문제 링크 https://school.programmers.co.kr/learn/courses/30/lessons/178871 프로그래머스 코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요. programmers.co.kr 소스 코드 def solution(players, callings): player_dict = {players[x]:x for x in range(len(players))} rank_dict = {x:players[x] for x in range(len(players))} for name in callings: player_dict[name] -= 1 # 뒤에 있던 애 순위 높이기 p..

전체 글

최근에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ LLaVA: Large Language and Vision Assistant, end-to-end 거대 멀티모달 모델. vision encoder와 LLM을 연결한 구조를 갖고 있다. 배경 인공지능 모델이 생성한 데이터를 기반으로 LLM을 Instruction tuning하는 것이 모델의 성능 향상에 큰 도움이 된다는 것은 잘 알려져 있다. 이런 방식을 통해 모델은 다양한 태스크를 두루 잘 처리할 수 있게 되었고, 덕분에 instruction tuning에 대한 관심이 뜨겁다. 그러나 multi-modal 분야(그중에서도 image-text)에 대해서는 자연어로 이미지를 간단히 설명하는 수준..

최근에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ 프롬프트를 Gist(요점) 토큰에 압축함으로써 모델의 태스크 처리 시간을 단축하고 메모리 효율성을 높일 수 있다. 배경 최근 LM(Language Model)을 활용하는 주된 방법 중 하나는 모델에 prompt를 제공하고 모델이 반환하는 answer를 사용하는 것이다. 태스크나 여러 상황에 따라 적절한 프롬프트를 구성하는 전략이 중요해졌고, 심지어 프롬프트 엔지니어라는 이름의 새직종이 생겨날만큼 많은 관심을 받고 있다. 그러나 모델이 입력으로 받을 수 있는 길이에 제한이 존재한다는 점을 감안하면, 길이가 꽤 되는 프롬프트를 반복적으로 사용하는 것은 꽤나 치명적인 문제가 될 수 있다. 본 논문..
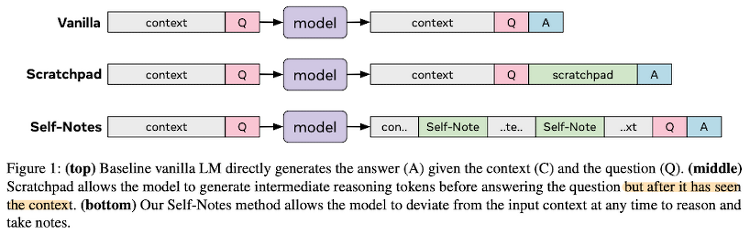
최근에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ 모델이 추론하는 과정에서 스스로 생성한 QA(note)를 참고해 보다 정확한 추론을 가능하도록 만든 모델 배경 지금까지의 인공지능 모델들은 multi-step reasoning에 대해 취약한 모습을 보이고 있다. 왜냐하면 여러 단계를 한 번에 압축하여 추론하므로 모델의 입장에서 여러 요소를 충분히 고려할 수 없게 되기 때문이다. 즉 여러 state가 주어졌을 때, state-traking 혹은 highly nonlinear 문제들을 풀어낼 수가 없는 것이다. 따라서 본 논문에서는 multi-step reasoning을 진행하는 과정에서, 주어진 문장에 대해 모델 스스로 질문 & 답변하고, 이..

최근에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ LLaMA-Adpater의 두 번째 버전. 기존과 달리 이미지까지 더 잘 처리할 수 있는 multi-modality 보유 배경 어떻게 하면 LLM을 instruction follower로 만들 수 있을지, 즉 어떻게 instruction tuning을 잘 할 수 있을지에 대해 많은 관심이 쏠리고 있다. 이전에 LLaMA-Adapter와 같은 모델도 굉장히 효율적인 tuning 방법론을 제시했는데 이를 더욱 발전시킨 모델을 제시한다. V1과 비교했을 때 가장 큰 차이점은 이미지 관련 태스크도 굉장히 잘 처리할 수 있다는 것이다. 컨셉 1. bias tuning of linear layers V..

최근에 나온 논문을 읽어보고 간단히 정리했습니다. 노션에 정리한 것을 그대로 긁어왔는데, 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ LLM에서 갑자기 등장하는 파워풀한 능력, emergent ability는 실재하는 것이 아니다. 연구자들의 편협한 metric 선택이 불러온 결과. 배경 LLM이 지닌 엄청난 능력이 주목을 받게 된 것은 GPT-3와 같이 파격적인 모델 파라미터 구성으로 학습을 진행한 시점부터였다. 흥미로운 것은 모델의 사이즈가 작았을 때 눈 씻고 봐도 찾을 수 없었던 능력이, 모델의 사이즈를 키우면서 ‘갑작스럽게’ 등장한다는 점이었다. 대표적인 예로 in-context-learning(이를 학습으로 볼 수 있는지에 대한 의견도 분분하지만) 등을 들 수 있다. 현재까지..