
관심 있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
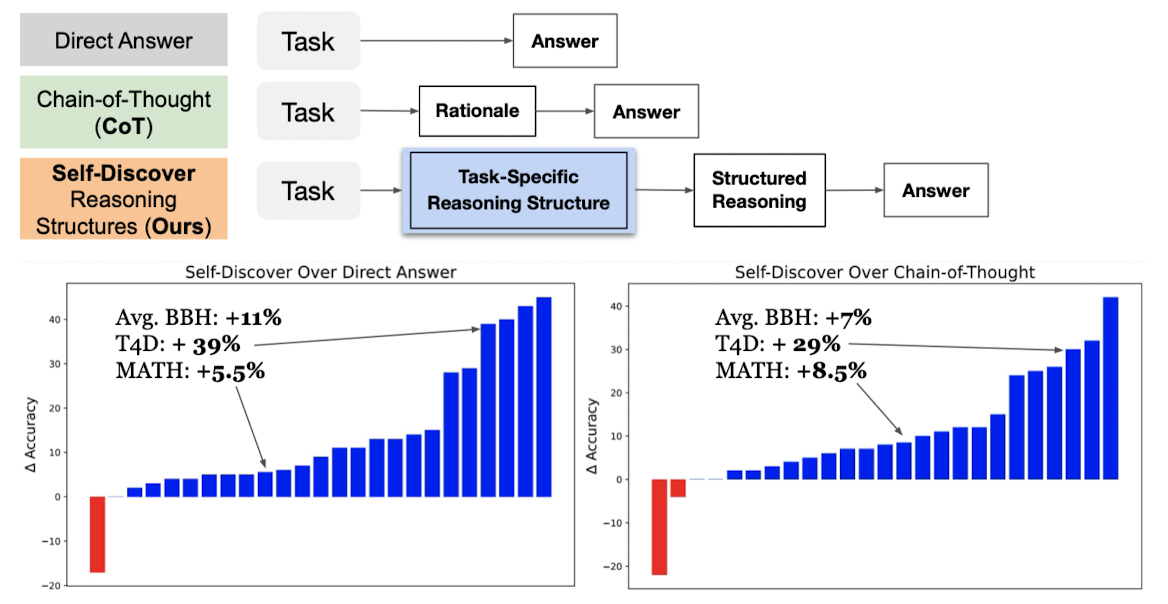
- LLM이 태스크에 내재된 reasoning structure를 스스로 찾아가도록 하는 프레임워크
- LLMs가 multiple atomic reasoning module을 골라야 하는 상황에 적용 가능한 방식
- 이 방식이 다양한 모델 계통에 적용 가능한 것으로 확인 (PaLM 2-L, GPT-4, Llama2)
1. Introduction
지금까지 LLM의 추론(Reasoning) 능력을 향상시키기 위해 여러 시도들이 있었지만, 개인적으로는 하나의 큰 과정을 작은 것 여러 개로 쪼개고 각각을 처리하는 방식이 가장 유효했다고 생각합니다. (decompose)
인상 깊은 방식들이나 뛰어난 성과를 보였던 연구들은 이를 적극적으로 활용하는 것 같더군요. (inference 시에 발생할 API 비용은 차치하고 ㅎㅎ;)
그런데 본 논문에서는 결국 분할된 여러 개의 상황에 대해 모델이 어떤 module을 사용해야 할지를 정하고 결과를 획득하는 것은, 모델이 각 태스크를 처리하기에 적합한 방식이 무엇인지를 '이미 알고 있기 때문'이라고 가정합니다.
마치 뭘 해야 할지는 알지만 그걸 수행할 능력은 없는 상황이랄까요..?
(이렇게 저렇게 하면 멋진 춤이 될 것은 머리로 알지만 몸이 따라주지 않는 상황을 상상해봤습니다)
결국 이 연구에서도 아주 정석적인(?) decomposition 방식을 취합니다.
그렇다면 이제 구체적인 방식을 살펴보도록 하겠습니다..!
