Self-Refinement
- Benchmarks
- 수학 벤치마크: GSM8K, SVAMP
- general 벤치마크: Vicuna testset, Evol-Instruct testset
- GPT-4를 annotator $L$로 사용
- Vicuna-7b 모델로 실험을 진행
- OpenLLaMA, Vicuna-1.5 모델들도 실험에 활용
- Methods
- Vicuna + $D_{QA}$
- RLHF
- Self-Consistency
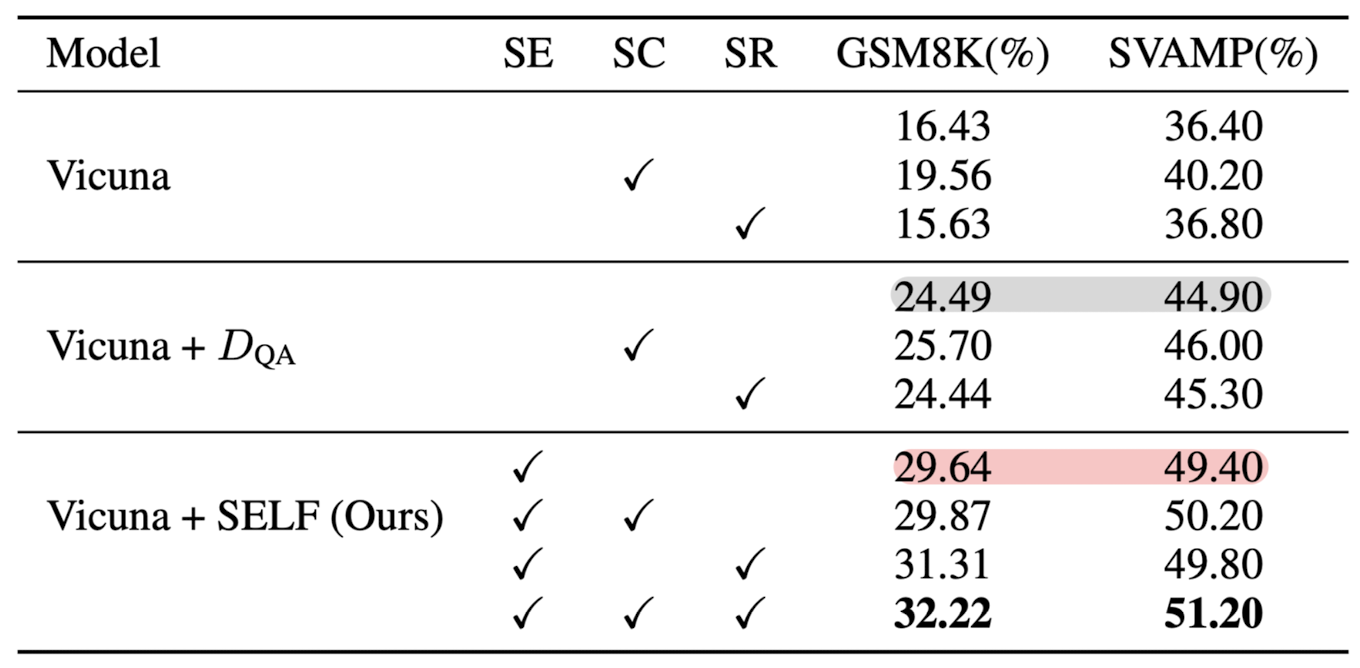
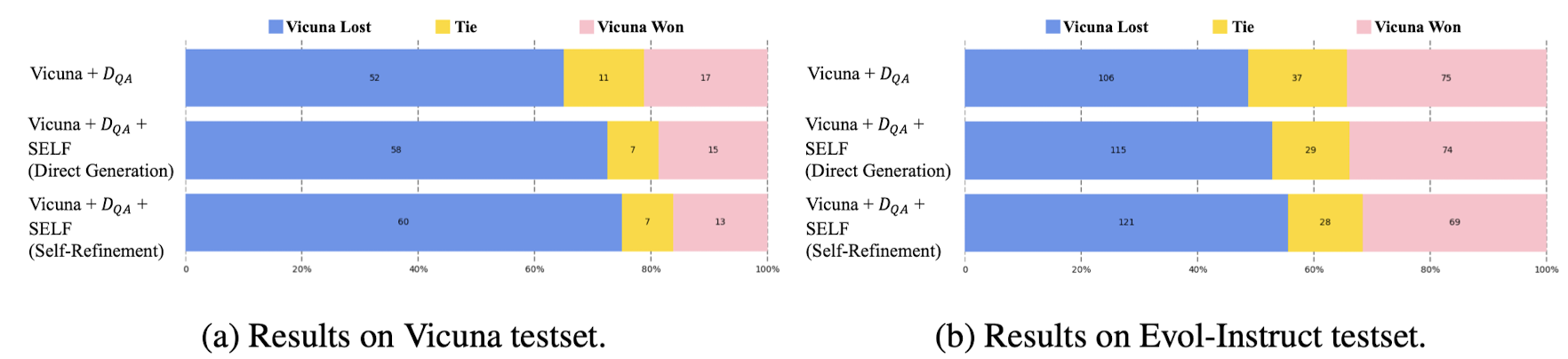
- Results on Mathematical/General Benchmarks
5. Insights
meta-skill을 습득하게 한 뒤 self-evolution을 반복적으로 수행한다는 컨셉 자체는 아주 뛰어난 것 같습니다.
마치 사람도 어느 정도 수준을 갖추고 나면 자기반성을 통해 성숙해지는 것과 같은 접근 방식이라는 인상을 받았습니다.
앞으로 더 생각해 볼 여지가 많은 부분은 feedback이라고 생각했습니다.
기존에는 이를 보통 숫자(reward)로 반환하게 함으로써 간접적으로 옳고 그름에 대해 판단한 내용을 모델에게 전달해 주었습니다.
이를 좀 더 고차원적인 피드백을 제공하는 방식으로 대체하여 모델이 좀 더 타당한 출력을 낼 수 있도록 유도한다는 컨셉 자체는 좋은 것 같습니다.
하지만 이것이 실제 기존 방식에 비해서 더 좋은지는 확신하기 어려운 것 같습니다.
충분히 많은 데이터가 있다면 문장에 녹아든 미묘한 뉘앙스나 표현의 차이 정도는 캐치가 충분히 가능할 것 같다고 생각하기도 하고,
또 자연어 피드백을 단순 CoT 문장 학습이 아닌 다른 방법으로 모델에게 제공해 주는 것이 더 좋을 것 같다는 생각이 들어서 그렇습니다.
출처 : https://arxiv.org/abs/2310.00533
