
최근에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
Layer Normalization을 residual block의 앞과 뒤, 동시에 적용함으로써 pre/post 두 방식의 장점은 살리고 단점은 극복한 모델
- 배경
기존 NLP 모델들이 극복하지 못했던 long sequence에 대한 한계를 transformer의 아키텍쳐가 극복해냄으로써 NLP 분야는 눈부시게 발전했습니다.
문장이 길어지면서 전체적인 맥락을 고려하지 못하게 되는 상황이 아주 흔했는데, 이런 문제를 해결하기 위해서 sequence 앞 부분의 정보를 뒤쪽으로 전달하며 업데이트하는 방식이 등장했습니다.
BERT 계열의 모델들은 transformer 구조에서도 Layer Normalization(LM)을 이 residual block의 뒤에 적용하는 Post-LN 방식을 취했습니다.
반면 GPT 계열의 모델들은 LM을 residual block의 앞에 적용하는 Pre-LN 방식을 취했습니다.
두 방식은 각각 layer가 깊어짐에 따라 Gradient Vanishing, Representation Collapse 문제가 발생한다는 한계가 있습니다.

본 논문에서는 Post/Pre LN 방식을 동시에 적용하며 두 방식의 문제점인 Gradient Vanishing, Representation Collapse를 해결하고 성능을 끌어올리는 모델을 제시합니다.
- 컨셉
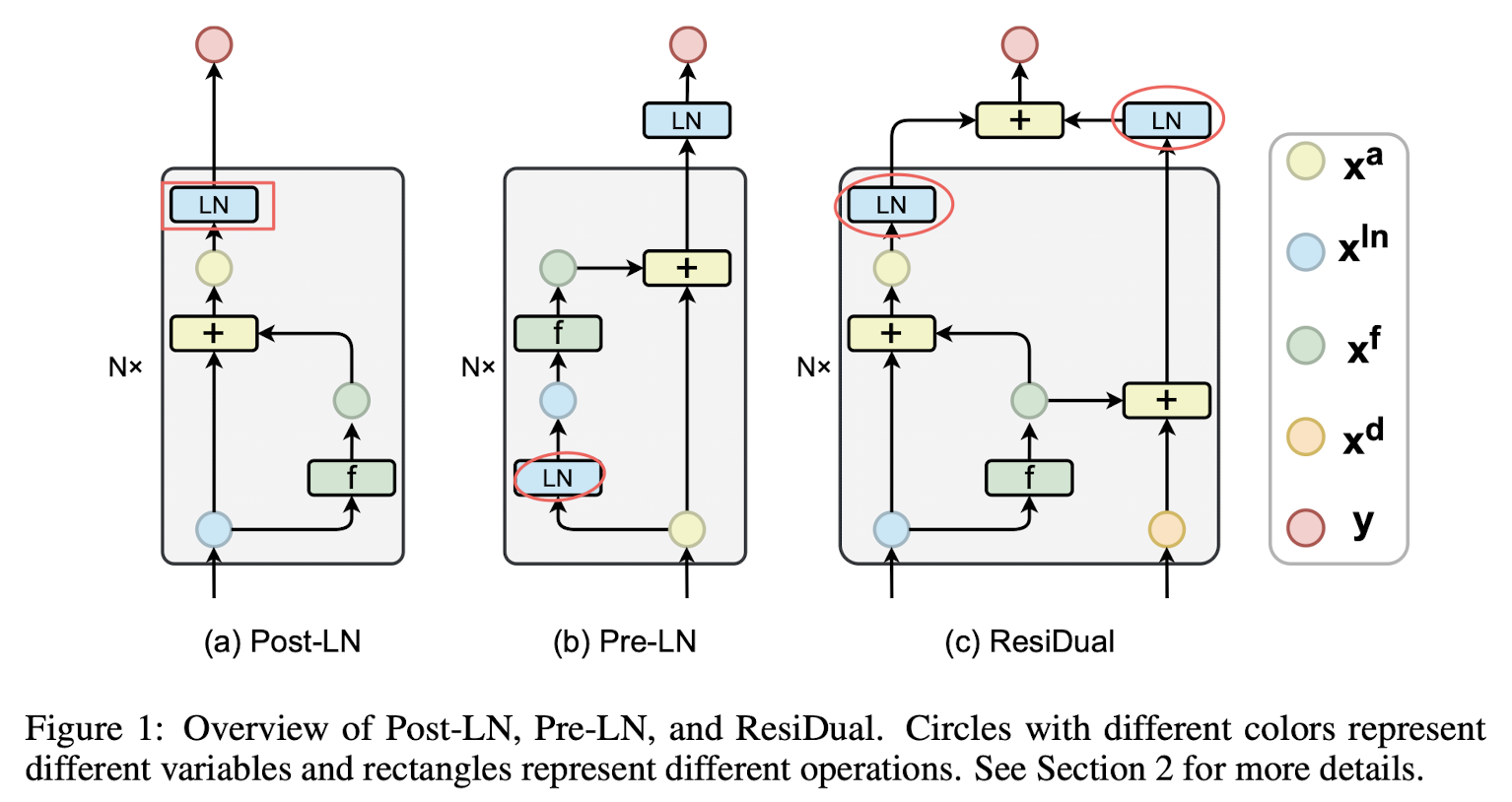
빨간색으로 표시된 LM이 적용되는 위치를 눈여겨 볼 필요가 있습니다.
