![]()
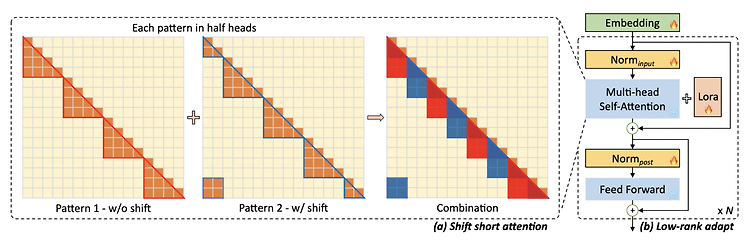
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [MIT] 사전학습된 LLM의 context size를 확장하는 efficient fine-tuning 기법, LongLoRA. sparse local attention 방식 중 하나로 shift shoft attention(S^2-Attn)를 제안하고, trainable embedding & normalization을 통해 computational cost를 대폭 줄이면서도 기존 모델에 준하는 성능을 보임. Fine-tugning을 위한 3K 이상의 long context question-answer pair dataset, Lon..
![]()
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Meta AI] LLM의 hallucination을 줄이기 위한 방법으로 Chain-of-Verification, CoVe를 제안. CoVe는 네 개의 단계로 구성됨. 배경 LLM이 사실이 아닌 것을 마치 사실처럼 표현하는 현상인 hallucination 문제가 심각하다는 것은 이미 잘 알려져 있습니다. 이 현상을 최소화하고자 하는 연구들도 많이 이뤄지고 있구요. 이러한 시도들을 크게 'training-time correction', 'generation-time correction', 'via augmentation'으로 구분할 ..
![]()
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success 비전문가 유저도 쉽게 이용할 수 있는 autonomous agent 제작 프레임워크, AGENTS. planing, memory, tool usage, multi-agent communication, fine-grained symbolic control 등의 기능을 포함. 배경 최근에는 LLM의 능력을 이용하여 autonomous language agent를 만드는 연구 또한 활발히 이뤄지고 있습니다. 이를 접목시키기 가장 쉬운 분야를 떠올린다면 게임의 npc가 될 수 있겠죠. 스스로 주변 환경을 인식하고, 사고하고, 판단하고, 행동..
![]()
예전(2020.10)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Google Reserach, Brain Team] image patch의 sequence에 pure transformer를 적용하여 image classification을 수행. 타 모델 대비 적은 computational resource를 요하면서도 우월한 성능을 보임. 배경 transformer가 등장하며 NLP를 집어 삼키게 된 이후로, 이 아키텍쳐를 이미지 분야에 적용하고자 하는 여러 시도들이 있었습니다. 각 픽셀을 대상으로 self-attention을 적용하거나 지엽적으로 self-attention을 적용하는 등의 접근이..
![]()
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [University of Sydney] 추가 데이터나 fine-tuning 없이 frozen LLM을 align. self-evaluation과 rewind mechanism을 활용. 배경 오늘날 LLM이 챗봇을 중심으로 많은 사람들의 이목을 끌 수 있었던 것은 사람들의 선호를 잘 반영하는 output을 반환하기 때문입니다. 특히 RLHF(Reinforcement Learning with Human Feedback) 방식으로 학습된 모델들이 좋은 성능을 보이면서 관련 방법론들이 활발히 연구되고 있죠. 하지만 아직까지도 사람의 선호를..
![]()
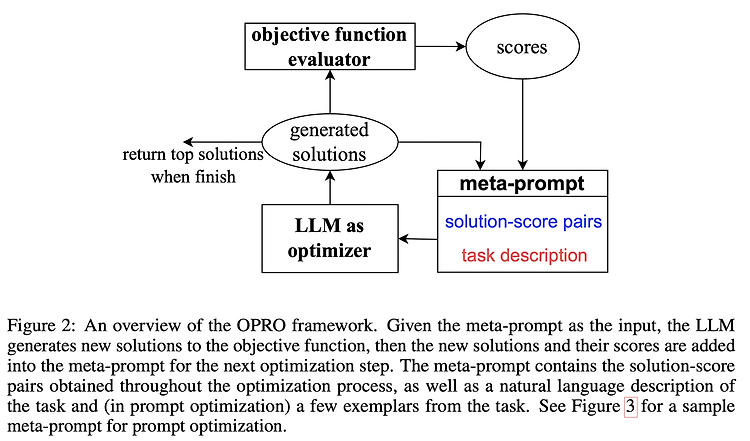
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Google DeepMind] LLM에 대해 Prompting 기술을 활용하여 Optimization 하는 OPRO를 제안. Linear Regression, Traveling Salesman Problem / GSM8K, Big-Bench Hard Task 배경 원래 optimization, 최적화라고 하면 주어진 문제를 풀기 위해 정의된 objective fuction에 대한 최적화를 뜻합니다. 목표로 설정한 함수를 최적화하는 것은 solution을 반복적으로 업데이트함으로써 달성됩니다. 지금까지는 어떤 방식으로 solution..