
관심 있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Google DeepMind]
- LLM의 decoding process를 변경함으로써 prompting 없이 CoT reasoning paths를 유도할 수 있다고 주장
- top-k개의 alternative tokens를 조사하여 sequences에 내재하는 CoT paths를 확인. 즉 LLM에게 intrinsic reasoning ability가 있다고 주장
1. Introduction
LLM이 눈부신 발전을 거듭하는 과정에는 reasoning task에 대한 수행 능력의 발전이 큰 몫을 차지하고 있습니다.
여기에는 특히나 CoT (Chain-of-Thought)와 같이 중간 추론 과정을 모델이 explicitly 명시하도록 하는 방법론들이 큰 영향을 주었죠.
그리고 이 방식을 모델이 'fine-tuning' 하지 않고 몇 개의 예시들만을 바탕으로 익힐 수 있도록 하는 in-context learning (ICL)은 지금도 많이 활용되고 있습니다.
그런데 본 논문에서는 기존의 greedy decoding 전략을 첫 토큰을 중심으로 삼는 beam search 방식으로 수정함으로써 모델에 내재된 CoT Reasoning 능력을 이끌어낼 수 있음을 주장하고 있습니다.
어찌보면 모델이 few-shot prompting을 참고하여 특정 출력을 만들어 낼 수 있다는 것은 이미 그 능력을 갖고 있기 때문이라고 생각이 드는 건 당연한데, 이를 추가적인 학습이나 데이터 활용 없이 decoding 전략만으로 유도했다는 것이 대단하게 느껴지네요.
본 연구에서 다루는 것은 특히 'standard question-answer (QA) format'입니다.
즉, 기존에는 few-shot examples가 없이는 원하는대로 답변이 제대로 유도되지 않거나 direct answer만이 반환되는 태스크입니다.
여기에서 모델이 참고할만한 예시 없이 직접 CoT Reasoning을 수행할 수 있도록 한 것이죠.
2. Chain-of-Thought (CoT) Decoding
2.1. The presence of CoT Paths during Decoding
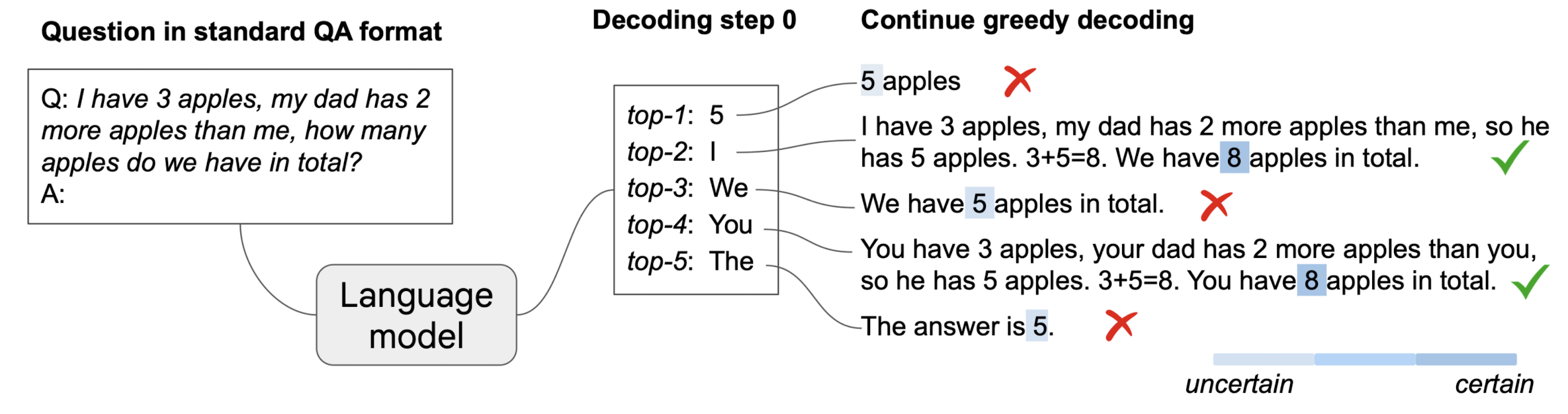
말 그대로 CoT Path가 decoding 단계에 존재할 수 있는지의 여부를 확인한 것입니다.
