
관심 있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Google DeepMind]
- Gemini를 만들 때 사용했던 기술들을 바탕으로 학습된 lightweight & state-of-the art open models, Gemma를 공개
- language understanding, reasoning, safety 등 벤치마크에서 뛰어난 퍼포먼스를 보임
- 2B & 7B 모델의 raw version과 instruction fine-tuned version을 공개 (2T & 6T 토큰으로 학습)
출처 : https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf
1. Introduction
최근 OpenAI의 Sora, Google의 Gemini-1.5 등 엄청나게 많은 소식들이 쏟아지고 있는데요..!
그 와중에 구글 딥마인드에서 2B/7B 사이즈의 오픈소스 모델을 내놓았습니다.
(발전 속도 정말 어지럽다 ㅜㅜ)
뭐 완벽한 오픈소스라고 보기는 어렵지만 API로 공개하지 않고 모델의 가중치와 추론 및 서빙을 위한 코드베이스를 공개한 것 자체가 대단하네요.
논문에는 구글이 꾸준히 오픈소스 생태계에 기여했다는 내용이 있어서 처음에 뭐지..? 싶었는데 언급한 모델들을 보고 납득했습니다.
Word2Vec, Transformer, BERT, T5, T5X 등.. 이제는 Gemma까지..!
사실상 구글이 없었으면 인공지능 발전이 없었던 것 아닌가 싶을 정도의 라인업이네요 ㅋㅋㅋ
여튼 오늘은 Gemma의 technical report에 적힌 내용들을 정리해보고자 합니다.
디테일한 논리나 원리에 대해서는 당연히 기재가 되어있지 않으므로 정보 요약이 포스팅의 주된 목적이라고 생각해 주시면 좋을 것 같습니다.
2. Model Architecture
Gemma 역시 transformer decoder 기반의 모델입니다.
요즘엔 그렇지 않은 모델들을 거의 보지 못하는 기분도 드네요.
모델의 하이퍼 파라미터 관련 정보는 아래와 같습니다.
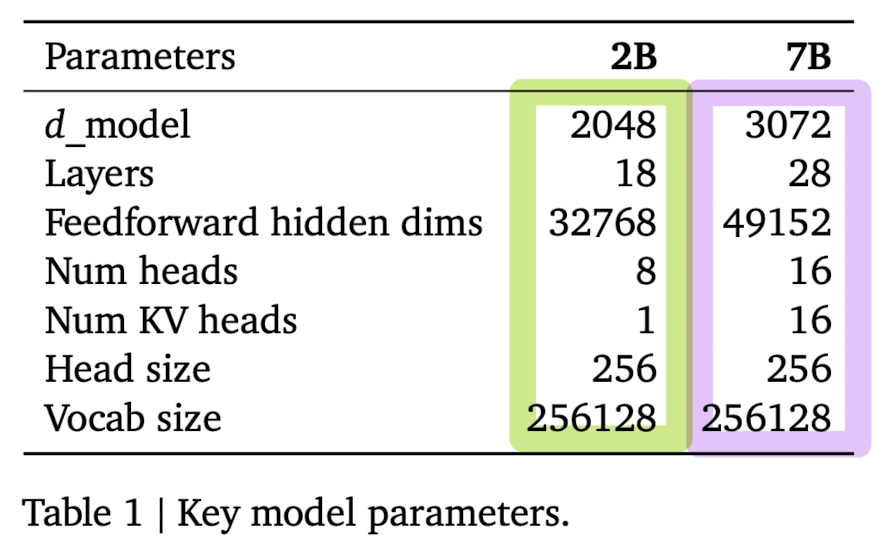

참고로 모델들은 8192개 토큰의 context 길이를 바탕으로 학습되었다고 합니다.
- Multi-Query Attention
- 2B 모델은 multi-query attention을 사용했습니다. 그래서 $num_kv_heads$의 값이 1이죠.
- 이와 달리 7B 모델은 일반적인 multi-head attention을 사용했습니다.
- RoPE Embeddings
- input과 output의 embedding을 공유하여 모델의 사이즈를 줄였다고 합니다. 위 표에서 embedding parameters를 확인해 보면 왜 이렇게 했는지 납득이 되는 것 같습니다.