2. Self-Discovering Reasoning Structures for Problem-Solving
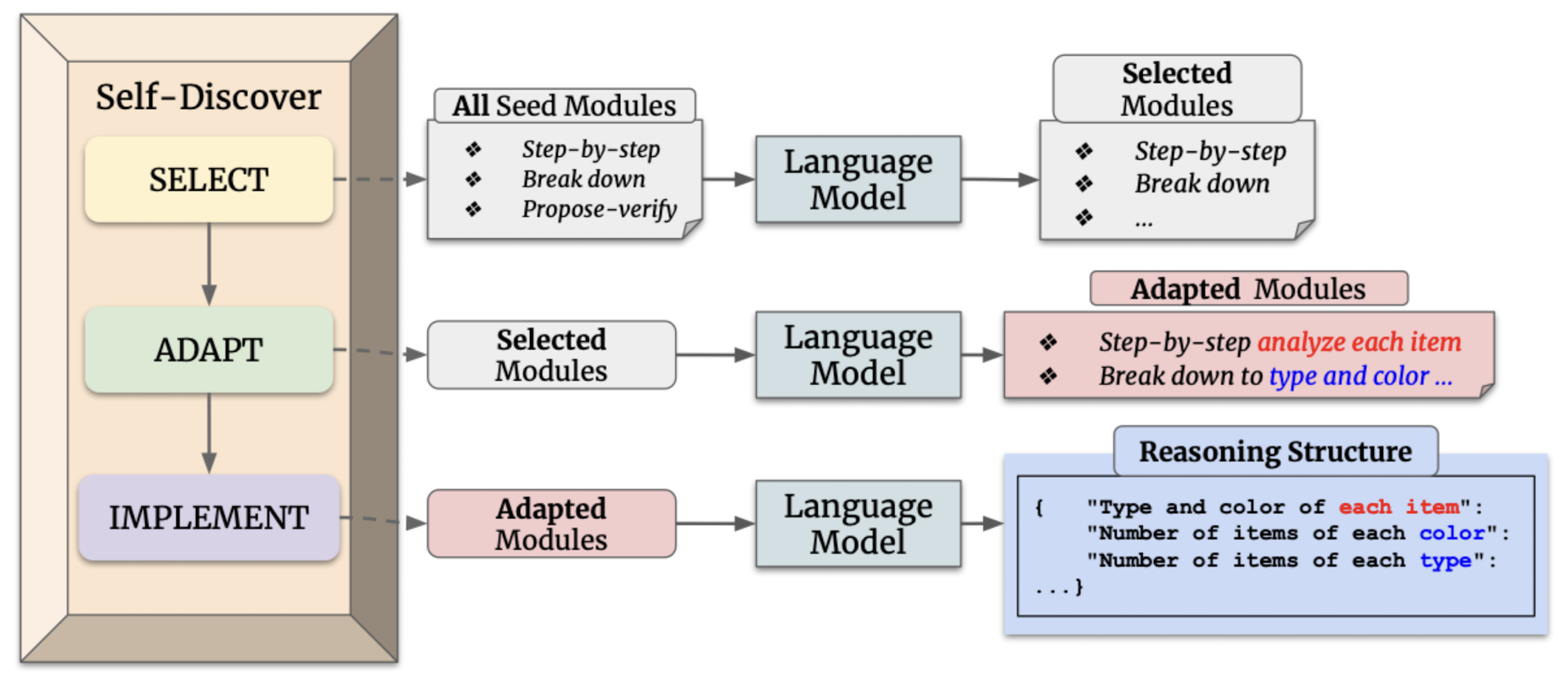
2.1. Stage 1: Self-Discover Task-Specific Structures
첫 스테이지는 세 개의 action으로 구성됩니다.
SELECT
$$D_{S}=M(p_{S}\parallel D \parallel t_{i})$$
task examples를 기반으로 작업을 처리하는 데 필요한 module을 선정합니다.
$D$에는 reasoning에 필요한 module들에 대한 description이 적혀 있습니다. 예를 들어 'critical thinking' 또는 'break the problem into sub-problems' 등이 포함됩니다.
여기서 $t_{i} \in T$는 label이 포함되지 않은 few task examples입니다.
ADAPT
$$D_{A}=M(p_{A}\parallel D_{S} \parallel t_{i})$$
어떤 module을 사용할지는 SELECT 단계에서 정했으니 이를 바탕으로 task에 대해 보다 구체적인 글로 rephrase합니다.
이때 meta-prompt $p_{A}$를 앞에 붙여줍니다.
IMPLEMENT
$$D_{I}=M(p_{I}\parallel S_{human} \parallel D_{A} \parallel t_{i})$$
rephrased된 resoning module description을 바탕으로 reasoning structure를 구축합니다.
이번에는 implement를 위한 meta-prompt $p_{I}$가 앞에 붙습니다.
이 작업이 natural language description을 reasoning structure로 바꾸는 것입니다.
