
Sentiment classification problem

Sequence Model로 처리할 수 있는 대표적 태스크 중 하나인 sentiment classification(감성/감정 분류)입니다.
입력(X)을 문장으로 받고, 각 문장이 어떤 평점에 해당하는지를 정답(Y)으로 삼는 구조입니다.
Simple sentiment classification model
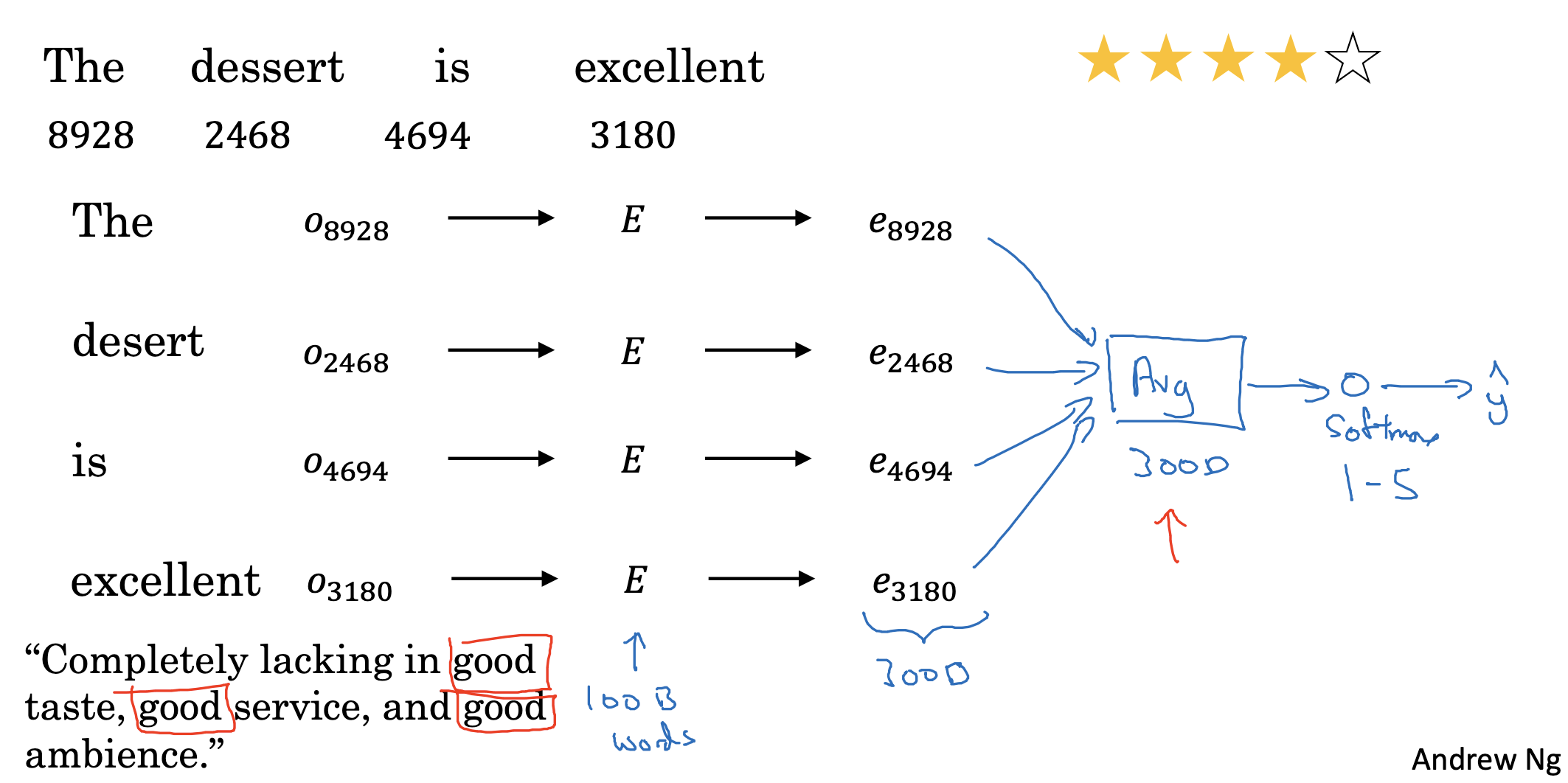
따라서 단어(토큰)마다 임베딩을 추출하여 평균을 구하고, 여기에 softmax를 적용하여 예측값을 구합니다.
- 만약 한 문장 내에 감성에 영향을 줄 수 있는 표현이 여러 번 등장하는 경우(예시에서는 good), 평균값에 이 vector의 값이 제일 많이 반영될 것입니다.
