
Neural language model
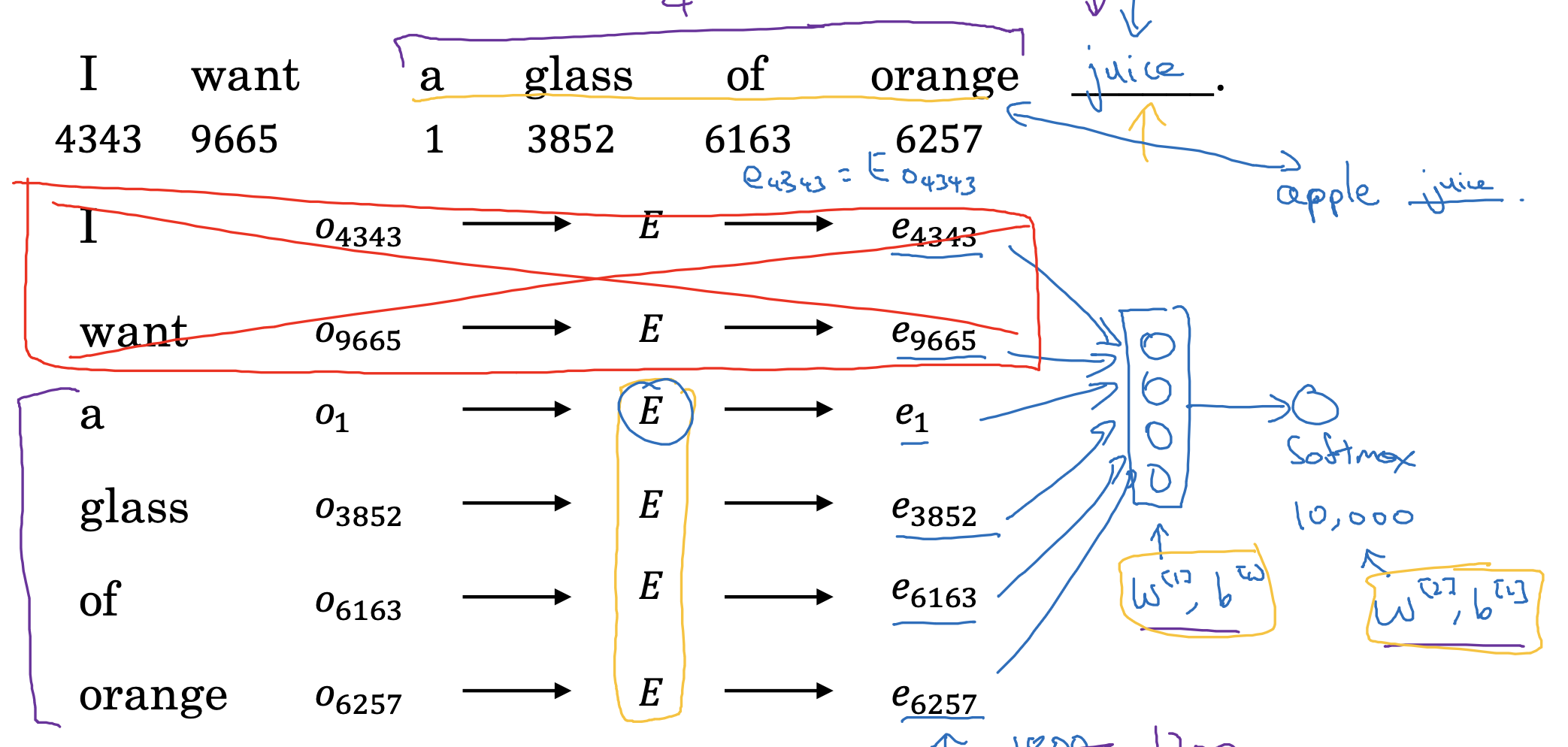
지난 시간까지 배웠던 word embedding이 어떤 식으로 모델 학습에 이용되는지를 나타내고 있습니다.