SELF: Self-Evolution with Language Feedback
Large Language Models (LLMs) have demonstrated remarkable versatility across various domains. To further advance LLMs, we propose 'SELF' (Self-Evolution with Language Feedback), a novel approach that enables LLMs to self-improve through self-reflection, ak
arxiv.org
'Paper Review' 카테고리의 다른 글
관심 있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[The University of Hong Kong, Huawei Noah’s Ark Lab]
- LLM이 능력을 스스로 발전시킬 수 있는 learning framework, SELF (Self-Evolution with Language Feedback)을 제시
- 숫자가 아닌 언어(자연어) 기반의 피드백을 활용한다는 것이 특징
1. Introduction
뛰어난 능력을 지닌 다양한 LLM들이 소개되어 왔지만, 아직까지 LLM이 스스로 발전(진화)하는 것과 관련된 연구가 많지는 않습니다.
사실 그런 게 가능한 프레임워크가 제시된다는 것은 사람들이 걱정/기대하는 AGI로의 한 걸음으로 비칠 수도 있겠죠.
본 논문에서는 SELF라는 self-evolution 프레임워크를 제시합니다.
여기서는 self-feedback과 self-refinement라는 두 개의 meta-skill을 바탕으로 반복적인 학습 및 발전이 가능하도록 만들었습니다.
두드러지는 특징 중 하나는 이 방법론을 학습 뿐만 아니라 추론(inference) 단계에도 적용 가능하다는 것입니다.
