![]()
관심 있는 NLP 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Google DeepMind] - RNN과 gated linear recurrence를 결합한 Hawk, gated linear recurrence와 local attention을 결합한 Griffin을 제안 - Hawk는 특정 태스크에서 Mamba 수준의 성능을, Griffin은 Llama-2 수준의 성능을 보임. 특히 후자의 경우 학습 당시에 접한 텍스트 보다 긴 데이터에 대해서도 뛰어난 성능을 보임. - 두 모델은 Transformers 대비 hardward efficient하며 lower latency & higher throughpu..
![]()
관심 있는 NLP 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Google DeepMind] - Gemini를 만들 때 사용했던 기술들을 바탕으로 학습된 lightweight & state-of-the art open models, Gemma를 공개 - language understanding, reasoning, safety 등 벤치마크에서 뛰어난 퍼포먼스를 보임 - 2B & 7B 모델의 raw version과 instruction fine-tuned version을 공개 (2T & 6T 토큰으로 학습) 출처 : https://storage.googleapis.com/deepmind-media/gemm..
![]()
관심있는 NLP 논문을 읽어보고 ChatGPT를 이용하여 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success Abstract 대규모 언어 모델(Large Language Models, LLMs)은 양적 추론부터 자연어 이해에 이르기까지 복잡한 작업을 수행하는 능력을 보여주었으나, 때때로 사실이 아닌 설득력 있는 진술(환각)을 만들어내는 문제가 있음. 현재 대규모 모델의 과학적 발견에서의 사용을 제한하는 이러한 문제를 해결하기 위해, 사전 훈련된 LLM과 체계적인 평가자를 결합한 진화적 절차인 'FunSearch'를 소개함. FunSearch는 중요한 문제에서 최고의 결과를 뛰어넘는 효과를 입증하며, 대규모 LLM 기반 접근법의 한계를 ..
![]()
관심있는 NLP 논문을 읽어보고 ChatGPT를 이용하여 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Google DeepMind, Google Research] Abstract 주요 내용: 이 논문은 인간의 선호도에 맞춰 대규모 언어 모델(Large Language Model, LLM)의 출력 품질을 향상시키기 위해 인간 피드백으로부터의 강화학습(Reinforcement Learning from Human Feedback, RLHF) 방법을 제안합니다. 제안하는 알고리즘의 이름은 Reinforced Self-Training (ReST)이며, 이는 강화학습(Reinforcement Learning, RL)의 성장 배치 방식에 ..
![]()
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Google DeepMind, Stanford University, University of California, Berkeley] - LM의 code-driven reasoning 능력을 향상시켜주는 간단하면서도 효과적인 extension, Chain of Code (CoC) 공개 - 실행 가능한 코드는 interpreter로 실행해보고, 그럴 수 없는 것은 LM을 활용하여 emulate하는 방식, LMulator 도입 1. Introduction 복잡한 문제를 여러 세부 태스크로 쪼개어 처리하는 Chain of Thought (CoT) 방식..
![]()
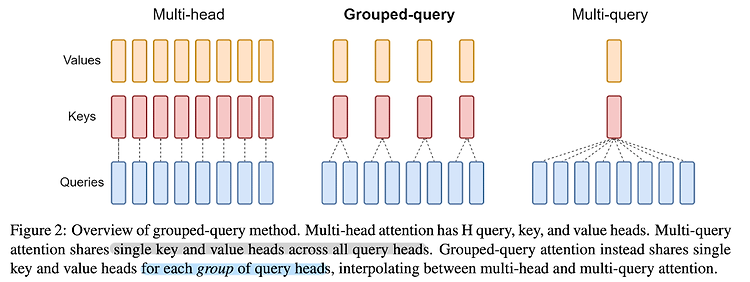
최근(2023.10)에 나온 논문들을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints (2023.05) [Google Research] Multi-head Attention(MHA)만큼의 품질이 보장되고, Multi-query Attention(MQA)만큼의 속도를 낼 수 있는 Group-query Attention(GQA)를 제안 기존 Transformer 아키텍쳐에서 사용되는 Multi-head Attention의 경우 메모리 사용량이 지나치게 많이 요구되어 이를 적용하기가 점점 더 어려워지는 추세였음 이..