
GloVe (global vectors for word representatoin)
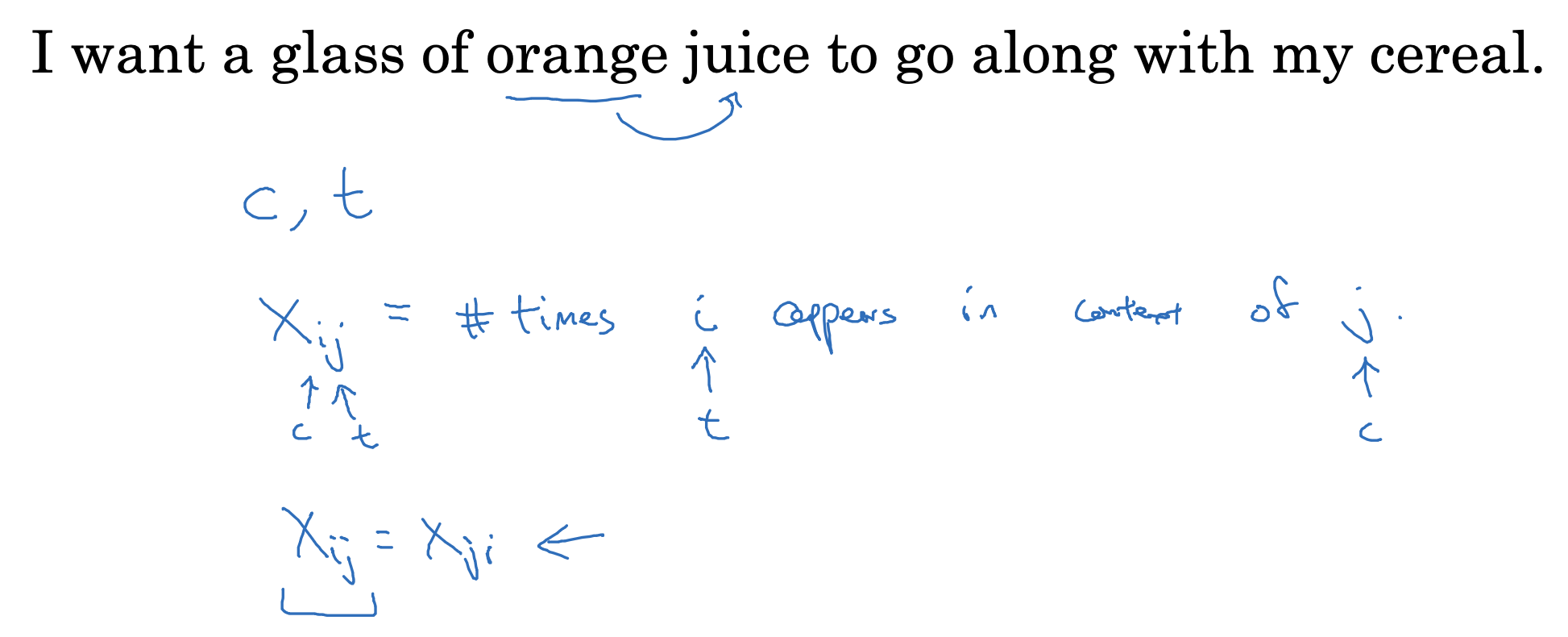
굉장히 직관적이고 간단한 방식으로 유명한 GloVe 모델입니다.
- context i, target j의 관계에서, context가 주어졌을 때 target이 몇 번 등장했는지를 Xij 변수에 담습니다.
- 설정한 조건들에 따라서 Xij, Xji의 값이 같을 수 있습니다.