2.2. Stage 2: Tackle Tasks Using Discovered Structures
$$A=M(D_{I}\parallel t),\forall t \in T$$
이제 세 단계를 거쳐 task를 처리하기 위해 필요한 implemented reasoning structure, $D_{I}$를 갖추게 되었습니다.
이 reasoning structure를 단순히 task에 붙여서 답변 $A$를 생성하면 됩니다.
3. Experiments & Results
- Benchmarks
- Big-Bench Hard (BBH): 1) Algorithmic and Multi-Step Arithmetic Reasoning, 2) Natural Language Understanding, 3) Use of World Knowledge, 4) Multilingual Knowledge and Reasoning
- Think for Doing (T4D)
- 200 examples from MATH
- Models
- GPT-4 (gpt-4-turbo-preview), GPT-3.5-turbo (ChatGPT), instruction-tuned PaLM 2-L, Llama2-70B
- Baselines
- Self-Discover with zero-shot prompting: Direct Prompting, CoT, Plan-and-Solve
- Row seed reasoning modules (RM): CoT-Self-Consistency, Majority voting of each RM, Best or each RM
- Results
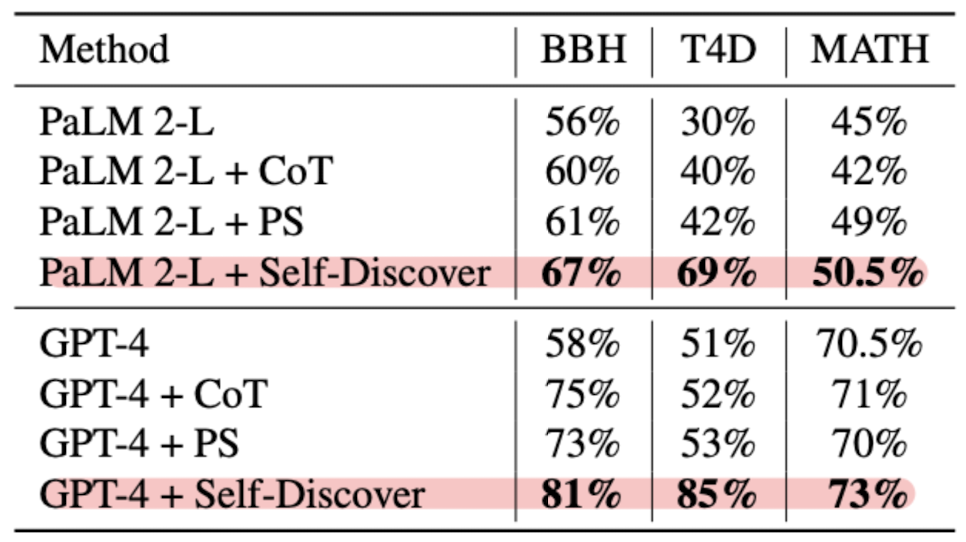
- Self-Discover 방식이 여러 reasoning tasks에서 PaLM 2-L, GPT-4의 reasoning 능력을 향상시킨 것으로 확인
- 다양한 word knowledge를 활용해야 하는 태스크에서 빛을 발함
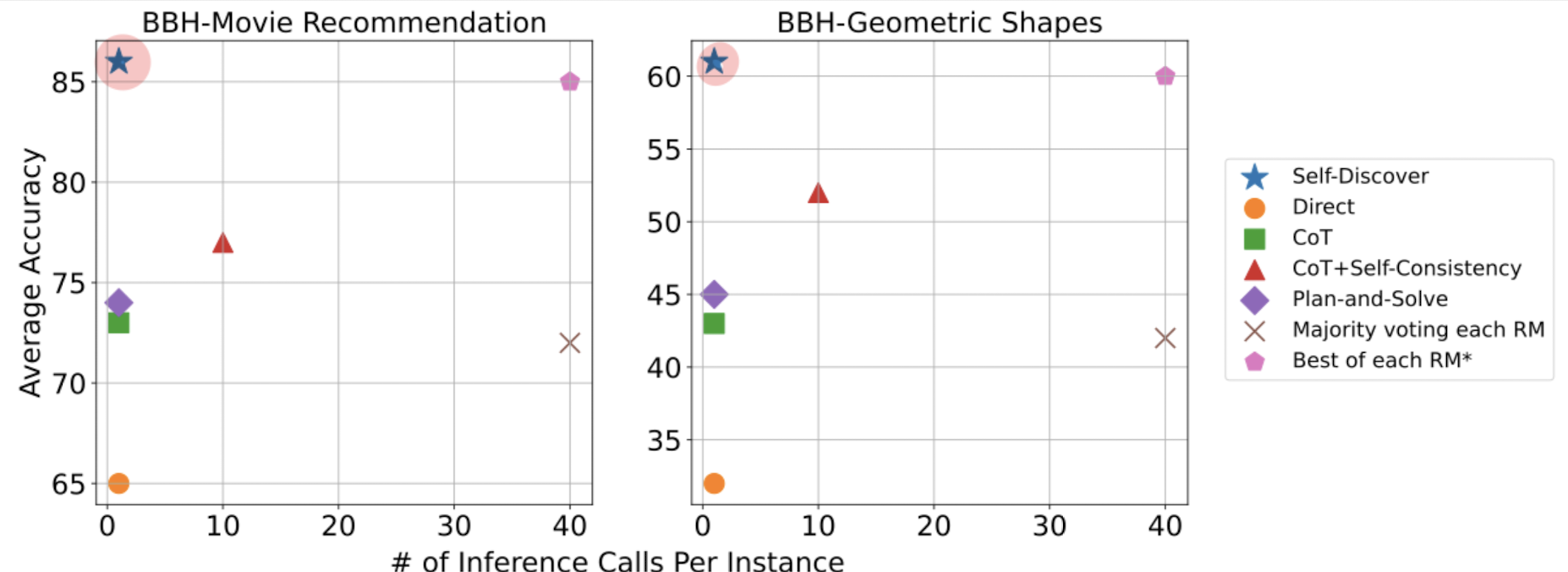
- self-consistency, majority voting 대비 각각 10, 40배 빠른 추론 속도를 보여줌.
4. Related Work
- Prompting Methods
- instructoin, Chain-of-Thought, Leat-to-most prompting, Graph-of-Thought, Tree-of-Thought (ToT)
- Resoning and Planning
- GSM8K, Math, BigBench, scratchpad
5. Insight
시작 부분에서 언급한 것처럼, 저는 지금까지의 솔루션들 중에서 decomposition을 활용하는 방식이 참 괜찮은 것 같습니다.
물론 이 논문의 경우는 방법론 자체엔 novelty가 없는 것 같긴 합니다.