- GeGLU Activations
- Normalizer Location
- transformer sub-layer의 앞에서 normalize를 해야되냐 뒤에서 해야 되냐 말이 많은데, 여기서는 앞 & 뒤 둘 다 적용한다고 합니다.
- 이때 사용된 것은 RMSNorm 입니다.
3. Training Infastructure
256개의 chip이 장착된 TPUv5e라는 pod을 사용했다고 합니다.
7B 모델의 경우 4096개 / 2B 모델의 경우 512개의 TPUv5e를 사용했다고 하네요.. 🤯
나머지는 키워드로 중심으로 간단히 리스트를 보여드릴게요.
- ZeRO-3
- single controller programming paradigm of Jax
- Pathways
- GMSMD partitioner
- MegaScale XLA compiler
4. Pretraining & Instruction Tuning
- Training Data
- 7B 모델의 경우 6T 토큰 / 2B 모델의 경우 2T 토큰으로 학습되었다고 합니다.
- 이때 web documents, mathematics, code 데이터 중에서 영어로 된 것만을 사용했다고 해요.
- Gemini의 SentencePiece tokenizer를 사용했는데 조금 독특하게도 256k tokens의 vocab이 형성된다고 합니다.
전형적인 LLM 학습 순서와 동일합니다.
(1) text only 데이터에 대해 supervised fine-tuning (SFT)를 진행하고
(2) reward 모델을 기반으로, synthetic & human generated prompt-response pairs에 대해 강화 학습을 진행합니다.
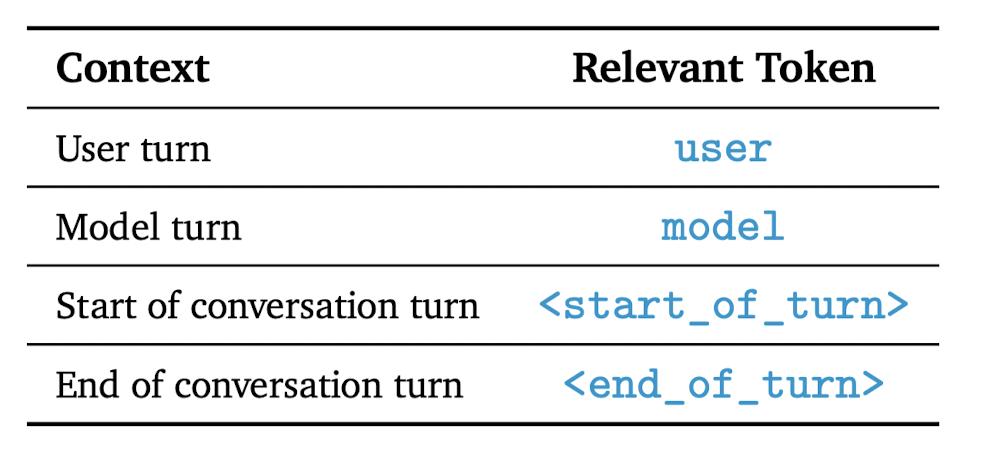
instruction 단계에서는 conversation 내의 역할을 알려주는 Relevant Token을 사용했다고 해요.
토큰 정보와 관련 예시는 아래 이미지를 참고해 주세요.

