
Analogies
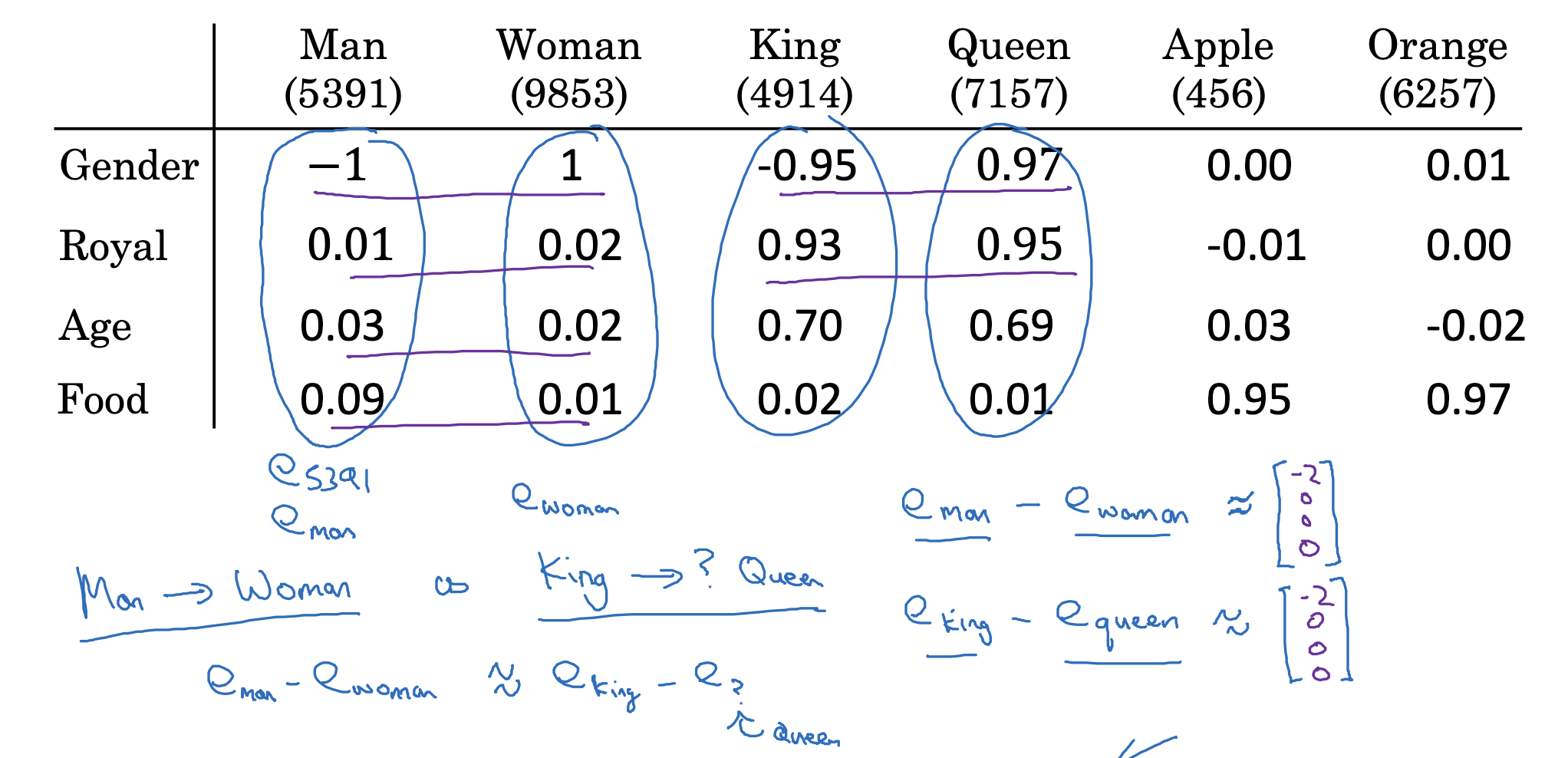
벡터는 특정 차원 내의 한 점을 가리키는 화살표로 이해할 수 있습니다.
따라서 두 벡터 간의 차를 통해 다른 벡터 간의 특징을 유추할 수 있습니다.
- 예를 들어 man-woman의 차이를 생각해보면 성별이 반대라는 특징을 얻을 수 있죠.
- 이런 차이는 king-queen에서도 똑같이 드러날 것입니다.