ResiDual 방식에서는 기존의 Post, Pre 방식에서의 결과를 합쳐서 y를 도출하는 것을 볼 수 있습니다.
본 논문에서는 기존 방식의 문제점으로 지적했던 것들이 ‘수식적’으로도 해결되었음을 입증하고, 이를 경험적인 결과로도 보여줍니다.
이부분은 내용이 굉장히 복잡하고 어려워서 저도 이해하지 못한 내용들이 많았는데요, 좀 더 자세히 알아보고 이해를 하고 싶으신 분들은 논문 원본을 보시는 걸 추천드립니다.
(파악하기 어려운 수식들이 난무합니다 ㅎㅎ)
모델의 성능은 번역 태스크를 통해 검증되었고, 특히 warm-up과 같은 테크닉이 미치는 영향에 대해서도 확인한 것이 기록되어 있습니다.
- 개인적 감상
👍🏻
물론 이해도가 낮은 상태에서 이런 판단을 하면 안 되긴 하지만..
본인들의 주장을 논리적(수학적/수식적)으로 먼저 입증하고 이에 부합하는 실제 결과물을 제시한 것을 보고 아주 완성도가 높은 논문이라는 생각이 들었습니다.
지금까지 제가 봤던 정말 대부분의 페이퍼는 논란의 여지가 있을 수밖에 없는 내용 중 하나의 입장을 택하고 이를 경험적으로 입증하는 경우가 대부분이었습니다.
아주 간단한 예를 생각해본다면, 어떤 batch size가 최적일까에 대해 생각해본다면 여러 변수들에 따라 그 결과가 다를 것입니다.
하지만 본인들의 실험에서는 이런 조건 내에서 이것이 최적이었다, 라고 주장하는 것이 어떤 의미를 가질 수 있을까라는 생각을 항상했었습니다.
요즘 LLM과 관련된 키워드로 연결해본다면 일반화 성능이 떨어진다는 것이죠.
그러나 이 논문은 논리성을 갖춘 상태에서 결과까지 이를 확실하게 뒷받침하고 있는, 아주 좋은 구성으로 쓰인 논문이라는 생각이 들었습니다.
👎🏻
물론 기존 방식들의 문제점이 가장 잘 드러나는 태스크가 번역이라서 그랬을 것이라는 생각이 들긴 하지만, 모델의 성능을 너무 제한적으로 검증한 것이 아닌가 생각이 들었습니다.
더 다양한 태스크와 데이터셋을 토대로 기존의 한계점을 극복할 수 있었다는 것을 보여주었다면 훨씬 더 신뢰가 가는 내용이 되었을 것이라고 생각합니다.
특히 layer의 수, 즉 모델의 깊이에 따른 실험을 통해 representation collapse 문제 등이 해결되었음을 보여주기도 했는데, 사실 문장의 길이에 따른 실험도 필요했다는 생각이 듭니다.
residual connection의 등장 배경에 이것이 가장 큰 비중을 차지하고 있기 때문이죠.
출처 : https://arxiv.org/abs/2304.14802
ResiDual: Transformer with Dual Residual Connections
Transformer networks have become the preferred architecture for many tasks due to their state-of-the-art performance. However, the optimal way to implement residual connections in Transformer, which are essential for effective training, is still debated. T
arxiv.org
'Paper Review' 카테고리의 다른 글
최근에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
Layer Normalization을 residual block의 앞과 뒤, 동시에 적용함으로써 pre/post 두 방식의 장점은 살리고 단점은 극복한 모델
- 배경
기존 NLP 모델들이 극복하지 못했던 long sequence에 대한 한계를 transformer의 아키텍쳐가 극복해냄으로써 NLP 분야는 눈부시게 발전했습니다.