여러 태스크를 통해 확인한 결과를 제시하고 있는데 3개의 샘플은 다음과 같습니다.

k=0일 때가 기존의 greedy decoding 방식과 동일합니다.
직관적으로 차이를 느낄 수 있으실텐데, k=0일 때는 direct answer를 반환하게 됩니다.
하지만 k가 0이 아닐 때는 우리가 흔히 알고 있는 CoT 형식의 답변이 반환될 수 있음이 확인됩니다.
2.2 CoT-Decoding for Extracting CoT Paths
일반적으로 CoT paths에 해당하는 답변들은 등장할 확률이 그렇지 않은 것에 비해 상대적으로 낮습니다.
따라서 greedy decoding에서는 CoT 형식이 반환될 가능성이 거의 없는 것이죠.
하지만 본 연구에서는 '최종 답변을 직전 토큰들로부터 생성할 확률'을 비교한 결과, CoT path가 보다 confident하게 최종 답변을 생성한다는 것을 발견했습니다.
이를 수식으로 표현하면 다음과 같습니다.
$$\Delta _{k, answer} = \frac{1}{n} \sum_{x \in answer} p(x_{t}^{1} \mid x_{< t}) - p(x_{t}^{2} \mid x_{<t})$$
여기서 $x_{t}^{1}$과 $x_{t}^{2}$는 k번째 decoding path의 t step에서 등장할 확률이 가장 높은 두 개의 토큰입니다.
그리고 $n$은 정답 토큰의 총 개수입니다.
따라서 각 정답 토큰에 대해서, 정답 토큰의 이전까지의 토큰들을 바탕으로 등장할 확률이 가장 높은 토큰과 두 번째로 높은 토큰의 확률차를 구한 뒤, 토큰의 개수로 나눠 평균을 취하는 것입니다.
위 GSM8K에서의 예시를 생각해본다면 최종 정답인 60은 6과 0이라는 토큰으로 나뉩니다.
이때 6 이전까지의 토큰을 바탕으로 등장할 확률이 가장 높은 토큰 두 개의 확률 차를 구하고, 0 이전까지의 토큰을 바탕으로 등장할 확률이 가장 높은 토큰 두 개의 확률 차를 구하여 평균을 취하게 되는 것입니다.
($x_{t}^{1}$ 자리에 6과 0이 순서대로 오겠죠?)
예시에서는 $\Delta$의 값이 파란색으로 표시되어 있는데 기존 greedy decoding 방식에 비해 CoT-decoding이 훨씬 큰 값을 갖게 되는 것을 확인할 수 있습니다.
이것이 최종 정답을 얼마나 confident하게 도출해냈는가에 대한 지표로 활용됩니다.
또한 hueristic한 방법으로 decoding path의 길이를 활용하는 방법이 있는데 length bias, 즉 더 긴 길이의 문장에 가점을 주는 현상을 고려하여 활용하지 않은 것 같습니다.
Branching at other decoding steps
CoT-decoding은 첫 번째 decoding step에서 여러 alternative tokens를 고려하는 방식을 취하고 있습니다.
하지만 어디에서 branch를 만드는 것이 가장 효율적인가는 태스크에 따라 달라질 수 있음을 언급합니다.
예를 들어 parity task의 경우 mid-path branching이 올바른 CoT paths를 만들 가능성이 가장 높은 전략이었습니다.
Aggregation of the decoding paths
CoT-decoding은 top-k 개의 decoding paths를 고려하기 때문에, 모든 paths에 대한 적답을 aggregate할 필요가 있습니다.
이는 과거 self-consitency와 비슷한 방식으로 여겨질 수 있음도 언급되고 있습니다.
다만 model의 logits 값에 지나치게 큰 영향을 받게 되는 것을 방지하기 위해 weighted aggregation method를 취한다고 밝혔습니다.
즉, k 번째 decoding path에서의 정답 a를 도출할 때, confident score $\hat{\Delta}_{a} = \sum_{k}\Delta_{k,a}$를 최대화하는 answer를 취하게 됩니다.
