
Skip-grams
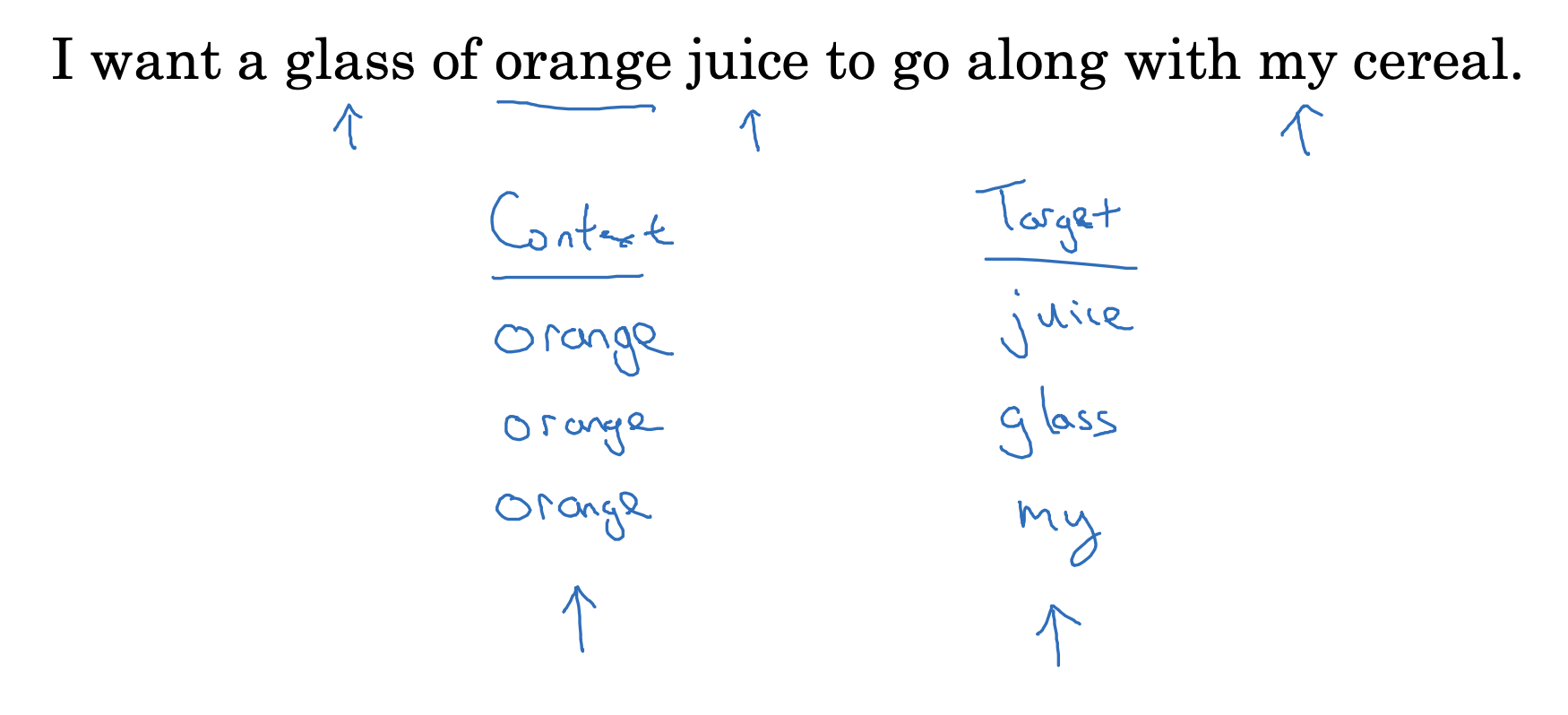
이번에는 Word2Vec 모델 중 하나인 skip-gram에 대해 다룹니다.
지금까지는 target 단어를 기준으로 context를 어떻게 설정하는지에 대해 주로 이야기했습니다.
하지만 여기서는 orange라는 하나의 context를 기준으로 랜덤하게(5개의 단어 +- 범위 내에서) target을 설정한 것을 볼 수 있습니다.