5. Evaluation
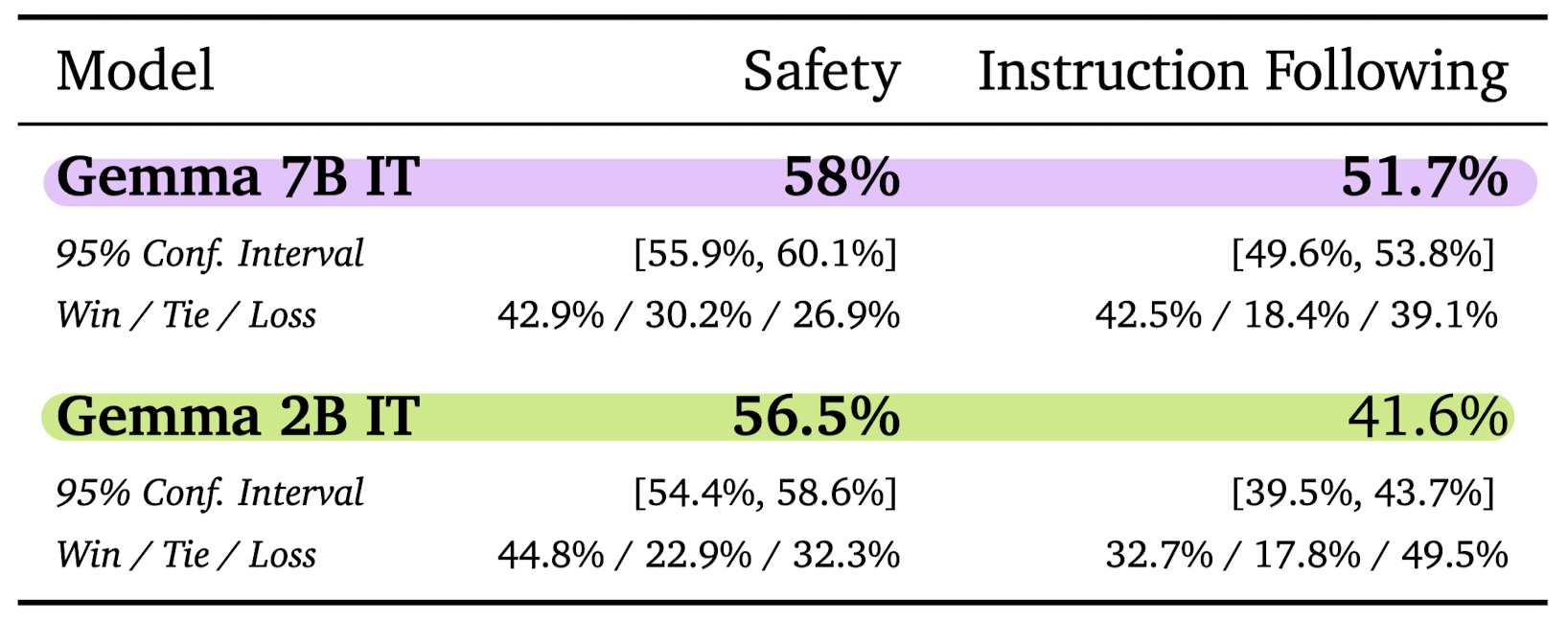
- Human Preference Evaluations
- Mistral v.0.2 7B Instruct 모델과 결과를 비교했습니다.
- 전반적으로 7B 모델이 2B 모델에 비해 좋은 성과를 낸 것을 알 수 있습니다.
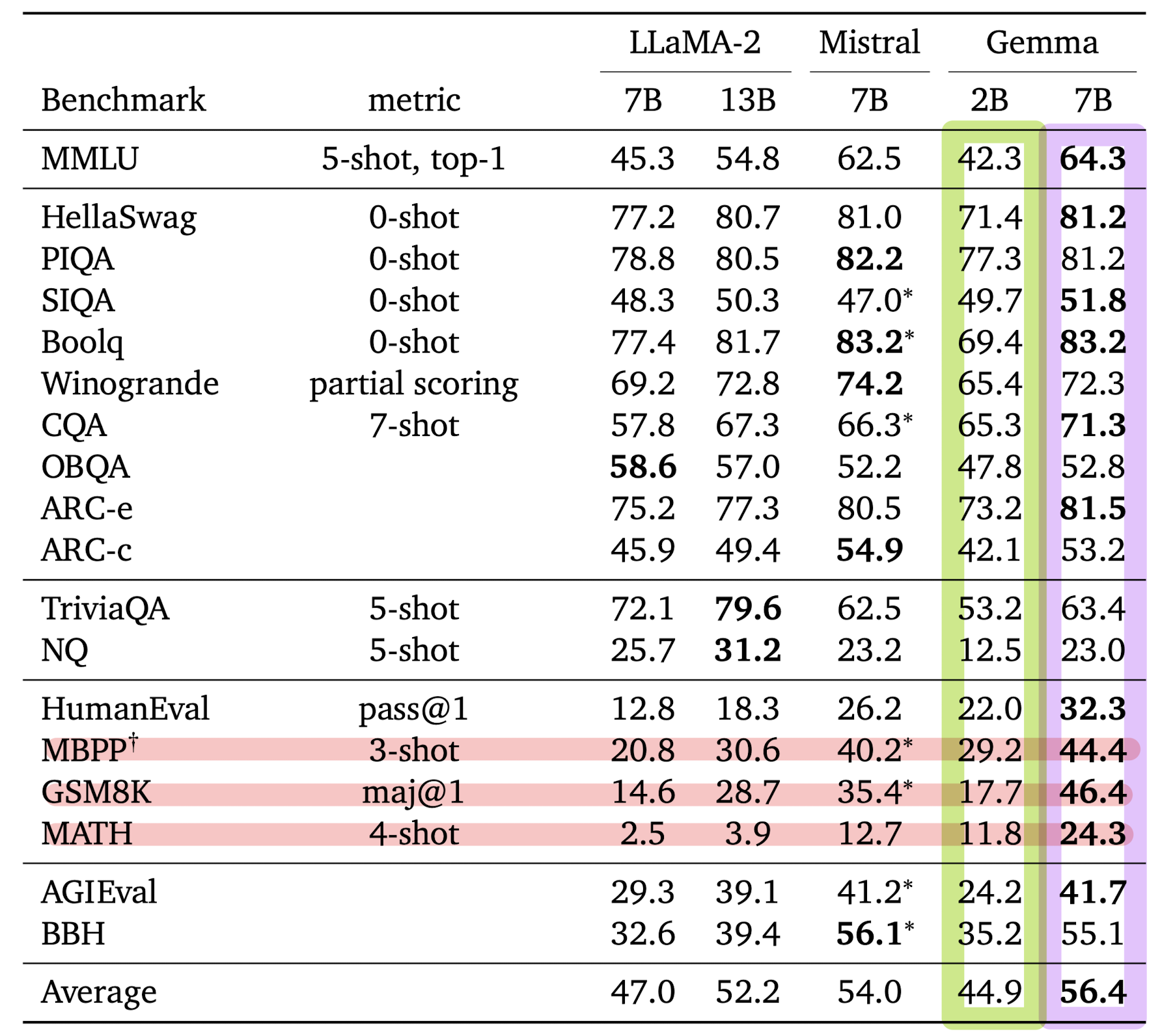
- Automated Benchmarks
