1. Normalizing Inputs Normalizing training sets x = [x1, x2] feature로 구성된 training set의 분포를 살펴보자. 우선 모든 x를 x의 mean(평균)만큼 빼준다(subtract). 그러면 두 번째 그림처럼 x1 feature 축에 대해 분포가 정렬된다. 다음으로는 x의 분산을 구해 x 전체를 분산으로 나눠준다. 이때 이미 평균을 뺀 값이므로 x 제곱의 평균을 구하는 것이 바로 분산이 된다. (분산을 구하는 기존 식은 'x-m' 제곱의 평균을 구하는 것이기 때문) 그러면 마지막 그림처럼 분산을 반영한 분포로 변형된다. 이러한 변형을 train set에 대해 적용했다면 test set에도 동일한 평균과 분산값으로 변형을 해줘야 한다. 즉, 두 s..
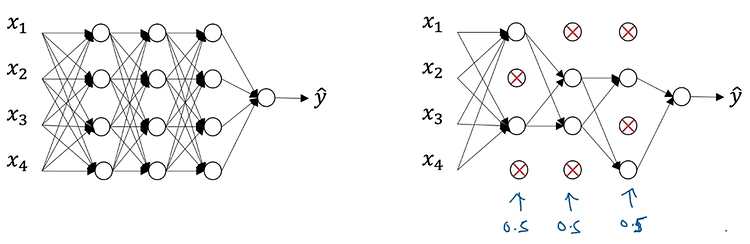
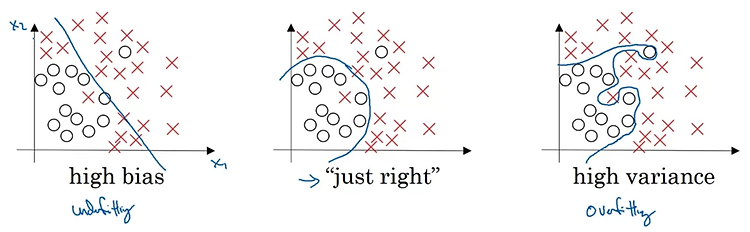
1. Regularization Logistic regression High variance 문제가 있을 때 데이터를 늘리기 어려운 상황이라면 regularization을 적용할 수 있다. loss function으로 구한 cost function J를 최소화하는 logistic regression을 예시로 들어 내용을 살펴보자. 기존의 logistic regression에서는 J가 prediction과 target 간의 차이를 평균낸 것으로 정의된다. 여기에 lambda라는 일종의 hyper parameter와 전체의 개수 m으로 나눠준 값을 계수로 갖는 L2 norm을 곱한 값을 더해준다. 쉽게 말하면 '특정 계수와 L2 norm을 곱한 값의 평균'을 더해준다는 것이다. 이때 두 변수 w와 b에 대해..
1. Train / Dev/ Test sets Applied ML is a highly iterative process ML은 다양한 분야에 적용되고 있다. NLP, CV, Speech Recognitoin, 등.. 그러나 어떤 분야든지간에 Model에 대한 적합한 hyper parameter를 한 번에 구할 수는 없다. 전문가라 하더라도 위와 같은 cycle을 반복적으로 돌리면서 모델을 적절히 변경할 수 있게 되는 것이다. Train/dev/test sets 우리는 전체 데이터셋을 흔히 train/dev/test 셋으로 나눈다. train셋에서는 말 그대로 학습을 진행하고, dev셋에서는 우리가 학습시킨 알고리즘과 다른 알고리즘을 cross하여 비교할 수 있으며 test셋에서는 최고의 성능을 보였던 모..