3. Experiments & Results
- Experiment Setup
- standard QA format: "Q: [question]\nA:", k=10
- Models
- PaLM-2 (X-Small, Small, Medium, Large)
- Mistral-7B (with instruction-tuned models)
- answers
- Mistral: extract the last numerical numbers
- PaLM-2: prompt "So the answer is"
Results
- Mathematical Reasoning Tasks
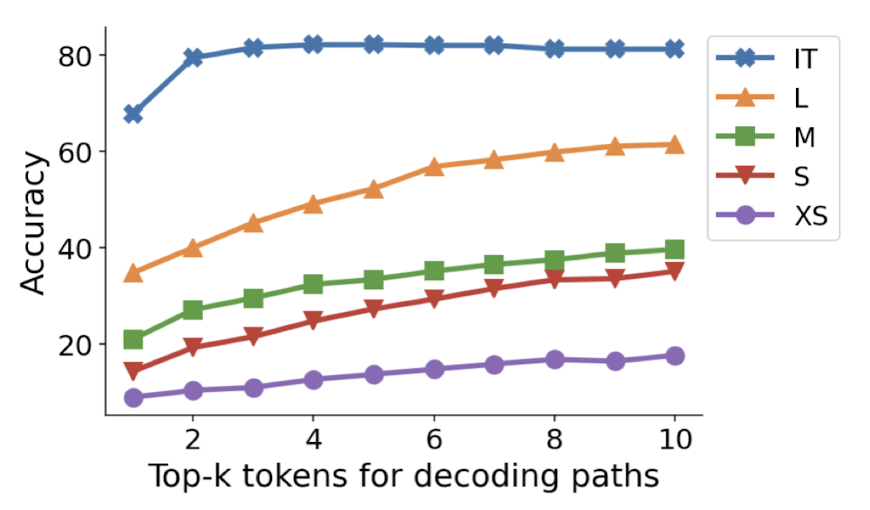
- CoT-decoding 방식이 확실히 greedy decoding에 비해 뛰어난 성능을 보여줌
- instruction-tuned 모델에 대해서도 그 효과가 확실함. 그리고 instruction-tuned 모델과 그렇지 않은 모델 간의 gap을 줄여줌
- instruction-tuned 모델을 제외하면 top-k의 k를 10까지 늘리는 것이 지속적인 성능 향상으로 이어짐

- Natural Language Reasoning Tasks
- "year parity": "Was [person] born in an even or odd year?"
- top 100개의 유명인사 이름을 직접 curate.
- Symbolic Reasoning Tasks
- Coin Flip, Web of files, Multi-step arithmetic, Sports Understanding, Object Counting
- 태스크가 복잡해질수록 CoT-decoding의 이점이 점점 줄어드는 경향이 있음
- 사전 학습 데이터의 분포에 큰 영향을 받는다는 것이 확인됨
- Few-shot CoT와 견줄만한 결과


- Results across Model Families (Mistral-7B)

4. Related Work
- Chain-of-thought reasoning in large language models
- step-by-step verification, process-based feedback, self-evaluation guided beam search, PathFinder
- Instruction-tuning to elicit CoTs in language models
- instruction-tuning, distillation, tuned by a proxy
- Decoding algorithms for language models
- greedy decoding, temperature sampling, top-k sampling, nucleus sampling, minimum Bayes risk decoding, typcial decoding, Diverse beam search, Contrastive decoding
- Decoding algorithms for efficiency
- 본 연구에 향후 적용되어야 할 분야
5. Insight
few-shot 없이 CoT를 유도한다니..
상당히 충격적인 컨셉으로 다가오기도 합니다.
어찌보면 진즉에 당연히 가능했어야 하는 방식인데 아무도 생각을 못했던 걸까요? 😂
다만 저자가 언급했던 것처럼 inference 단계에서 비용을 최소화하는 것에 대한 연구가 추가로 이뤄지면 참 좋을 것 같습니다.
이건 이전에 self-consistency와 같은 방법론들이 지닌 문제를 그대로 반복하는 꼴이라서..
decoding을 건드려서 좋은 성과를 낸 방식들은 항상 이 문제에 직면하게 되는 것 같긴 합니다.
