![]()
최근(2023.10)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Google DeepMind, Standford Univ] LLM의 reasoning process를 자동적으로 guide하는 analogical prompting를 제시. labeling 작업이 필요하지 않아 generality & convenience, 특정 problem에 적용 가능하여 adaptability. 배경 언어 모델을 학습할 때 CoT(Chain of Thought) 방식을 채택하는 것이 모델 성능 향상에 큰 도움이 된다는 것은 이미 잘 알려져 있습니다. 어떤 문제를 해결할 때 단순히 정답만을 반환하는 것이 아니라,..
![]()
최근(2023.10)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Microsoft Research] LLaVA에서 fully-connected vision-language cross-modal connector를 사용한 LLaVA-1.5 공개. data efficient(1.2M public data) & power(SoTA on 11 benchmarks) 배경 최근에는 LLM 뿐만 아니라 LMM, 즉 Large Multimodal Models에 대한 관심도 뜨겁습니다. 여기서도 마찬가지로 전체 모델을 tuning 하지 않고도 성능을 끌어 올리는 기법 등에 대한 연구가 많이 이뤄지고 있죠. 그중..
![]()
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [MIT, Meta AI] initial token의 Key, Value를 attention 과정에서 keep하는 방식, Attention Sinks 유한한 길이의 attention window로 학습된 LLM이 무한한 길이의 sequence에 대해 일반화 할 수 있도록 하는 StreaingLLM. 배경 LLM이 여러 태스크에서 뛰어난 퍼포먼스를 보여주는 것은 맞지만, 입력이 특정 길이를 넘어서게 되면 이를 전혀 처리하지 못한다는 문제점을 갖고 있죠. 그런다고 입력 길이를 늘려주자니 attention 연산이 quadratic 하다 보..
![]()
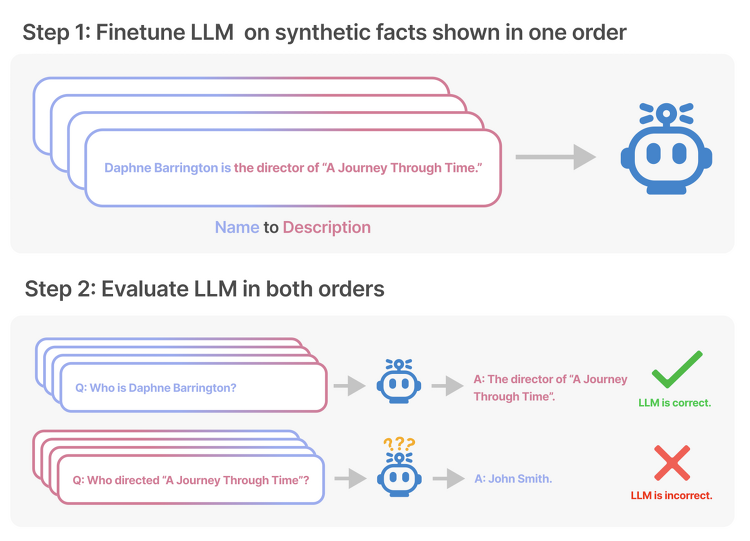
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success LLM의 한계, Reversal Curse를 확인. 순서만 뒤바꾸는 아주 단순한 논리적 연역 추론에 실패하는 현상을 나타냄. 배경 그렇게 뛰어나다고 알려진 LLM들이 가진 아주 단순한 허점에 대해 다룬 논문입니다. 이는 LLM들 대분이 auto-regressive 언어 모델이고, 이는 학습한 텍스트 내 구성 요소의 순서만 도치하더라도 제대로 추론하지 못하는 Reversal Curse를 보여줍니다. 즉, 학습 단계에서 'A는 B이다'라는 것을 배웠다고 하더라도, 추론 단계에서 'B는 무엇입니까?'라는 질문에 적절히 답변하지 못한다는 것..
![]()
최근(2023.09)에 나온 (accept 전 preprint)논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Microsoft, MIT] (Factually Augmented) RLHF를 vision-language alignment에 적용. GPT-4를 이용하여 vision instruction tuning을 위한 데이터셋 확보. hallucination 수준을 파악하는 MMHAL-BENCH 개발. 배경 LLM의 부상과 함께 Large Multimodal Model(LMM) 역시 대규모의 image-text pair 데이터에 대한 사전학습을 바탕으로 큰 주목을 받기 시작했습니다. 그러나 multimoda..
![]()
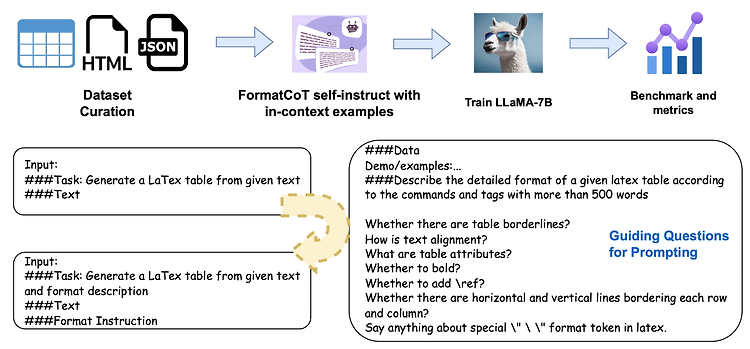
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success 대표 LLM들의 structured output 생성 능력을 테스트하기 위한 Struc-Bench를 제안. FormatCoT(Chain of Thought)를 활용하여 format instruction을 생성. 여섯 개 관점에서 모델의 능력을 나타내는 ability map 제시. 배경 (벌써 몇 주째 같은 이야기로 리뷰를 시작하는 것 같은데.. 😅) 최근 LLM이 다방면으로 엄청난 퍼포먼스를 보여주는 것은 사실이지만, 특정 분야나 태스크에 대해서는 여전히 뚜렷한 한계를 보여주고 있습니다. 그중 가장 대표적인 것 중 하나가 struct..