Model
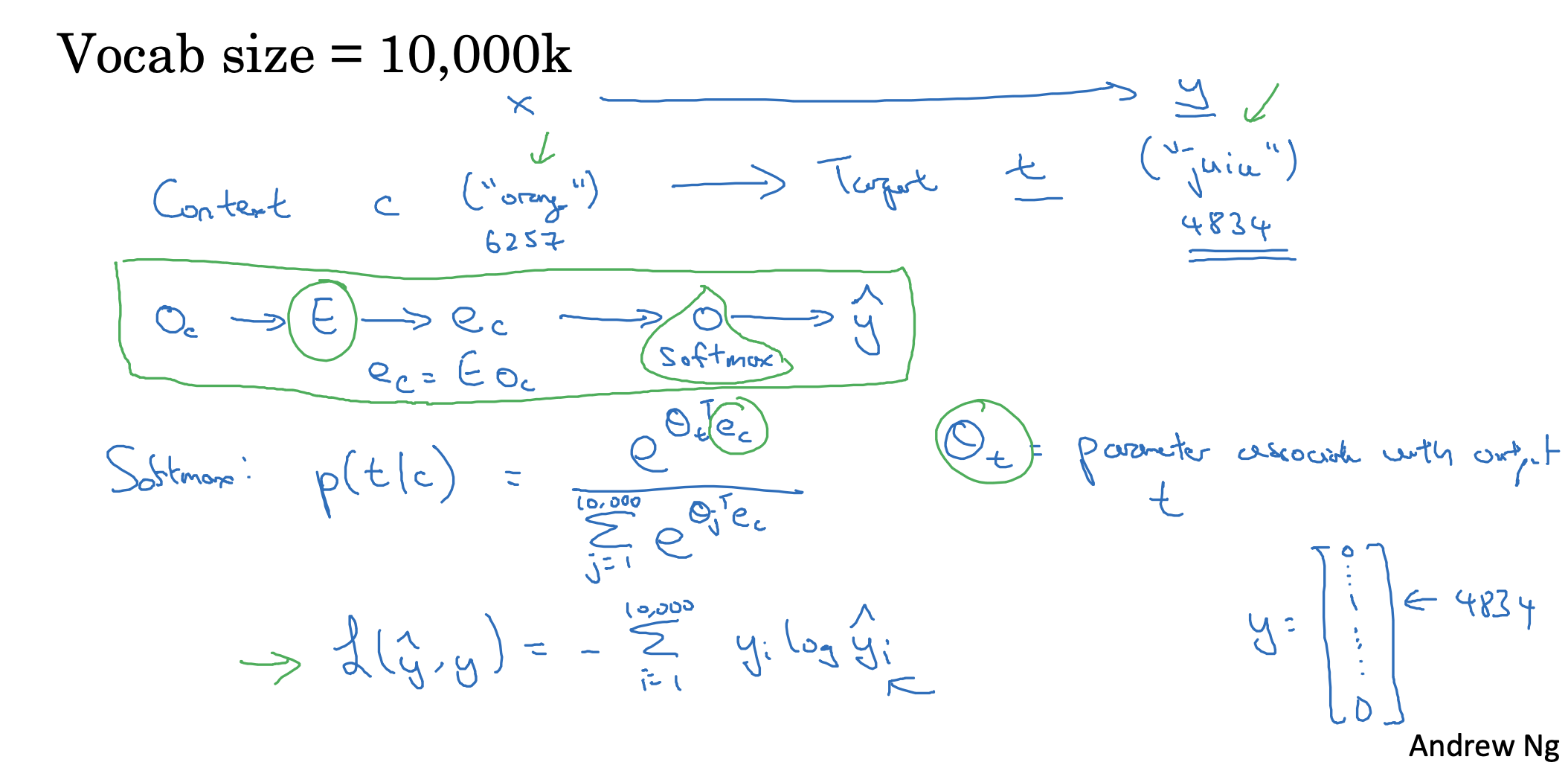
context에 따른 target을 설정하는 방법이 조금 다르다는 점을 제외한 나머지 과정은 동일합니다.
- context의 one-hot vector를 통해 embedding matrix에서 해당 column을 추출합니다.
- 여기에 softmax를 적용해 어떤 단어가 될지(vocab에 포함된 단어 중)를 예측하여 y hat을 구합니다.
- 이때 context에 따른 target의 등장 확률을 softmax로 정의된 식을 볼 수 있습니다.
- theta는 target에 대한 확률값을 의미합니다.
- loss는 당연히 예측값과 타겟값을 비교하여 구하게 되고, 이때의 타겟은 vocab 사이즈의 one-hot vector입니다.
Problems with softmax classification

하지만 vocab 사이즈에 따른 softmax로의 확률 예측은 굉장히 시간이 많이 소요되는 비효율적인 연산 방법입니다.
그래서 이를 해결하기 위해 tree 구조로 접근하는 hierarchical softmax도 등장했습니다.
vocab의 단어 중 어디에 속하는지 이진 분류를 반복하여 탐색하는 것이죠(시간 복잡도는 logV로 줄어듭니다)
결국 context에 따른 target의 확률 예측은 알겠는데, 그래서 context는 어떻게 고를까요?
물론 uniformly하게 고를 수도 있겠지만, 그보다는 자주 등장할 확률이 높은 단어들을 우선적으로 sampling하게됩니다.
- 예를 들어서 the, of, a 등의 단어들은 문장 내에서 자주 등장하는 단어들이지만(빈도가 높지만) orange, apple 등의 단어는 특수한 상황에서만 쓰이는 단어들이라고 볼 수 있죠.
Word2Vec 모델에는 이와 같은 skip-gram 뿐만 아니라, 양쪽의 context가 주어졌을 때 중간(middle) 단어를 예측하는 CBow 모델도 존재합니다.
출처: Coursera, Sequence Models, DeepLearning.AI
'Sequence Models > 2주차' 카테고리의 다른 글
| Learning Word Embeddings(4) : GloVe word vectors (0) | 2023.04.24 |
|---|---|
| Learning Word Embeddings(3) : Negative Sampling (0) | 2023.04.24 |
| Learning Word Embeddings(1) : Learning Word Embeddings (0) | 2023.04.22 |
| Introduction to Word Embeddings(3),(4) : Properties of Word Embeddings, Embedding Matrix (0) | 2023.04.21 |
| Introduction to Word Embeddings(2) : Using Word Embeddings (0) | 2023.04.21 |