![]()
데이콘을 통해 운영되는 LG Aimers 3기 해커톤이 지난 주말(23.09.16~23.09.17) 간 오프라인으로 진행되었습니다. 올해 초에 진행되었던 2기 때에도 열정적인 참가자분들이 많아 너무 좋았다는 이야기를 들었어서 개인적으로 굉장히 기대가 되는 행사였어요! 손꼽아 기다리고 있었는데, 막상 금요일이 되니까 주말 출근이 너무 하기 싫어서 마음이 무거웠습니다 😇 저도 이 분야에 입문한지 오래되지 않은 뉴비로서 이런 오프라인 해커톤에 참여해보고 싶다고 생각해왔는데 스탭으로 참여하게 될 줄은 정말 꿈에도 몰랐네요 😳 ㅋㅋㅋㅋ 그래도 저에게도 굉장히 값지고 재밌는 시간이었어서 다녀온 후기를 좀 공유해보고자 합니다! 참고로 LG Aimers 공식 홈페이지에서 정보 확인하실 수 있고, 아마 이 상태라면 4기..
![]()
최근(2023.03)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Microsoft Research / Azure AI] DeBERTa의 MLM을 RTD로 대체하고, 새로운 gradient-disentangled embedding sharing 방식을 적용. multilingual 모델 mDeBERTaV3도 개발. 배경 지난 번에 소개한 모델 DeBERTa는 relative position을 더 잘 반영하는 disentangled attention과 absolute position을 반영하는 enhanced mask decoder(EMD)을 주요 특징으로 내세웠습니다. 본 논문에서 DeBERTa는..
![]()
과거(2020.06)에 나온 논문을 읽어보고 간단히 정리했습니다. 캐글 프로젝트를 하면서 이 모델에 대해 공부를 한 번 하고 싶어서 빠르게 읽고 간단히 정리한 내용입니다! (버전 3가 올해에 나와 있어서 그것도 얼른 공부를 해야 될 것 같네요) 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Microsoft Research] disentangled attention mechanism과 enhanced mask decoder라는 새로운 기법을 적용. 기존 BERT 및 RoBERTa 모델의 단점을 개선한 새로운 architecture, DeBERTa를 제시. 배경 당시(2020년도)에는 self-attention을 기반으로 한 여러 모델들이 쏟아..
![]()
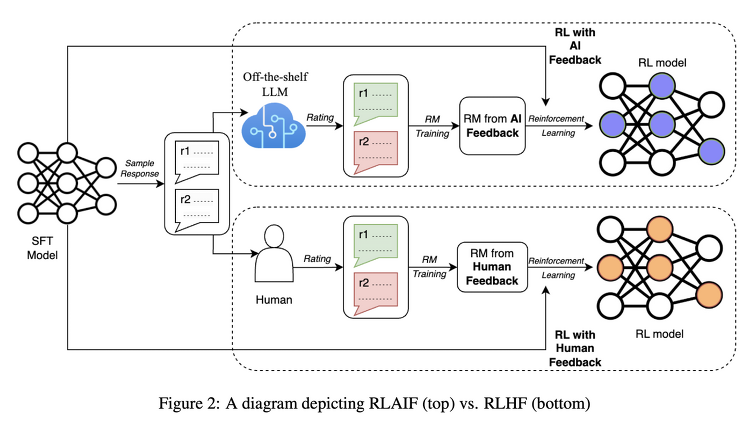
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Google Research] LLM을 요약 태스크에 대해 학습시킬 때 반영하는 '사람'의 선호 대신 'AI'의 선호를 반영하는 RLAIF 배경 ChatGPT와 같은 LLM들이 주목을 받게 된 데 가장 큰 기여를 한 것은 RLHF(Reinforcement Learning with Human Feedback)이라고 해도 과언이 아닐 것입니다. reward 모델이 사람의 선호를 학습하고, 이를 바탕으로 언어 모델을 추가 학습하는 방식입니다. 그런데 이러한 방식 역시 사람의 선호를 나타낼 수 있는 pair 데이터셋이 필요하기 때문에, L..
![]()
최근(2023.06)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Microsoft] Evol-Instruct 데이터셋을 StarCoder 모델에 fine-tuning한 모델 WizardCoder. 모든 Open Source 모델을 압도, 여러 Closed Source 모델보다 우위. 먼저 읽으면 좋은 논문 : https://chanmuzi.tistory.com/378 배경 LLM이 학습하는데 도움을 주는 instruction dataset을 구축하기 위한 방법으로 제안된 Evol-Instruct를 Code 모델에 특화시키는 방식을 제안하고 있습니다. 위 링크의 요약을 확인해보시면 어떤 방식으로 ..
![]()
최근(2023.04)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Microsoft] 대량의 instruction data를 생성하는 방법론 Evol-Instruct을 제시. 이를 이용해 생성한 데이터셋으로 fine-tuning한 모델 WizardLM이 Alpaca, Vicuna를 압도. 배경 LLM이 instruction data를 활용하는 경우, 그 성능이 눈에 띄게 좋아진다는 것은 잘 알려져 있습니다. 우리에게 익숙한 ChatGPT도 이를 적극적으로 잘 활용하여 학습된 모델이죠. 예전에는 instruction data라고 해봤자, 특정 도메인에 한정되고(closed-domain) 아주 간단한..