문장이 길어지면서 전체적인 맥락을 고려하지 못하게 되는 상황이 아주 흔했는데, 이런 문제를 해결하기 위해서 sequence 앞 부분의 정보를 뒤쪽으로 전달하며 업데이트하는 방식이 등장했습니다.
BERT 계열의 모델들은 transformer 구조에서도 Layer Normalization(LM)을 이 residual block의 뒤에 적용하는 Post-LN 방식을 취했습니다.
반면 GPT 계열의 모델들은 LM을 residual block의 앞에 적용하는 Pre-LN 방식을 취했습니다.
두 방식은 각각 layer가 깊어짐에 따라 Gradient Vanishing, Representation Collapse 문제가 발생한다는 한계가 있습니다.
본 논문에서는 Post/Pre LN 방식을 동시에 적용하며 두 방식의 문제점인 Gradient Vanishing, Representation Collapse를 해결하고 성능을 끌어올리는 모델을 제시합니다.
- 컨셉
빨간색으로 표시된 LM이 적용되는 위치를 눈여겨 볼 필요가 있습니다.
ResiDual 방식에서는 기존의 Post, Pre 방식에서의 결과를 합쳐서 y를 도출하는 것을 볼 수 있습니다.
본 논문에서는 기존 방식의 문제점으로 지적했던 것들이 ‘수식적’으로도 해결되었음을 입증하고, 이를 경험적인 결과로도 보여줍니다.
이부분은 내용이 굉장히 복잡하고 어려워서 저도 이해하지 못한 내용들이 많았는데요, 좀 더 자세히 알아보고 이해를 하고 싶으신 분들은 논문 원본을 보시는 걸 추천드립니다.
(파악하기 어려운 수식들이 난무합니다 ㅎㅎ)
모델의 성능은 번역 태스크를 통해 검증되었고, 특히 warm-up과 같은 테크닉이 미치는 영향에 대해서도 확인한 것이 기록되어 있습니다.
- 개인적 감상
👍🏻
물론 이해도가 낮은 상태에서 이런 판단을 하면 안 되긴 하지만..
본인들의 주장을 논리적(수학적/수식적)으로 먼저 입증하고 이에 부합하는 실제 결과물을 제시한 것을 보고 아주 완성도가 높은 논문이라는 생각이 들었습니다.
지금까지 제가 봤던 정말 대부분의 페이퍼는 논란의 여지가 있을 수밖에 없는 내용 중 하나의 입장을 택하고 이를 경험적으로 입증하는 경우가 대부분이었습니다.
아주 간단한 예를 생각해본다면, 어떤 batch size가 최적일까에 대해 생각해본다면 여러 변수들에 따라 그 결과가 다를 것입니다.
하지만 본인들의 실험에서는 이런 조건 내에서 이것이 최적이었다, 라고 주장하는 것이 어떤 의미를 가질 수 있을까라는 생각을 항상했었습니다.
요즘 LLM과 관련된 키워드로 연결해본다면 일반화 성능이 떨어진다는 것이죠.
그러나 이 논문은 논리성을 갖춘 상태에서 결과까지 이를 확실하게 뒷받침하고 있는, 아주 좋은 구성으로 쓰인 논문이라는 생각이 들었습니다.
👎🏻
물론 기존 방식들의 문제점이 가장 잘 드러나는 태스크가 번역이라서 그랬을 것이라는 생각이 들긴 하지만, 모델의 성능을 너무 제한적으로 검증한 것이 아닌가 생각이 들었습니다.
더 다양한 태스크와 데이터셋을 토대로 기존의 한계점을 극복할 수 있었다는 것을 보여주었다면 훨씬 더 신뢰가 가는 내용이 되었을 것이라고 생각합니다.
특히 layer의 수, 즉 모델의 깊이에 따른 실험을 통해 representation collapse 문제 등이 해결되었음을 보여주기도 했는데, 사실 문장의 길이에 따른 실험도 필요했다는 생각이 듭니다.
residual connection의 등장 배경에 이것이 가장 큰 비중을 차지하고 있기 때문이죠.
출처 : https://arxiv.org/abs/2304.14802
ResiDual: Transformer with Dual Residual Connections
Transformer networks have become the preferred architecture for many tasks due to their state-of-the-art performance. However, the optimal way to implement residual connections in Transformer, which are essential for effective training, is still debated. T
arxiv.org