
Defining a new learning problem
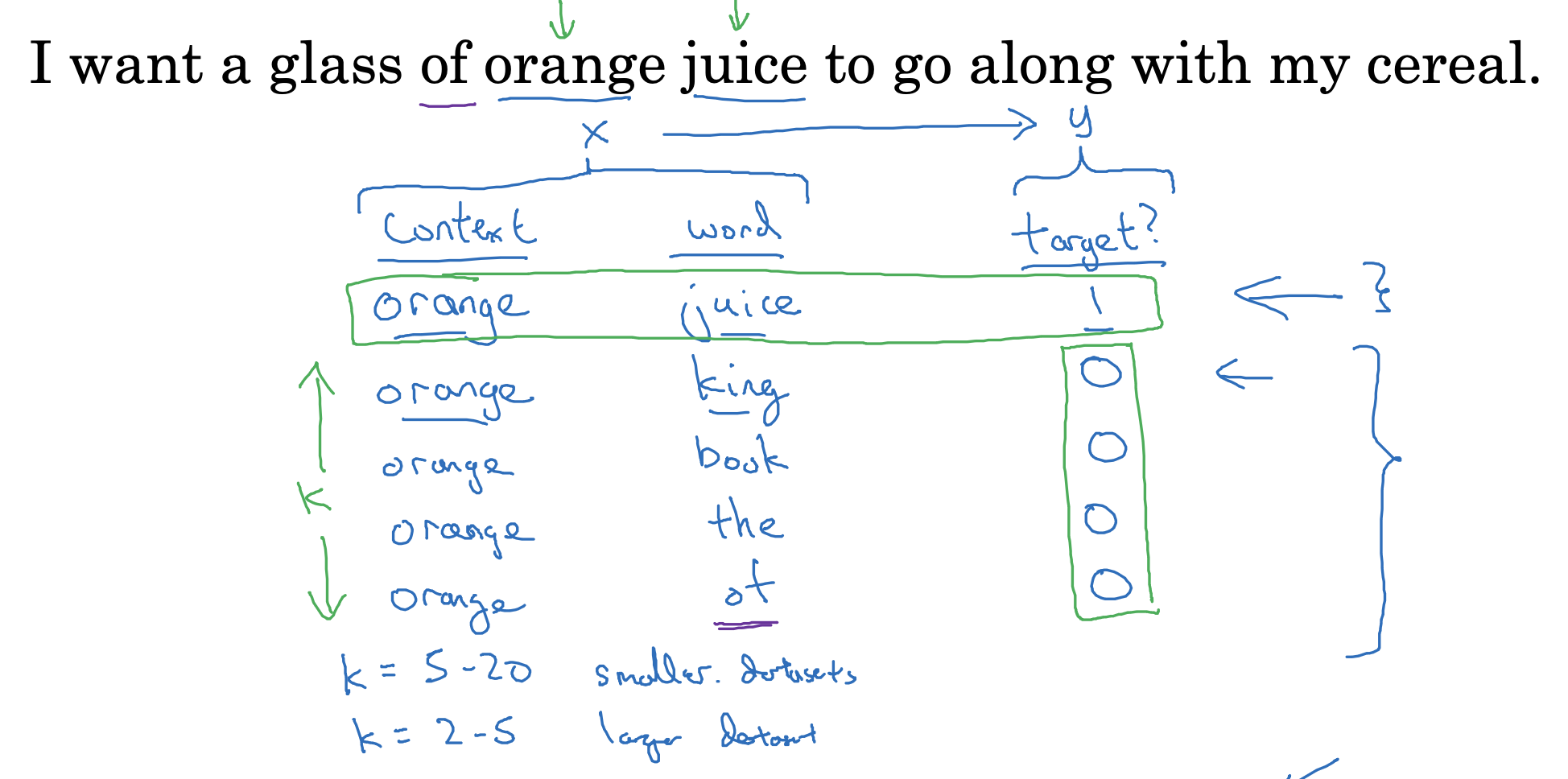
skip-gram 모델은 위처럼 context 하나에 대해 target을 random sampling 하는 방식입니다.
위 예시에서는 k 변수를 4로 설정하여 실제 target을 제외한 후보를 네 개 추출한 것을 볼 수 있습니다.