Model
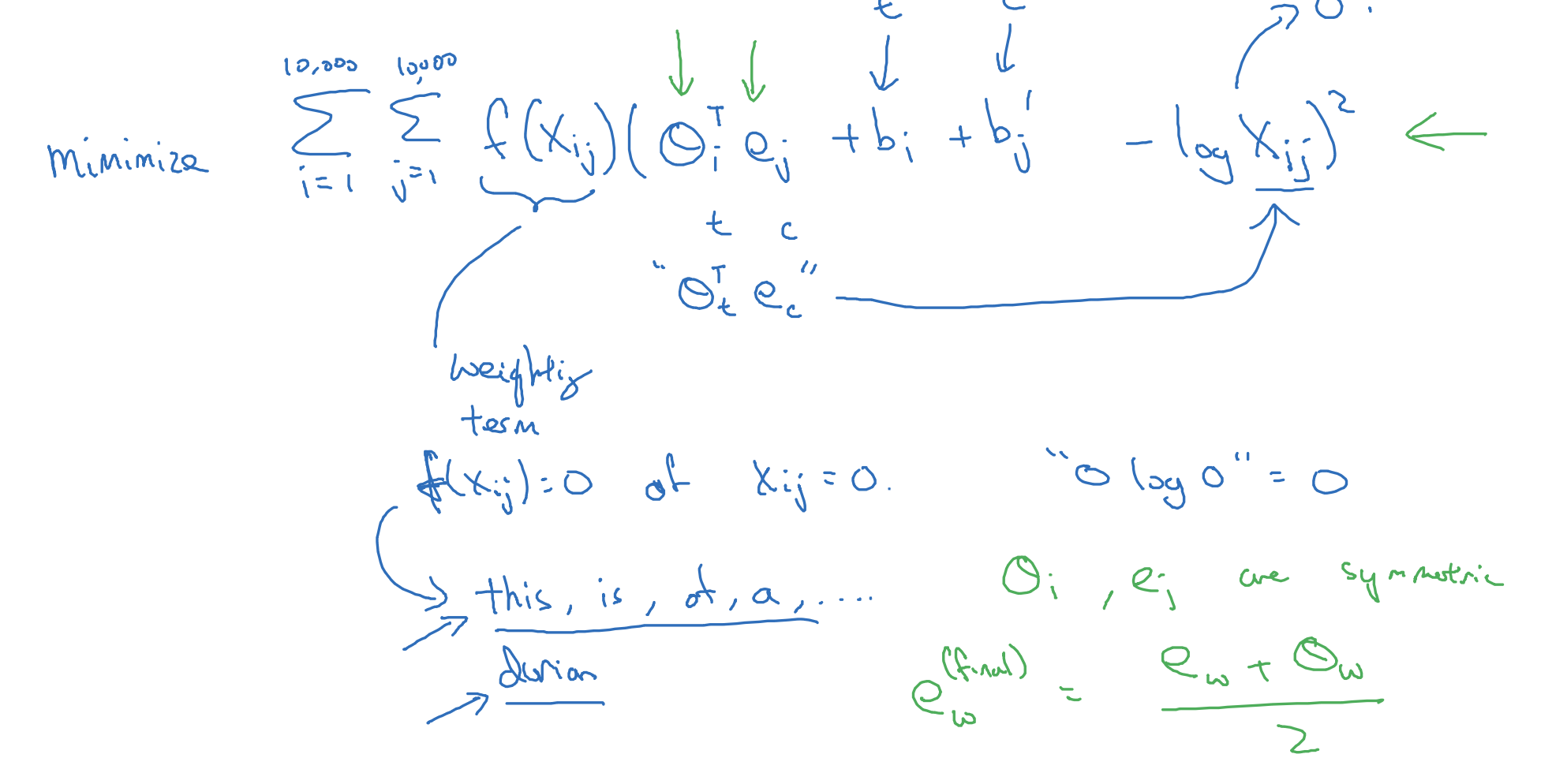
모델의 학습 방향은 당연히 손실 함수를 최소화하는 것입니다.
i, j가 각각 target, context를 의미한다는 점을 고려해 본다면, 예측한 확률에서 각 target의 등장 횟수를 log를 취해 빼는 방식입니다.