- physical reasoning, social reasoning, question answering, coding, mathematics, commonsense reasoning, language modeling, reading comprehension 등의 domain에 대해 모델 성능을 평가했다고 합니다.
- 사용한 벤치마크는 CommonsenseQA, Big Bench Hard, AGI Eval (English-only), MMLU라고 합니다.
- 특히 mathematics and coding에 대해 강점을 보여주었습니다. 총결과는 아래 표에 제시되어 있습니다.
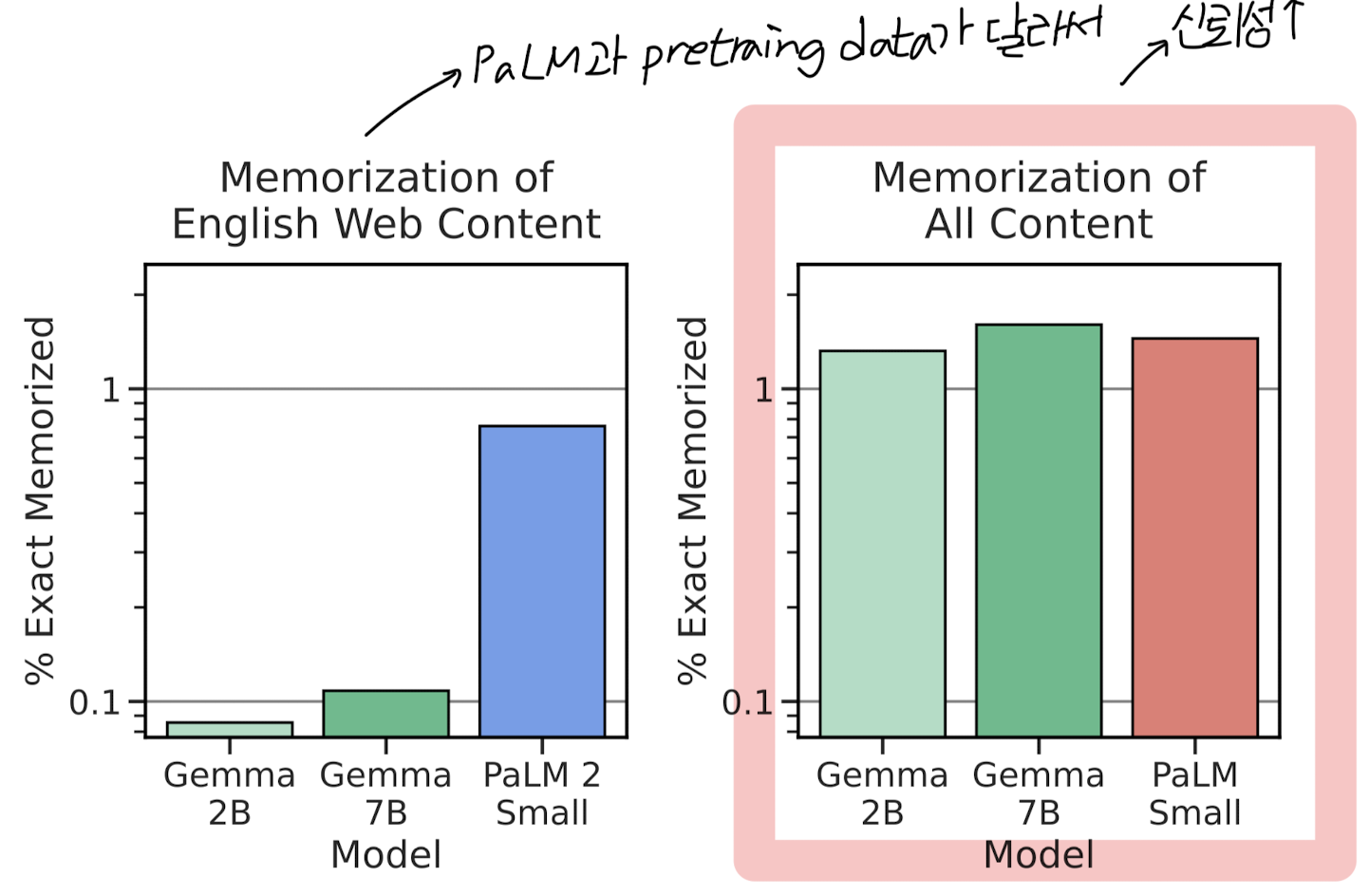
- Memorizatoin Evaluations
- aligned 모델이 adversarial attack에 대해 얼마나 취약한지를 확인한 결과입니다.
- 아래 그래프 중 왼쪽은 Gemma와 PaLM의 사전 학습 데이터가 달라서 크게 의미가 없다고 밝혔습니다.
- 대신 오른쪽의 그래프를 보면 Gemma가 PaLM 모델 (유사한 사이즈)과 유사한 memorization 수준을 갖는다는 것을 알 수 있습니다.