그나마 조금 흥미가 간다고 해야하나.. 공감이 되는 포인트는 모델이 이미 갖고 있는 능력을 깨워준다는 컨셉인 것 같습니다.
parametric 방법이 아닌 경우들에 대해서 LLM이 어떻게 이렇게까지 잘 할 수 있을까? 싶은 생각이 드는 것들은 사실 모델이 다룰 수 있는 엄청나게 많은 요소들 중 일부에 대해 잘 '집중'할 수 있도록 도와주었기 때문이라고 생각하거든요.
또 거기서 생각을 해보면 기존에 decoding 단계에서 모델의 정확도를 높이기 위해 도입되었던 테크닉들에 비해 추론 속도가 빠르다는 것은 엄청난 강점인 것 같긴 합니다.
사실 이런 decoding에서의 테크닉을 다루는 연구들은 추론 속도에 대해 크게 언급하지 않는 경향이 있다고 생각하기 때문에 그렇습니다.
출처 : https://arxiv.org/abs/2402.03620
Self-Discover: Large Language Models Self-Compose Reasoning Structures
We introduce SELF-DISCOVER, a general framework for LLMs to self-discover the task-intrinsic reasoning structures to tackle complex reasoning problems that are challenging for typical prompting methods. Core to the framework is a self-discovery process whe
arxiv.org
'Paper Review' 카테고리의 다른 글
관심 있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
- LLM이 태스크에 내재된 reasoning structure를 스스로 찾아가도록 하는 프레임워크
- LLMs가 multiple atomic reasoning module을 골라야 하는 상황에 적용 가능한 방식
- 이 방식이 다양한 모델 계통에 적용 가능한 것으로 확인 (PaLM 2-L, GPT-4, Llama2)
1. Introduction
지금까지 LLM의 추론(Reasoning) 능력을 향상시키기 위해 여러 시도들이 있었지만, 개인적으로는 하나의 큰 과정을 작은 것 여러 개로 쪼개고 각각을 처리하는 방식이 가장 유효했다고 생각합니다. (decompose)
인상 깊은 방식들이나 뛰어난 성과를 보였던 연구들은 이를 적극적으로 활용하는 것 같더군요. (inference 시에 발생할 API 비용은 차치하고 ㅎㅎ;)
그런데 본 논문에서는 결국 분할된 여러 개의 상황에 대해 모델이 어떤 module을 사용해야 할지를 정하고 결과를 획득하는 것은, 모델이 각 태스크를 처리하기에 적합한 방식이 무엇인지를 '이미 알고 있기 때문'이라고 가정합니다.