Analogies using word vetors
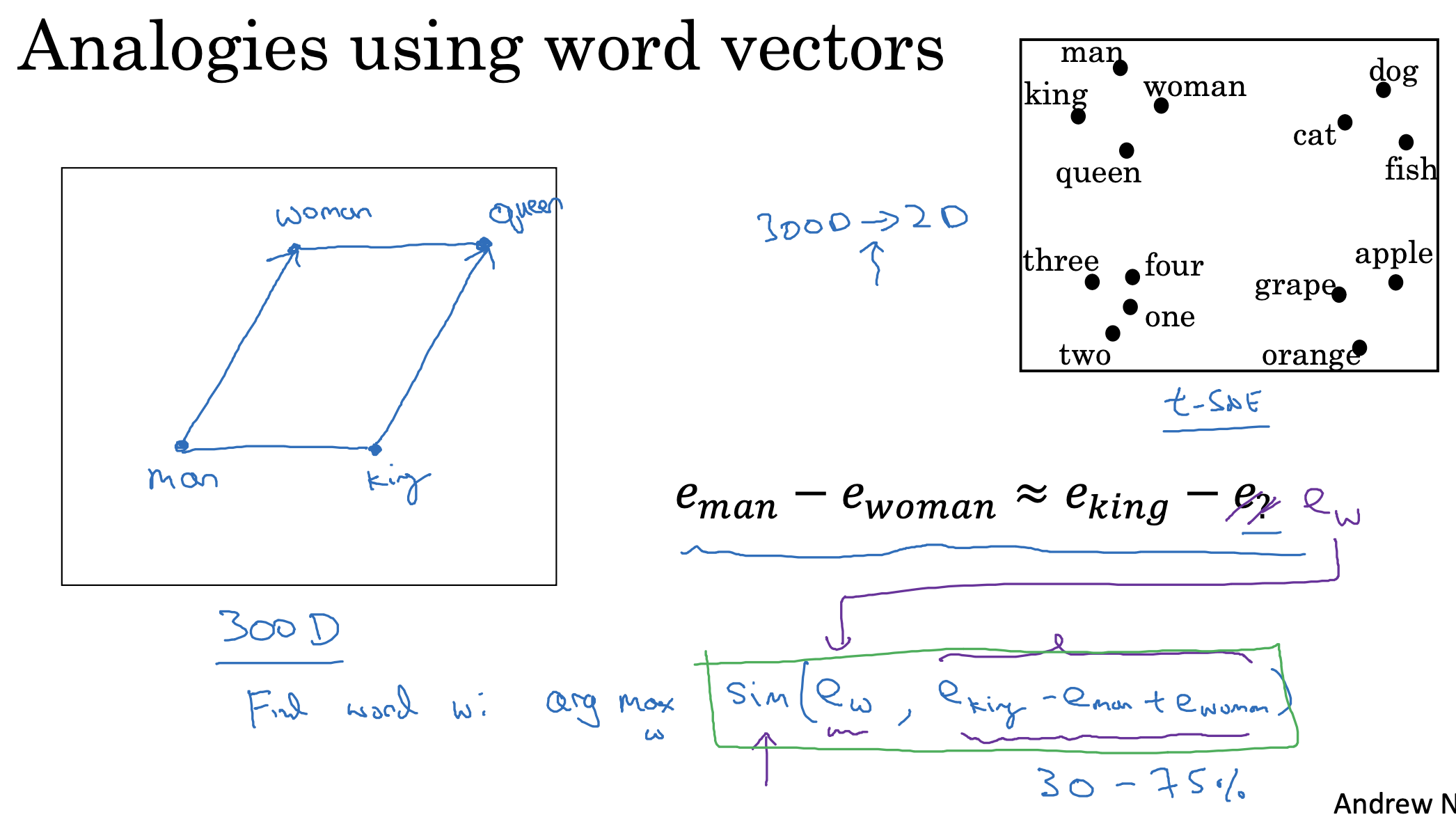
그래서 만약 man-woman과 유사한 관계에 있는 king의 짝꿍을 찾는다고 한다면 위와 같은 sim(유사도) 공식을 이용할 수 있습니다.
유사도가 가장 높은(arg max) 원소를 찾는 방식을 이용하는 것이죠.
이는 2차원 공간으로 시각화했을 때를 생각해보면, 두 벡터 간의 차이를 나타내는 화살표(벡터)가 가장 유사한 것이 무엇인지 찾는 과정인 것입니다.
Cosine similarity

대표적인 유사도 공식으로는 cosine similarity(코사인 유사도)가 있습니다.
- 두 벡터를 내적하고 이를 각각의 길이로 나누는 식입니다.