2. Related Works
- Self-improvement in Inference
- Self-consistency, online self-improvement
- Autonomous Improvements of LLMs
- Alignment, Reinforcement Learning from Human Feedback (RLHF), RLAIF
3. Method
위 그림에서 볼 수 있는 것처럼 SELF는 크게 'Meta-skill Learning 단계'와 'Iterative Self-Evolution Training' 단계로 구분됩니다.
또한 위에서 언급했던 바와 같이 Natural Language Feedback을 활용한다는 것이 특징입니다.
논문에서는 수학적으로 모델링하는 내용을 조금 자세하게 다루고 있는데, 본 포스팅에서는 필수적인 개념과 메서드 정도만 간단히 정리해 보고자 합니다.
3.1. Meta-Skill Learning
주어지는 요소들을 기호로 나타내면 다음과 같습니다.
- unlabeled prompt
- annotator
이를 합쳐서 만든 데이터셋
우리가 학습시키고자 하는 모델은 이
이 학습을 통해
여기에 사용되는 training objective는 다음과 같습니다. (MLE 방식을 따릅니다)
여기서
저자의 설명에 따르면 초록색으로 칠한 부분은 self-feedback에 해당하는 것이고, 보라색으로 칠한 부분은 self-refinement에 해당합니다. 후자의 경우 특히 모델이 문제를 처리하는 Chain-of-Thought (CoT) 방식을 학습할 수 있도록 설계되어 있습니다. (추가 수식은 논문 참고)
3.2. Self-Evolution Training Process
위 학습을 통해 얻은 모델
이때 사용되는 데이터셋을
그런데 이 데이터셋의 품질을 보장하기 위해서 filtering을 거치게 됩니다.
또한 추가 학습을 하는 동안 기존 학습된 내용들을 잊어버리는 catastrophic forgetting 이슈를 방지하기 위해 meta-skill을 학습할 때 사용했던
이 단계에서의 objective 수식을 발췌한 것은 다음과 같습니다.
수식에서
어쨌든 이것이 의미하는 것은
4. Experiments & Results
- Inference Setting
- Direct Response vs. Self-Refinement
- Benchmarks
- 수학 벤치마크: GSM8K, SVAMP
- general 벤치마크: Vicuna testset, Evol-Instruct testset
- GPT-4를 annotator
- Vicuna-7b 모델로 실험을 진행
- OpenLLaMA, Vicuna-1.5 모델들도 실험에 활용
- Methods
- Vicuna +
- RLHF
- Self-Consistency
- Vicuna +
- Results on Mathematical/General Benchmarks
5. Insights
meta-skill을 습득하게 한 뒤 self-evolution을 반복적으로 수행한다는 컨셉 자체는 아주 뛰어난 것 같습니다.
마치 사람도 어느 정도 수준을 갖추고 나면 자기반성을 통해 성숙해지는 것과 같은 접근 방식이라는 인상을 받았습니다.
앞으로 더 생각해 볼 여지가 많은 부분은 feedback이라고 생각했습니다.
기존에는 이를 보통 숫자(reward)로 반환하게 함으로써 간접적으로 옳고 그름에 대해 판단한 내용을 모델에게 전달해 주었습니다.
이를 좀 더 고차원적인 피드백을 제공하는 방식으로 대체하여 모델이 좀 더 타당한 출력을 낼 수 있도록 유도한다는 컨셉 자체는 좋은 것 같습니다.
하지만 이것이 실제 기존 방식에 비해서 더 좋은지는 확신하기 어려운 것 같습니다.
충분히 많은 데이터가 있다면 문장에 녹아든 미묘한 뉘앙스나 표현의 차이 정도는 캐치가 충분히 가능할 것 같다고 생각하기도 하고,
또 자연어 피드백을 단순 CoT 문장 학습이 아닌 다른 방법으로 모델에게 제공해 주는 것이 더 좋을 것 같다는 생각이 들어서 그렇습니다.
출처 : https://arxiv.org/abs/2310.00533
SELF: Self-Evolution with Language Feedback
Large Language Models (LLMs) have demonstrated remarkable versatility across various domains. To further advance LLMs, we propose 'SELF' (Self-Evolution with Language Feedback), a novel approach that enables LLMs to self-improve through self-reflection, ak
arxiv.org