- 만약 데이터셋이 작은 경우라면 이 k의 값을 키워 여러 개의 단어를 추출해보는 것이 좋습니다.
- 반대로 데이터셋이 크다면 k의 값을 줄이는 것이 효율적입니다.
결국 context - word 쌍을 input X로 주고, target y를 output으로 두어서 모델이 학습하게 됩니다.
Model
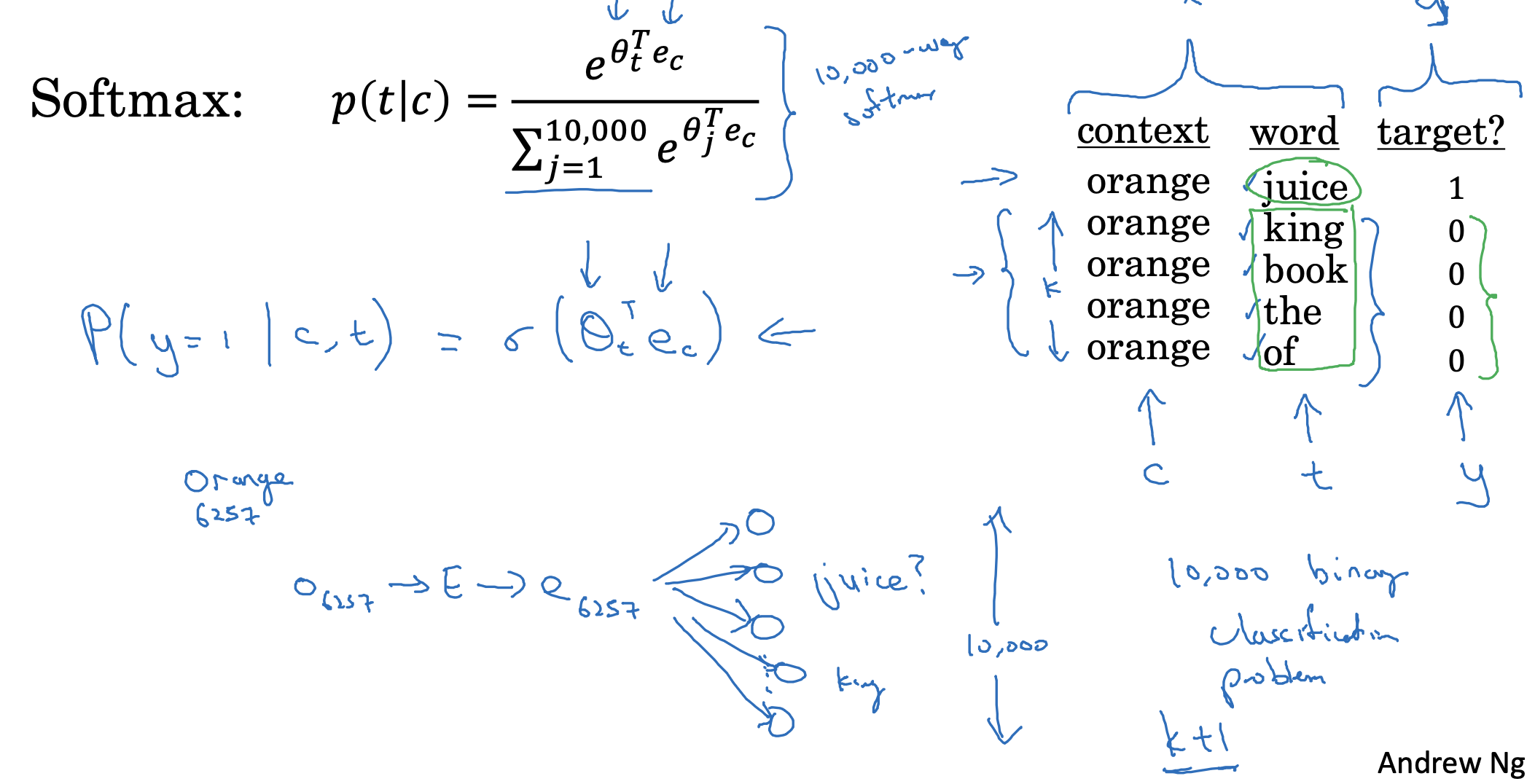
위 소프트맥스 함수는, context와 target 쌍이 주어졌을 때, 예측 결과가 실제 target이었을 확률을 구하는 것입니다.