1. 각 단어(토큰)를 대상으로 vocab에서 숫자를 꺼내어 one-hot vector를 생성합니다.
2. 이를 이용하여 embedding matrix에서 매칭되는 column을 추출합니다.
3. 추출된 column을 중첩하여 input으로 이용합니다.
4. 모델 학습은 이렇게 만든 input에 대한 weight & bias, 그리고 softmax를 통해 추출한 확률을 구할 때의 weight & bias로 진행됩니다.
Other context/target pairs

target, 즉 예측하고자 하는 단어의 주변 문맥을 어디까지 설정하는가도 중요한 문제입니다.
위 예시에서는 이전의 네 개 단어를 문맥으로 정의했기 때문에, 각 vector가 지니는 300개씩의 feature가 4배로 쌓인 1,200차원이 되었던 것입니다.
- 물론 꼭 네 개일 필요는 없고, 상황에 따라 target 단어의 앞뒤로 네 개 단어를 문맥으로 정의할 수도 있습니다.
- 때로는 이전의 딱 한 개 단어를 문맥으로 정의하기도 합니다.
- 이런 특수한 경우는 사실 skip gram에 대한 내용인데 이후 강의에서 다룬다고 합니다.
출처: Coursera, Sequence Models, DeepLearning.AI
'Sequence Models > 2주차' 카테고리의 다른 글
| Learning Word Embeddings(3) : Negative Sampling (0) | 2023.04.24 |
|---|---|
| Learning Word Embeddings(2) : Word2Vec (0) | 2023.04.24 |
| Introduction to Word Embeddings(3),(4) : Properties of Word Embeddings, Embedding Matrix (0) | 2023.04.21 |
| Introduction to Word Embeddings(2) : Using Word Embeddings (0) | 2023.04.21 |
| Introduction to Word Embeddings(1) : Word Representation (0) | 2023.04.21 |
Neural language model
지난 시간까지 배웠던 word embedding이 어떤 식으로 모델 학습에 이용되는지를 나타내고 있습니다.
1. 각 단어(토큰)를 대상으로 vocab에서 숫자를 꺼내어 one-hot vector를 생성합니다.
2. 이를 이용하여 embedding matrix에서 매칭되는 column을 추출합니다.
3. 추출된 column을 중첩하여 input으로 이용합니다.
4. 모델 학습은 이렇게 만든 input에 대한 weight & bias, 그리고 softmax를 통해 추출한 확률을 구할 때의 weight & bias로 진행됩니다.
Other context/target pairs
target, 즉 예측하고자 하는 단어의 주변 문맥을 어디까지 설정하는가도 중요한 문제입니다.
위 예시에서는 이전의 네 개 단어를 문맥으로 정의했기 때문에, 각 vector가 지니는 300개씩의 feature가 4배로 쌓인 1,200차원이 되었던 것입니다.
- 물론 꼭 네 개일 필요는 없고, 상황에 따라 target 단어의 앞뒤로 네 개 단어를 문맥으로 정의할 수도 있습니다.
- 때로는 이전의 딱 한 개 단어를 문맥으로 정의하기도 합니다.
- 이런 특수한 경우는 사실 skip gram에 대한 내용인데 이후 강의에서 다룬다고 합니다.
출처: Coursera, Sequence Models, DeepLearning.AI
'Sequence Models > 2주차' 카테고리의 다른 글
| Learning Word Embeddings(3) : Negative Sampling (0) | 2023.04.24 |
|---|---|
| Learning Word Embeddings(2) : Word2Vec (0) | 2023.04.24 |
| Introduction to Word Embeddings(3),(4) : Properties of Word Embeddings, Embedding Matrix (0) | 2023.04.21 |
| Introduction to Word Embeddings(2) : Using Word Embeddings (0) | 2023.04.21 |
| Introduction to Word Embeddings(1) : Word Representation (0) | 2023.04.21 |