![]()
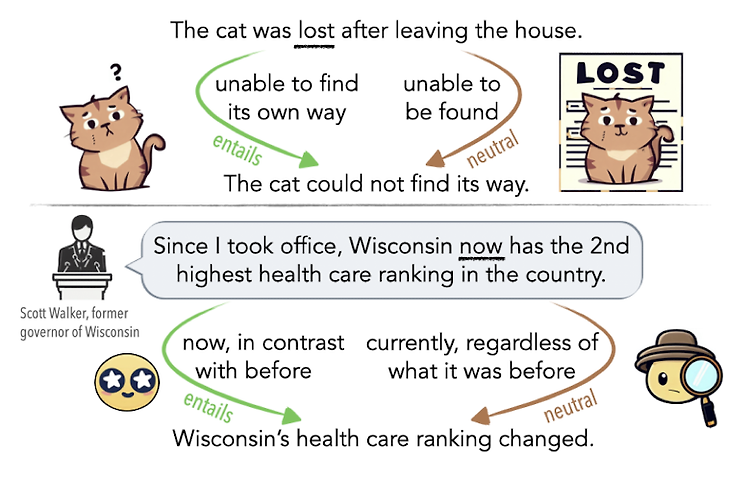
최근에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ 언어가 지닌 ambiguity(모호성)을 인공지능 모델이 이해할 수 있는지 확인할 수 있는 벤치마크 제작 배경 언어의 모호성(ambiguity)는 인간 언어 이해에 있어서 중요한 요소입니다. 중의적인 표현에 대한 해석을 간단한 예로 떠올려 볼 수 있습니다. 때로는 문법적인 오류로 인해 중의적인 의미를 지니는 문장이 될 수도 있지만, 주변 단어들과의 관계에 의해 의미 차이가 발생하는 경우도 존재합니다. LLM을 기반으로 한 챗봇, 즉 대화형 인공지능 모델이 큰 인기를 얻음에 따라, 인공지능 모델이 사람의 언어에 존재하는 이러한 모호성을 이해하고 좋은 판단을 내릴 수 있는지에 대한 관심도 커지고..
![]()
usechatgpt init success 최근에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ Layer Normalization을 residual block의 앞과 뒤, 동시에 적용함으로써 pre/post 두 방식의 장점은 살리고 단점은 극복한 모델 배경 기존 NLP 모델들이 극복하지 못했던 long sequence에 대한 한계를 transformer의 아키텍쳐가 극복해냄으로써 NLP 분야는 눈부시게 발전했습니다. 문장이 길어지면서 전체적인 맥락을 고려하지 못하게 되는 상황이 아주 흔했는데, 이런 문제를 해결하기 위해서 sequence 앞 부분의 정보를 뒤쪽으로 전달하며 업데이트하는 방식이 등장했습니다. BERT 계열의 모델들은 transf..
![]()
문제 링크 https://school.programmers.co.kr/learn/courses/30/lessons/161989 프로그래머스 코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요. programmers.co.kr 소스 코드 def solution(n, m, section): if len(section) == 1: return 1 mini,maxi = section[0],section[-1] # 최소, 최대 cover = mini + m - 1 # 지금까지 칠한 위치 cnt = 1 for i in range(len(section)): if cover >= section[i]: # 현재 위치가 이..
문제 링크 https://school.programmers.co.kr/learn/courses/30/lessons/172928 프로그래머스 코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요. programmers.co.kr 소스 코드 def solution(park, routes): for row in range(len(park)): for col in range(len(park[0])): if park[row][col] == 'S': # 시작점 찾기 cur_x,cur_y = row,col break directions = {'E':(0,1), 'S':(1,0), 'W':(0,-1), 'N':(-1,0)..
![]()
오늘 5/11(목), 한국 기준 새벽 두 시에 Google I/O가 시작되었죠! 저는 자느라고 못 봤지만 일어나보니 재밌는 뉴스들이 조금 있는 것 같았습니다. 폴더블 스마트폰의 출시도 앞으로 시장에 어떤 영향을 줄지 기대가 되는데요, 역시 가장 눈에 띄는 것은 PaLM 2의 등장이겠죠? 이것도 논문..은 아니고 technical report의 형태로 실험 결과 등이 공개되었는데 이를 살펴보고 간략하게 정리해보았습니다. 어차피 아키텍쳐나 구체적인 학습 방법 등에 대한 설명은 포함되지 않았기에 최대한 간단히 특징들만 추려보았어요. 좀 더 자세한 내용이 궁금하시거나 자료 등이 필요하시다면 직접 레포트를 확인해보시길 권장드립니다! 혹시라도 잘못되거나 부족한 내용이 있다면 댓글 부탁드립니다 🙇♂️ 구글의 PaL..
문제 링크 https://school.programmers.co.kr/learn/courses/30/lessons/176963 프로그래머스 코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요. programmers.co.kr 소스 코드 def solution(name, yearning, photo): result = [] score_dict = {} for a,b in zip(name,yearning): # 이름:스코어 딕셔너리 score_dict[a] = b for case in photo: tmp = 0 # 케이스별로 점수 초기화 for idx in range(len(case)): if case[idx..