가중치 인자에 해당하는 f는 this, is, of, a와 같이 자주 등장하지만 그 의미는 약한 stopwords에게는 적은 가중치를,
반대로 durian과 같이 자주 등장하지는 않지만 그 의미는 뚜렷한 단어에는 높은 가중치를 부여해줍니다.
이전 슬라이드에서 언급했던 것처럼 상황에 따라 i, j가 전치되어도 값이 동일할 수 있다고 했습니다.
이를 다르게 말하면 context, target의 역할이 위 식에서 동일하다는 것이죠.
따라서 둘을 symmetric하다고 표현할 수 있고 이에 따른 b항이 추가된 것을 알 수 있습니다.
이 둘을 초기화하는 가장 좋은 방법은 uniformly random initialization입니다.
A note on the feaurization veiw of word embeddings

지금까지의 결과를 토대로 word embedding을 시각화하면 위처럼 표현될 수 있습니다.
비슷한 벡터끼리는 방향이 비슷하고, 그렇지 않으면 방향도 다른 것이죠.
출처: Coursera, Sequence Models, DeepLearning.AI
'Sequence Models > 2주차' 카테고리의 다른 글
| Applications Using Word Embeddings(2) : Debiasing Word Embeddings (0) | 2023.04.25 |
|---|---|
| Applications Using Word Embeddings(1) : Sentiment Classification (0) | 2023.04.25 |
| Learning Word Embeddings(3) : Negative Sampling (0) | 2023.04.24 |
| Learning Word Embeddings(2) : Word2Vec (0) | 2023.04.24 |
| Learning Word Embeddings(1) : Learning Word Embeddings (0) | 2023.04.22 |
GloVe (global vectors for word representatoin)
굉장히 직관적이고 간단한 방식으로 유명한 GloVe 모델입니다.
- context i, target j의 관계에서, context가 주어졌을 때 target이 몇 번 등장했는지를 Xij 변수에 담습니다.
- 설정한 조건들에 따라서 Xij, Xji의 값이 같을 수 있습니다.
Model
모델의 학습 방향은 당연히 손실 함수를 최소화하는 것입니다.
i, j가 각각 target, context를 의미한다는 점을 고려해 본다면, 예측한 확률에서 각 target의 등장 횟수를 log를 취해 빼는 방식입니다.
가중치 인자에 해당하는 f는 this, is, of, a와 같이 자주 등장하지만 그 의미는 약한 stopwords에게는 적은 가중치를,
반대로 durian과 같이 자주 등장하지는 않지만 그 의미는 뚜렷한 단어에는 높은 가중치를 부여해줍니다.
이전 슬라이드에서 언급했던 것처럼 상황에 따라 i, j가 전치되어도 값이 동일할 수 있다고 했습니다.
이를 다르게 말하면 context, target의 역할이 위 식에서 동일하다는 것이죠.
따라서 둘을 symmetric하다고 표현할 수 있고 이에 따른 b항이 추가된 것을 알 수 있습니다.
이 둘을 초기화하는 가장 좋은 방법은 uniformly random initialization입니다.
A note on the feaurization veiw of word embeddings
지금까지의 결과를 토대로 word embedding을 시각화하면 위처럼 표현될 수 있습니다.
비슷한 벡터끼리는 방향이 비슷하고, 그렇지 않으면 방향도 다른 것이죠.
출처: Coursera, Sequence Models, DeepLearning.AI
'Sequence Models > 2주차' 카테고리의 다른 글
| Applications Using Word Embeddings(2) : Debiasing Word Embeddings (0) | 2023.04.25 |
|---|---|
| Applications Using Word Embeddings(1) : Sentiment Classification (0) | 2023.04.25 |
| Learning Word Embeddings(3) : Negative Sampling (0) | 2023.04.24 |
| Learning Word Embeddings(2) : Word2Vec (0) | 2023.04.24 |
| Learning Word Embeddings(1) : Learning Word Embeddings (0) | 2023.04.22 |