한편 vocab에 포함된 단어가 10,000개라고 가정하는 경우, 우리가 예측한 것이 target인지 아닌지로 이진 분류할 수도 있습니다.
하지만 이는 굉장히 비효율적이긴 접근 방식입니다.
따라서 이전에 설정한 k에 1을 더한 (k+1)개 만큼의 word를 추출하고 이를 context와 쌍을 이루어 이진 분류하는 것으로 이해할 수 있습니다.
Selecting negative examples
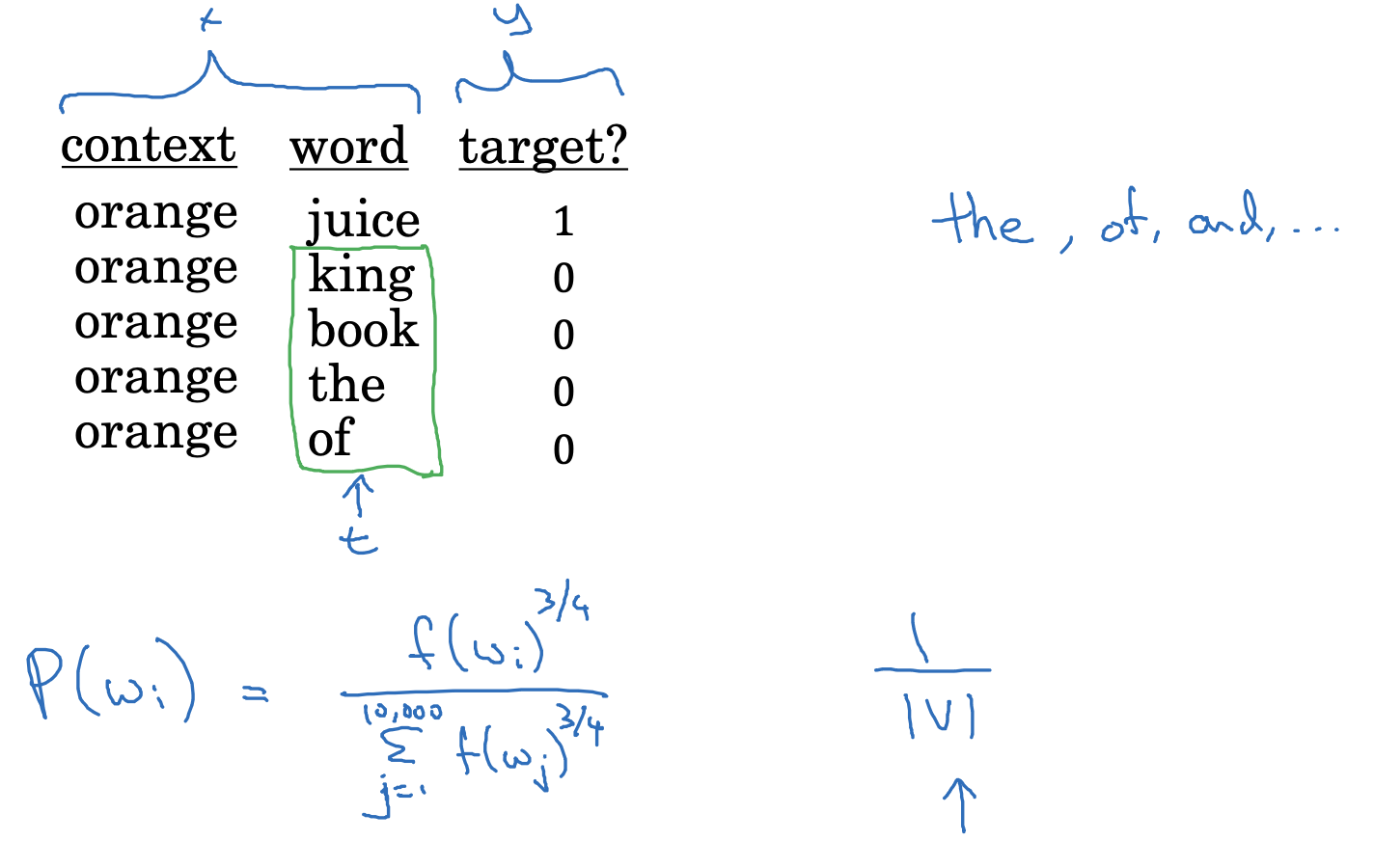
하지만 이전 강의에서 다뤘던 내용처럼, 그래서 'word'는 어떻게 뽑을 건데?, 에 대한 문제가 남아있습니다.
