![]()
1. Exponentially Weighted Averages (지수 가중 평균) Temperature in London 영국의 1년 날씨를 날짜에 따라 표시한 그래프다. 전날과 오늘의 관계를 수식적으로 표현하여 그래프가 그려지는 양상을 예측하고자 한다. Exponentially weighted averages V_t 로 표현된 수식이 Exponentially wieghted averages에 대한 수식이다. 이는 과거의 비중(가중치)을 베타로 표현하고 오늘의 비중을 세타로 표현하고 있다. 따라서 베타가 아주 큰 경우에는 과거의 기록을 더 많이 반영하게 되므로 그래프가 완만한 초록색 선으로 표현된다. 대신 말 그대로 과거의 기록을 더 많이 반영하기 때문에 실제 데이터보다는 약간 우측에 치우치게 된다. 반..
![]()
1. Mini-batch Gradient Descent Match vs. mini-batch gradient descent 많은 양의 데이터를 처리해야 하는 딥러닝은 연산 시간을 줄이는 여러 기법들이 필요하다. 그 중 하나가 여러 데이터를 일부씩 묶어 계산하는 방식인 mini-batch gradient descent이다. 만약 처리해야 하는 데이터의 개수가 5,000,000개라면 어떻게 될까? 이 많은 양의 데이터를 한꺼번에 forward하고 backward 하는 것은 엄청난 computing power를 필요로 할 것이고, 이것이 뒷받침된다고 하더라도 썩 좋은 시간적 효율을 보이진 못할 것이다. 따라서 우리는 이를 일정 개수(위 예에서는 1,000개)씩 묵어서 연산을 시도하기로 한다. 이때 묶인 각 b..
![]()
1. Practical aspects of Deep Learning (Quiz) examples의 수에 따라 train/dev/test set을 어떤 비율로 split 해야 하는가? 10,000개 정도로 작을 경우 : 60/20/20 20,000,000개 정도로 많을 경우 : 99/0.5/0.5 training, test set은 같은 source로부터 구해진 것을 사용해야 한다. 그렇지 않을 경우 학습이 제대로 이루어지지 않는다. 'high bias' 문제가 있는 경우 hidden layer 숫자를 늘려(deeper network) 해결을 시도할 수 있다. 'high variance' 문제의 경우 더 많은 train data를 확보하거나 regularization을 시도할 수 있다. Data augme..
![]()
4. Numerical Approximation of Gradients Checking your derivative computation 미분의 정의를 통해 접선의 기울기를 계산하는 과정을 이해해보자. x = θ일 때 아주 작은 값 ε = 0.01을 더하고 빼서 함수값을 구해본다. 본래 기울기는 'y의 변화량 / x의 변화량' 이므로 {f(θ+ε) - f(θ-ε)} / 2ε 이 기울기가 된다. 이는 함수 f(θ) = θ^3을 미분하여 구한 g(θ) = 3θ^2와 근사한 결과다. 실제 값을 대입해보면 미분값이 3.0001로 기존 도함수 g를 통해 구한 3과 0.0001 차이가 나는 것을 알 수 있다. 계산은 이와 같은 방식으로 이뤄진다. 이때의 error는 O(ε^2)로 표현된다. 이를 기존 미분 정의와 ..
![]()
1. Normalizing Inputs Normalizing training sets x = [x1, x2] feature로 구성된 training set의 분포를 살펴보자. 우선 모든 x를 x의 mean(평균)만큼 빼준다(subtract). 그러면 두 번째 그림처럼 x1 feature 축에 대해 분포가 정렬된다. 다음으로는 x의 분산을 구해 x 전체를 분산으로 나눠준다. 이때 이미 평균을 뺀 값이므로 x 제곱의 평균을 구하는 것이 바로 분산이 된다. (분산을 구하는 기존 식은 'x-m' 제곱의 평균을 구하는 것이기 때문) 그러면 마지막 그림처럼 분산을 반영한 분포로 변형된다. 이러한 변형을 train set에 대해 적용했다면 test set에도 동일한 평균과 분산값으로 변형을 해줘야 한다. 즉, 두 s..
![]()
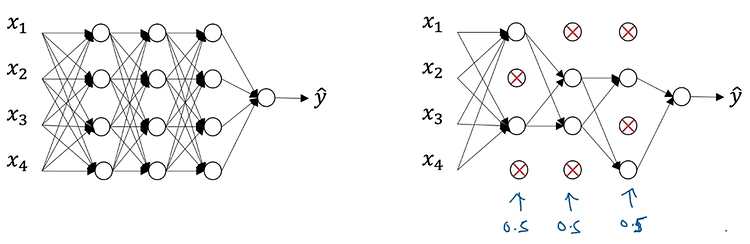
1. Regularization Logistic regression High variance 문제가 있을 때 데이터를 늘리기 어려운 상황이라면 regularization을 적용할 수 있다. loss function으로 구한 cost function J를 최소화하는 logistic regression을 예시로 들어 내용을 살펴보자. 기존의 logistic regression에서는 J가 prediction과 target 간의 차이를 평균낸 것으로 정의된다. 여기에 lambda라는 일종의 hyper parameter와 전체의 개수 m으로 나눠준 값을 계수로 갖는 L2 norm을 곱한 값을 더해준다. 쉽게 말하면 '특정 계수와 L2 norm을 곱한 값의 평균'을 더해준다는 것이다. 이때 두 변수 w와 b에 대해..