- 두 벡터가 유사하다면, 즉 거의 비슷한 화살표라면 둘 사이의 각도 간격이 작을 것이므로 cos 값이 작을 것(0에 수렴)입니다.
- 반대로 두 벡터가 정 반대라면 둘 사이의 각도는 180도가 되어 cos 값은 -1이 됩니다.
- 즉 cosine similarity는 -1에서 1 사이의 값을 가지고, 1에 가까울수록 두 벡터가 유사하다는 것을 의미합니다.
두 벡터 간의 차이, 즉 dissimilarity를 구하는 공식으로는 차의 제곱이 있습니다.
Embedding matrix
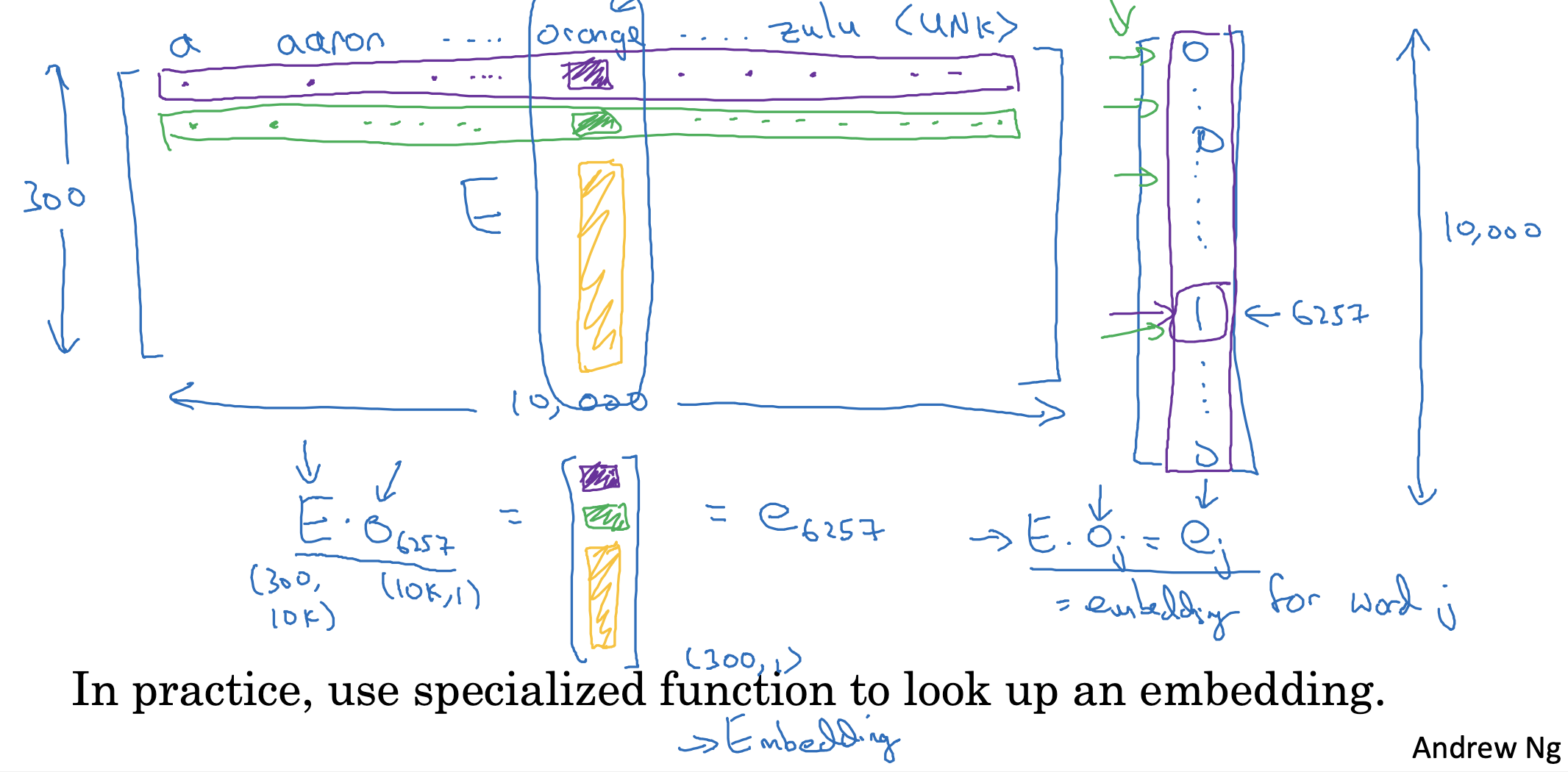
만약 10,000개의 단어를 vocab으로 가지고 있고, 300개의 특징으로 표현된 Embedding Matrix가 있다고 가정하고, 이를 E로 표기하면 위와 같습니다.