이는 완전히 동일한(uniform) 확률을 기반으로 뽑을 수도 있고, 빈도(frequency)를 기반으로 뽑을 수도 있습니다.
어찌 되었든지 간에 두 케이스 모두 극단적이라서 중도적인 입장을 취하는 것이 좋습니다.
그렇기 때문에 p(wi)가 빈도를 구한 함수의 3/4승을 항으로 쓰고 있는 것입니다.
출처: Coursera, Sequence Models, DeepLearning.AI
'Sequence Models > 2주차' 카테고리의 다른 글
| Applications Using Word Embeddings(1) : Sentiment Classification (0) | 2023.04.25 |
|---|---|
| Learning Word Embeddings(4) : GloVe word vectors (0) | 2023.04.24 |
| Learning Word Embeddings(2) : Word2Vec (0) | 2023.04.24 |
| Learning Word Embeddings(1) : Learning Word Embeddings (0) | 2023.04.22 |
| Introduction to Word Embeddings(3),(4) : Properties of Word Embeddings, Embedding Matrix (0) | 2023.04.21 |
Defining a new learning problem
skip-gram 모델은 위처럼 context 하나에 대해 target을 random sampling 하는 방식입니다.
위 예시에서는 k 변수를 4로 설정하여 실제 target을 제외한 후보를 네 개 추출한 것을 볼 수 있습니다.
- 만약 데이터셋이 작은 경우라면 이 k의 값을 키워 여러 개의 단어를 추출해보는 것이 좋습니다.
- 반대로 데이터셋이 크다면 k의 값을 줄이는 것이 효율적입니다.
결국 context - word 쌍을 input X로 주고, target y를 output으로 두어서 모델이 학습하게 됩니다.
Model
위 소프트맥스 함수는, context와 target 쌍이 주어졌을 때, 예측 결과가 실제 target이었을 확률을 구하는 것입니다.
한편 vocab에 포함된 단어가 10,000개라고 가정하는 경우, 우리가 예측한 것이 target인지 아닌지로 이진 분류할 수도 있습니다.
하지만 이는 굉장히 비효율적이긴 접근 방식입니다.
따라서 이전에 설정한 k에 1을 더한 (k+1)개 만큼의 word를 추출하고 이를 context와 쌍을 이루어 이진 분류하는 것으로 이해할 수 있습니다.
Selecting negative examples
하지만 이전 강의에서 다뤘던 내용처럼, 그래서 'word'는 어떻게 뽑을 건데?, 에 대한 문제가 남아있습니다.
이는 완전히 동일한(uniform) 확률을 기반으로 뽑을 수도 있고, 빈도(frequency)를 기반으로 뽑을 수도 있습니다.
어찌 되었든지 간에 두 케이스 모두 극단적이라서 중도적인 입장을 취하는 것이 좋습니다.
그렇기 때문에 p(wi)가 빈도를 구한 함수의 3/4승을 항으로 쓰고 있는 것입니다.
출처: Coursera, Sequence Models, DeepLearning.AI
'Sequence Models > 2주차' 카테고리의 다른 글
| Applications Using Word Embeddings(1) : Sentiment Classification (0) | 2023.04.25 |
|---|---|
| Learning Word Embeddings(4) : GloVe word vectors (0) | 2023.04.24 |
| Learning Word Embeddings(2) : Word2Vec (0) | 2023.04.24 |
| Learning Word Embeddings(1) : Learning Word Embeddings (0) | 2023.04.22 |
| Introduction to Word Embeddings(3),(4) : Properties of Word Embeddings, Embedding Matrix (0) | 2023.04.21 |