마치 뭘 해야 할지는 알지만 그걸 수행할 능력은 없는 상황이랄까요..?
(이렇게 저렇게 하면 멋진 춤이 될 것은 머리로 알지만 몸이 따라주지 않는 상황을 상상해봤습니다)
결국 이 연구에서도 아주 정석적인(?) decomposition 방식을 취합니다.
그렇다면 이제 구체적인 방식을 살펴보도록 하겠습니다..!
2. Self-Discovering Reasoning Structures for Problem-Solving
2.1. Stage 1: Self-Discover Task-Specific Structures
첫 스테이지는 세 개의 action으로 구성됩니다.
SELECT
task examples를 기반으로 작업을 처리하는 데 필요한 module을 선정합니다.
여기서
ADAPT
어떤 module을 사용할지는 SELECT 단계에서 정했으니 이를 바탕으로 task에 대해 보다 구체적인 글로 rephrase합니다.
이때 meta-prompt
IMPLEMENT
rephrased된 resoning module description을 바탕으로 reasoning structure를 구축합니다.
이번에는 implement를 위한 meta-prompt
이 작업이 natural language description을 reasoning structure로 바꾸는 것입니다.
2.2. Stage 2: Tackle Tasks Using Discovered Structures
이제 세 단계를 거쳐 task를 처리하기 위해 필요한 implemented reasoning structure,
이 reasoning structure를 단순히 task에 붙여서 답변
3. Experiments & Results
- Benchmarks
- Big-Bench Hard (BBH): 1) Algorithmic and Multi-Step Arithmetic Reasoning, 2) Natural Language Understanding, 3) Use of World Knowledge, 4) Multilingual Knowledge and Reasoning
- Think for Doing (T4D)
- 200 examples from MATH
- Models
- GPT-4 (gpt-4-turbo-preview), GPT-3.5-turbo (ChatGPT), instruction-tuned PaLM 2-L, Llama2-70B
- Baselines
- Self-Discover with zero-shot prompting: Direct Prompting, CoT, Plan-and-Solve
- Row seed reasoning modules (RM): CoT-Self-Consistency, Majority voting of each RM, Best or each RM
- Results
- Self-Discover 방식이 여러 reasoning tasks에서 PaLM 2-L, GPT-4의 reasoning 능력을 향상시킨 것으로 확인
- 다양한 word knowledge를 활용해야 하는 태스크에서 빛을 발함
- self-consistency, majority voting 대비 각각 10, 40배 빠른 추론 속도를 보여줌.
4. Related Work
- Prompting Methods
- instructoin, Chain-of-Thought, Leat-to-most prompting, Graph-of-Thought, Tree-of-Thought (ToT)
- Resoning and Planning
- GSM8K, Math, BigBench, scratchpad
5. Insight
시작 부분에서 언급한 것처럼, 저는 지금까지의 솔루션들 중에서 decomposition을 활용하는 방식이 참 괜찮은 것 같습니다.
물론 이 논문의 경우는 방법론 자체엔 novelty가 없는 것 같긴 합니다.
그나마 조금 흥미가 간다고 해야하나.. 공감이 되는 포인트는 모델이 이미 갖고 있는 능력을 깨워준다는 컨셉인 것 같습니다.
parametric 방법이 아닌 경우들에 대해서 LLM이 어떻게 이렇게까지 잘 할 수 있을까? 싶은 생각이 드는 것들은 사실 모델이 다룰 수 있는 엄청나게 많은 요소들 중 일부에 대해 잘 '집중'할 수 있도록 도와주었기 때문이라고 생각하거든요.
또 거기서 생각을 해보면 기존에 decoding 단계에서 모델의 정확도를 높이기 위해 도입되었던 테크닉들에 비해 추론 속도가 빠르다는 것은 엄청난 강점인 것 같긴 합니다.
사실 이런 decoding에서의 테크닉을 다루는 연구들은 추론 속도에 대해 크게 언급하지 않는 경향이 있다고 생각하기 때문에 그렇습니다.
출처 : https://arxiv.org/abs/2402.03620
Self-Discover: Large Language Models Self-Compose Reasoning Structures
We introduce SELF-DISCOVER, a general framework for LLMs to self-discover the task-intrinsic reasoning structures to tackle complex reasoning problems that are challenging for typical prompting methods. Core to the framework is a self-discovery process whe
arxiv.org