이때 이 행렬을 기존의 one-hot vector와 행렬곱하면 어떻게 될까요?
- 그림에서 색상으로 잘 표시된 바와 같이, Embedding Matrix에서 orange에 해당하는 column의 값만 가지고 오게 됩니다.
왜냐하면 one-hot vector는 orange번 째의 값만 1이고 나머지는 0이기 때문이죠. - 따라서 Embedding Matrix에서 해당 단어(orange)에 해당하는 columns만 똑 떼어온 것 같은 결과가 됩니다.
출처: Coursera, Sequence Models, DeepLearning.AI
'Sequence Models > 2주차' 카테고리의 다른 글
| Learning Word Embeddings(3) : Negative Sampling (0) | 2023.04.24 |
|---|---|
| Learning Word Embeddings(2) : Word2Vec (0) | 2023.04.24 |
| Learning Word Embeddings(1) : Learning Word Embeddings (0) | 2023.04.22 |
| Introduction to Word Embeddings(2) : Using Word Embeddings (0) | 2023.04.21 |
| Introduction to Word Embeddings(1) : Word Representation (0) | 2023.04.21 |
Analogies
벡터는 특정 차원 내의 한 점을 가리키는 화살표로 이해할 수 있습니다.
따라서 두 벡터 간의 차를 통해 다른 벡터 간의 특징을 유추할 수 있습니다.
- 예를 들어 man-woman의 차이를 생각해보면 성별이 반대라는 특징을 얻을 수 있죠.
- 이런 차이는 king-queen에서도 똑같이 드러날 것입니다.
Analogies using word vetors
그래서 만약 man-woman과 유사한 관계에 있는 king의 짝꿍을 찾는다고 한다면 위와 같은 sim(유사도) 공식을 이용할 수 있습니다.
유사도가 가장 높은(arg max) 원소를 찾는 방식을 이용하는 것이죠.
이는 2차원 공간으로 시각화했을 때를 생각해보면, 두 벡터 간의 차이를 나타내는 화살표(벡터)가 가장 유사한 것이 무엇인지 찾는 과정인 것입니다.
Cosine similarity
대표적인 유사도 공식으로는 cosine similarity(코사인 유사도)가 있습니다.
- 두 벡터를 내적하고 이를 각각의 길이로 나누는 식입니다.
- 두 벡터가 유사하다면, 즉 거의 비슷한 화살표라면 둘 사이의 각도 간격이 작을 것이므로 cos 값이 작을 것(0에 수렴)입니다.
- 반대로 두 벡터가 정 반대라면 둘 사이의 각도는 180도가 되어 cos 값은 -1이 됩니다.
- 즉 cosine similarity는 -1에서 1 사이의 값을 가지고, 1에 가까울수록 두 벡터가 유사하다는 것을 의미합니다.
두 벡터 간의 차이, 즉 dissimilarity를 구하는 공식으로는 차의 제곱이 있습니다.
Embedding matrix
만약 10,000개의 단어를 vocab으로 가지고 있고, 300개의 특징으로 표현된 Embedding Matrix가 있다고 가정하고, 이를 E로 표기하면 위와 같습니다.
이때 이 행렬을 기존의 one-hot vector와 행렬곱하면 어떻게 될까요?
- 그림에서 색상으로 잘 표시된 바와 같이, Embedding Matrix에서 orange에 해당하는 column의 값만 가지고 오게 됩니다.
왜냐하면 one-hot vector는 orange번 째의 값만 1이고 나머지는 0이기 때문이죠. - 따라서 Embedding Matrix에서 해당 단어(orange)에 해당하는 columns만 똑 떼어온 것 같은 결과가 됩니다.
출처: Coursera, Sequence Models, DeepLearning.AI
'Sequence Models > 2주차' 카테고리의 다른 글
| Learning Word Embeddings(3) : Negative Sampling (0) | 2023.04.24 |
|---|---|
| Learning Word Embeddings(2) : Word2Vec (0) | 2023.04.24 |
| Learning Word Embeddings(1) : Learning Word Embeddings (0) | 2023.04.22 |
| Introduction to Word Embeddings(2) : Using Word Embeddings (0) | 2023.04.21 |
| Introduction to Word Embeddings(1) : Word Representation (0) | 2023.04.21 |