출처 : https://arxiv.org/abs/2402.10200
Chain-of-Thought Reasoning Without Prompting
In enhancing the reasoning capabilities of large language models (LLMs), prior research primarily focuses on specific prompting techniques such as few-shot or zero-shot chain-of-thought (CoT) prompting. These methods, while effective, often involve manuall
arxiv.org
'Paper Review' 카테고리의 다른 글
관심 있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Google DeepMind]
- LLM의 decoding process를 변경함으로써 prompting 없이 CoT reasoning paths를 유도할 수 있다고 주장
- top-k개의 alternative tokens를 조사하여 sequences에 내재하는 CoT paths를 확인. 즉 LLM에게 intrinsic reasoning ability가 있다고 주장
1. Introduction
LLM이 눈부신 발전을 거듭하는 과정에는 reasoning task에 대한 수행 능력의 발전이 큰 몫을 차지하고 있습니다.
여기에는 특히나 CoT (Chain-of-Thought)와 같이 중간 추론 과정을 모델이 explicitly 명시하도록 하는 방법론들이 큰 영향을 주었죠.
그리고 이 방식을 모델이 'fine-tuning' 하지 않고 몇 개의 예시들만을 바탕으로 익힐 수 있도록 하는 in-context learning (ICL)은 지금도 많이 활용되고 있습니다.
그런데 본 논문에서는 기존의 greedy decoding 전략을 첫 토큰을 중심으로 삼는 beam search 방식으로 수정함으로써 모델에 내재된 CoT Reasoning 능력을 이끌어낼 수 있음을 주장하고 있습니다.
어찌보면 모델이 few-shot prompting을 참고하여 특정 출력을 만들어 낼 수 있다는 것은 이미 그 능력을 갖고 있기 때문이라고 생각이 드는 건 당연한데, 이를 추가적인 학습이나 데이터 활용 없이 decoding 전략만으로 유도했다는 것이 대단하게 느껴지네요.
본 연구에서 다루는 것은 특히 'standard question-answer (QA) format'입니다.
즉, 기존에는 few-shot examples가 없이는 원하는대로 답변이 제대로 유도되지 않거나 direct answer만이 반환되는 태스크입니다.
여기에서 모델이 참고할만한 예시 없이 직접 CoT Reasoning을 수행할 수 있도록 한 것이죠.
2. Chain-of-Thought (CoT) Decoding
2.1. The presence of CoT Paths during Decoding
말 그대로 CoT Path가 decoding 단계에 존재할 수 있는지의 여부를 확인한 것입니다.
여러 태스크를 통해 확인한 결과를 제시하고 있는데 3개의 샘플은 다음과 같습니다.
k=0일 때가 기존의 greedy decoding 방식과 동일합니다.
직관적으로 차이를 느낄 수 있으실텐데, k=0일 때는 direct answer를 반환하게 됩니다.
하지만 k가 0이 아닐 때는 우리가 흔히 알고 있는 CoT 형식의 답변이 반환될 수 있음이 확인됩니다.
2.2 CoT-Decoding for Extracting CoT Paths
일반적으로 CoT paths에 해당하는 답변들은 등장할 확률이 그렇지 않은 것에 비해 상대적으로 낮습니다.
따라서 greedy decoding에서는 CoT 형식이 반환될 가능성이 거의 없는 것이죠.
하지만 본 연구에서는 '최종 답변을 직전 토큰들로부터 생성할 확률'을 비교한 결과, CoT path가 보다 confident하게 최종 답변을 생성한다는 것을 발견했습니다.
이를 수식으로 표현하면 다음과 같습니다.
여기서
그리고
따라서 각 정답 토큰에 대해서, 정답 토큰의 이전까지의 토큰들을 바탕으로 등장할 확률이 가장 높은 토큰과 두 번째로 높은 토큰의 확률차를 구한 뒤, 토큰의 개수로 나눠 평균을 취하는 것입니다.
위 GSM8K에서의 예시를 생각해본다면 최종 정답인 60은 6과 0이라는 토큰으로 나뉩니다.
이때 6 이전까지의 토큰을 바탕으로 등장할 확률이 가장 높은 토큰 두 개의 확률 차를 구하고, 0 이전까지의 토큰을 바탕으로 등장할 확률이 가장 높은 토큰 두 개의 확률 차를 구하여 평균을 취하게 되는 것입니다.
(
예시에서는
이것이 최종 정답을 얼마나 confident하게 도출해냈는가에 대한 지표로 활용됩니다.