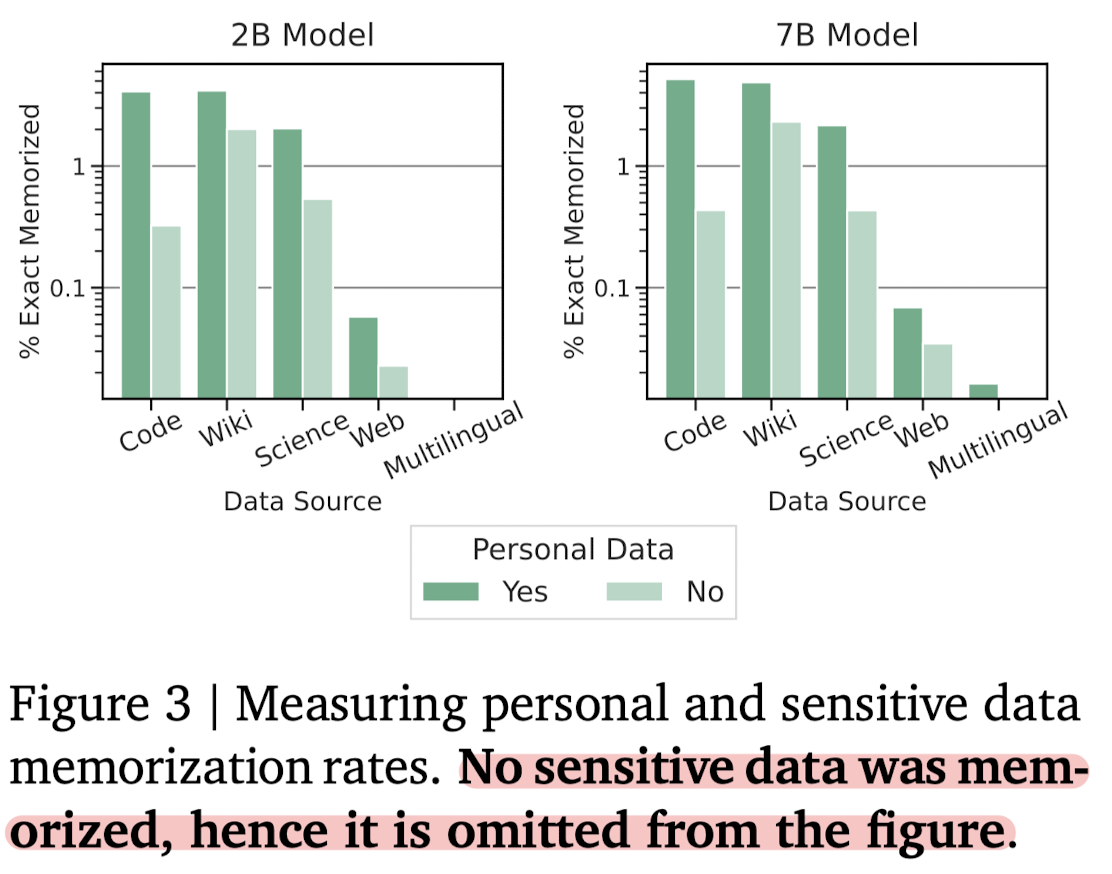
- Personal Data
- Google Cloud Data Loss Prevention (DLP) tool을 사용하여 개인 정보나 민감한 데이터가 포함되어 있는지 테스트한 결과입니다.
- 저자에 따르면 민감한 데이터는 '아예' 존재하지 않아서 그래프에 포함하지 않았다고 합니다.
- 오히려 수많은 false positives (민감한 데이터가 아닌데도 과하게 걸러낸 케이스 ㅋㅋ)가 많다고 강조합니다.
6. Responsible Deployment
- Benefits
- 구글이 지금까지 연구 분야에서 엄청나게 많은 헌신과 공헌을 해왔음을 다시 강조합니다. (Transformer, BERT, T5 등등..)
- 이렇게 AI 모델을 투명하게 공개하는 것이 가져다 줄 이익이 위험 대비 훨씬 크다는 점을 언급했습니다.
- Risks
- LLMs의 악의적인 사용에 대해 경계합니다. 특히 API가 아닌 모델 weight를 공개하여 추가 학습이 가능하도록 하는 경우, malicious intent를 반영한 데이터를 학습하여 악용할 가능성이 있다는 점에 대해서 언급했습니다.
(확실히 요즘 딥페이크 사기도 많고.. 중요한 이슈라는 생각이 듭니다) - 또한 당연하게도 LLM이 원래 의도되지 않았던 대로 결과를 반환할 가능성도 있습니다. 예를 들면 성별/인종/지역 등에 편향적인 발언을 할 수도 있습니다.
- 특히 한 번 공개가 된 건에 대해서는 무를 수 없다(irreversible)는 점이 가장 큰 risk라고 볼 수 있겠습니다.
- LLMs의 악의적인 사용에 대해 경계합니다. 특히 API가 아닌 모델 weight를 공개하여 추가 학습이 가능하도록 하는 경우, malicious intent를 반영한 데이터를 학습하여 악용할 가능성이 있다는 점에 대해서 언급했습니다.
- Mitigations
- 가장 핵심적인 대책 방법은 결국 사전 학습 데이터를 filtering 하는 것입니다. 논문에서 반복적으로 언급하고 있는 내용이기도 하고.. 개인적으로는 할 만큼 다 한 것 같네 싶은 느낌을 받긴 했습니다.
- Generative AI Responsible Toolkit을 함께 공개하여 개발자들이 AI responsibility를 함께 세워나갈 수 있도록 했다고 합니다.
'Paper Review' 카테고리의 다른 글
관심 있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Google DeepMind]
- Gemini를 만들 때 사용했던 기술들을 바탕으로 학습된 lightweight & state-of-the art open models, Gemma를 공개
- language understanding, reasoning, safety 등 벤치마크에서 뛰어난 퍼포먼스를 보임
- 2B & 7B 모델의 raw version과 instruction fine-tuned version을 공개 (2T & 6T 토큰으로 학습)
출처 : https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf
1. Introduction
최근 OpenAI의 Sora, Google의 Gemini-1.5 등 엄청나게 많은 소식들이 쏟아지고 있는데요..!
그 와중에 구글 딥마인드에서 2B/7B 사이즈의 오픈소스 모델을 내놓았습니다.
(발전 속도 정말 어지럽다 ㅜㅜ)
뭐 완벽한 오픈소스라고 보기는 어렵지만 API로 공개하지 않고 모델의 가중치와 추론 및 서빙을 위한 코드베이스를 공개한 것 자체가 대단하네요.
논문에는 구글이 꾸준히 오픈소스 생태계에 기여했다는 내용이 있어서 처음에 뭐지..? 싶었는데 언급한 모델들을 보고 납득했습니다.
Word2Vec, Transformer, BERT, T5, T5X 등.. 이제는 Gemma까지..!
사실상 구글이 없었으면 인공지능 발전이 없었던 것 아닌가 싶을 정도의 라인업이네요 ㅋㅋㅋ
여튼 오늘은 Gemma의 technical report에 적힌 내용들을 정리해보고자 합니다.
디테일한 논리나 원리에 대해서는 당연히 기재가 되어있지 않으므로 정보 요약이 포스팅의 주된 목적이라고 생각해 주시면 좋을 것 같습니다.
2. Model Architecture
Gemma 역시 transformer decoder 기반의 모델입니다.
요즘엔 그렇지 않은 모델들을 거의 보지 못하는 기분도 드네요.
모델의 하이퍼 파라미터 관련 정보는 아래와 같습니다.
참고로 모델들은 8192개 토큰의 context 길이를 바탕으로 학습되었다고 합니다.
- Multi-Query Attention
- 2B 모델은 multi-query attention을 사용했습니다. 그래서
- 이와 달리 7B 모델은 일반적인 multi-head attention을 사용했습니다.
- 2B 모델은 multi-query attention을 사용했습니다. 그래서
- RoPE Embeddings
- input과 output의 embedding을 공유하여 모델의 사이즈를 줄였다고 합니다. 위 표에서 embedding parameters를 확인해 보면 왜 이렇게 했는지 납득이 되는 것 같습니다.
- GeGLU Activations
- Normalizer Location
- transformer sub-layer의 앞에서 normalize를 해야되냐 뒤에서 해야 되냐 말이 많은데, 여기서는 앞 & 뒤 둘 다 적용한다고 합니다.
- 이때 사용된 것은 RMSNorm 입니다.
3. Training Infastructure
256개의 chip이 장착된 TPUv5e라는 pod을 사용했다고 합니다.
7B 모델의 경우 4096개 / 2B 모델의 경우 512개의 TPUv5e를 사용했다고 하네요.. 🤯
나머지는 키워드로 중심으로 간단히 리스트를 보여드릴게요.
- ZeRO-3
- single controller programming paradigm of Jax
- Pathways
- GMSMD partitioner
- MegaScale XLA compiler
4. Pretraining & Instruction Tuning
- Training Data
- 7B 모델의 경우 6T 토큰 / 2B 모델의 경우 2T 토큰으로 학습되었다고 합니다.
- 이때 web documents, mathematics, code 데이터 중에서 영어로 된 것만을 사용했다고 해요.
- Gemini의 SentencePiece tokenizer를 사용했는데 조금 독특하게도 256k tokens의 vocab이 형성된다고 합니다.