또한 hueristic한 방법으로 decoding path의 길이를 활용하는 방법이 있는데 length bias, 즉 더 긴 길이의 문장에 가점을 주는 현상을 고려하여 활용하지 않은 것 같습니다.
Branching at other decoding steps
CoT-decoding은 첫 번째 decoding step에서 여러 alternative tokens를 고려하는 방식을 취하고 있습니다.
하지만 어디에서 branch를 만드는 것이 가장 효율적인가는 태스크에 따라 달라질 수 있음을 언급합니다.
예를 들어 parity task의 경우 mid-path branching이 올바른 CoT paths를 만들 가능성이 가장 높은 전략이었습니다.
Aggregation of the decoding paths
CoT-decoding은 top-k 개의 decoding paths를 고려하기 때문에, 모든 paths에 대한 적답을 aggregate할 필요가 있습니다.
이는 과거 self-consitency와 비슷한 방식으로 여겨질 수 있음도 언급되고 있습니다.
다만 model의 logits 값에 지나치게 큰 영향을 받게 되는 것을 방지하기 위해 weighted aggregation method를 취한다고 밝혔습니다.
즉, k 번째 decoding path에서의 정답 a를 도출할 때, confident score
3. Experiments & Results
- Experiment Setup
- standard QA format: "Q: [question]\nA:", k=10
- Models
- PaLM-2 (X-Small, Small, Medium, Large)
- Mistral-7B (with instruction-tuned models)
- answers
- Mistral: extract the last numerical numbers
- PaLM-2: prompt "So the answer is"
Results
- Mathematical Reasoning Tasks
- CoT-decoding 방식이 확실히 greedy decoding에 비해 뛰어난 성능을 보여줌
- instruction-tuned 모델에 대해서도 그 효과가 확실함. 그리고 instruction-tuned 모델과 그렇지 않은 모델 간의 gap을 줄여줌
- instruction-tuned 모델을 제외하면 top-k의 k를 10까지 늘리는 것이 지속적인 성능 향상으로 이어짐
- Natural Language Reasoning Tasks
- "year parity": "Was [person] born in an even or odd year?"
- top 100개의 유명인사 이름을 직접 curate.
- Symbolic Reasoning Tasks
- Coin Flip, Web of files, Multi-step arithmetic, Sports Understanding, Object Counting
- 태스크가 복잡해질수록 CoT-decoding의 이점이 점점 줄어드는 경향이 있음
- 사전 학습 데이터의 분포에 큰 영향을 받는다는 것이 확인됨
- Few-shot CoT와 견줄만한 결과
- Results across Model Families (Mistral-7B)
4. Related Work
- Chain-of-thought reasoning in large language models
- step-by-step verification, process-based feedback, self-evaluation guided beam search, PathFinder
- Instruction-tuning to elicit CoTs in language models
- instruction-tuning, distillation, tuned by a proxy
- Decoding algorithms for language models
- greedy decoding, temperature sampling, top-k sampling, nucleus sampling, minimum Bayes risk decoding, typcial decoding, Diverse beam search, Contrastive decoding
- Decoding algorithms for efficiency
- 본 연구에 향후 적용되어야 할 분야
5. Insight
few-shot 없이 CoT를 유도한다니..
상당히 충격적인 컨셉으로 다가오기도 합니다.
어찌보면 진즉에 당연히 가능했어야 하는 방식인데 아무도 생각을 못했던 걸까요? 😂
다만 저자가 언급했던 것처럼 inference 단계에서 비용을 최소화하는 것에 대한 연구가 추가로 이뤄지면 참 좋을 것 같습니다.
이건 이전에 self-consistency와 같은 방법론들이 지닌 문제를 그대로 반복하는 꼴이라서..
decoding을 건드려서 좋은 성과를 낸 방식들은 항상 이 문제에 직면하게 되는 것 같긴 합니다.
출처 : https://arxiv.org/abs/2402.10200
Chain-of-Thought Reasoning Without Prompting
In enhancing the reasoning capabilities of large language models (LLMs), prior research primarily focuses on specific prompting techniques such as few-shot or zero-shot chain-of-thought (CoT) prompting. These methods, while effective, often involve manuall
arxiv.org