전형적인 LLM 학습 순서와 동일합니다.
(1) text only 데이터에 대해 supervised fine-tuning (SFT)를 진행하고
(2) reward 모델을 기반으로, synthetic & human generated prompt-response pairs에 대해 강화 학습을 진행합니다.
instruction 단계에서는 conversation 내의 역할을 알려주는 Relevant Token을 사용했다고 해요.
토큰 정보와 관련 예시는 아래 이미지를 참고해 주세요.
5. Evaluation
- Human Preference Evaluations
- Mistral v.0.2 7B Instruct 모델과 결과를 비교했습니다.
- 전반적으로 7B 모델이 2B 모델에 비해 좋은 성과를 낸 것을 알 수 있습니다.
- Automated Benchmarks
- physical reasoning, social reasoning, question answering, coding, mathematics, commonsense reasoning, language modeling, reading comprehension 등의 domain에 대해 모델 성능을 평가했다고 합니다.
- 사용한 벤치마크는 CommonsenseQA, Big Bench Hard, AGI Eval (English-only), MMLU라고 합니다.
- 특히 mathematics and coding에 대해 강점을 보여주었습니다. 총결과는 아래 표에 제시되어 있습니다.
- Memorizatoin Evaluations
- aligned 모델이 adversarial attack에 대해 얼마나 취약한지를 확인한 결과입니다.
- 아래 그래프 중 왼쪽은 Gemma와 PaLM의 사전 학습 데이터가 달라서 크게 의미가 없다고 밝혔습니다.
- 대신 오른쪽의 그래프를 보면 Gemma가 PaLM 모델 (유사한 사이즈)과 유사한 memorization 수준을 갖는다는 것을 알 수 있습니다.
- Personal Data
- Google Cloud Data Loss Prevention (DLP) tool을 사용하여 개인 정보나 민감한 데이터가 포함되어 있는지 테스트한 결과입니다.
- 저자에 따르면 민감한 데이터는 '아예' 존재하지 않아서 그래프에 포함하지 않았다고 합니다.
- 오히려 수많은 false positives (민감한 데이터가 아닌데도 과하게 걸러낸 케이스 ㅋㅋ)가 많다고 강조합니다.
6. Responsible Deployment
- Benefits
- 구글이 지금까지 연구 분야에서 엄청나게 많은 헌신과 공헌을 해왔음을 다시 강조합니다. (Transformer, BERT, T5 등등..)
- 이렇게 AI 모델을 투명하게 공개하는 것이 가져다 줄 이익이 위험 대비 훨씬 크다는 점을 언급했습니다.
- Risks
- LLMs의 악의적인 사용에 대해 경계합니다. 특히 API가 아닌 모델 weight를 공개하여 추가 학습이 가능하도록 하는 경우, malicious intent를 반영한 데이터를 학습하여 악용할 가능성이 있다는 점에 대해서 언급했습니다.
(확실히 요즘 딥페이크 사기도 많고.. 중요한 이슈라는 생각이 듭니다) - 또한 당연하게도 LLM이 원래 의도되지 않았던 대로 결과를 반환할 가능성도 있습니다. 예를 들면 성별/인종/지역 등에 편향적인 발언을 할 수도 있습니다.
- 특히 한 번 공개가 된 건에 대해서는 무를 수 없다(irreversible)는 점이 가장 큰 risk라고 볼 수 있겠습니다.
- LLMs의 악의적인 사용에 대해 경계합니다. 특히 API가 아닌 모델 weight를 공개하여 추가 학습이 가능하도록 하는 경우, malicious intent를 반영한 데이터를 학습하여 악용할 가능성이 있다는 점에 대해서 언급했습니다.
- Mitigations
- 가장 핵심적인 대책 방법은 결국 사전 학습 데이터를 filtering 하는 것입니다. 논문에서 반복적으로 언급하고 있는 내용이기도 하고.. 개인적으로는 할 만큼 다 한 것 같네 싶은 느낌을 받긴 했습니다.
- Generative AI Responsible Toolkit을 함께 공개하여 개발자들이 AI responsibility를 함께 세워나갈 수 있도록 했다고 합니다.