RNN for sentiment classification
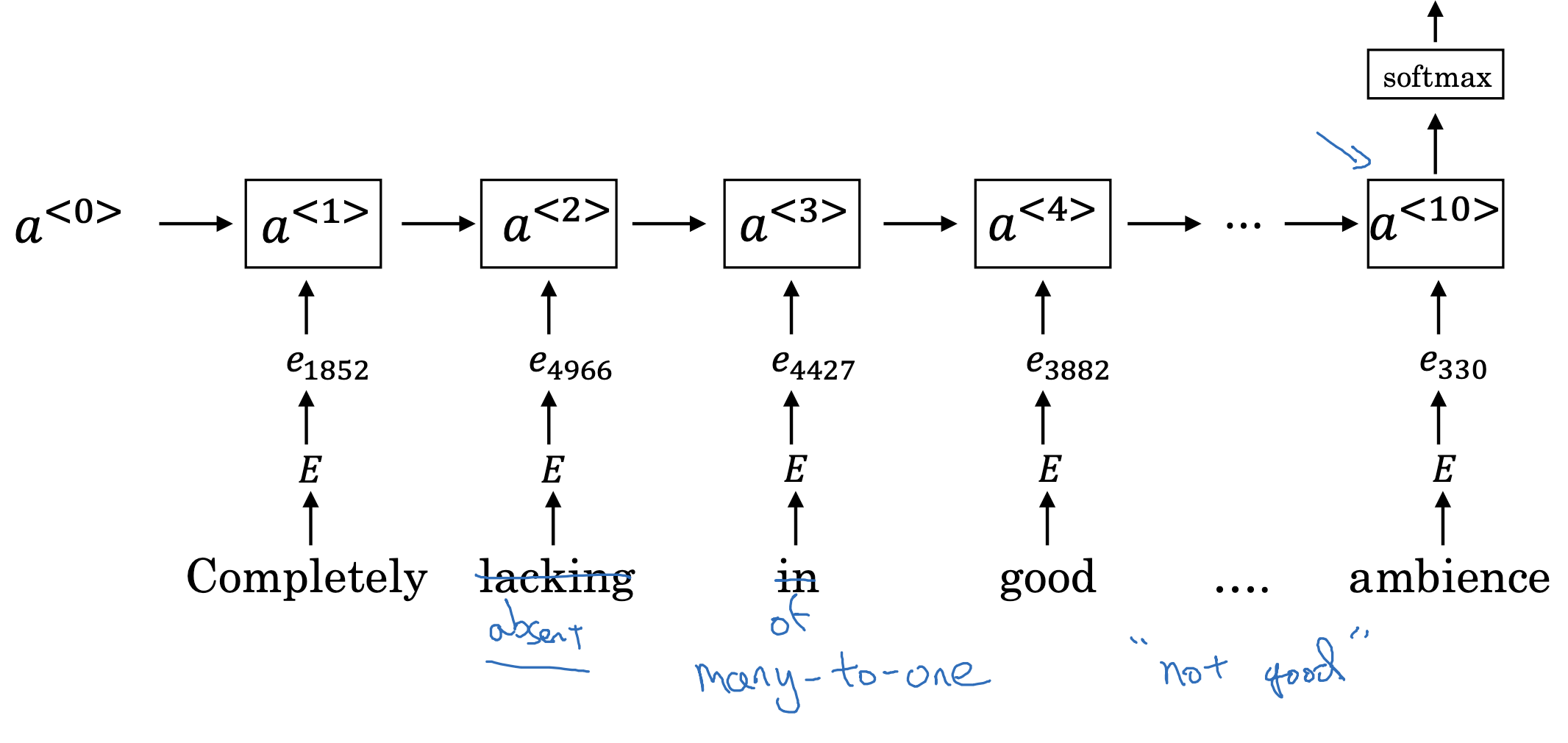
위에서 설명한 것을 RNN 아키텍쳐에 반영하면 이와 같습니다.
결국 마지막 단어(토큰)에 이르러서 softmax를 적용하고, 어떤 평점에 분류될 것인지를 구하게 됩니다.
따라서 Sequence Model로 처리하는 여러 태스크 중에서 many-to-one, 즉 입력은 여러 개지만 출력은 한 개인 형태입니다.
출처: Coursera, Sequence Models, DeepLearning.AI
'Sequence Models > 2주차' 카테고리의 다른 글
| Applications Using Word Embeddings(2) : Debiasing Word Embeddings (0) | 2023.04.25 |
|---|---|
| Learning Word Embeddings(4) : GloVe word vectors (0) | 2023.04.24 |
| Learning Word Embeddings(3) : Negative Sampling (0) | 2023.04.24 |
| Learning Word Embeddings(2) : Word2Vec (0) | 2023.04.24 |
| Learning Word Embeddings(1) : Learning Word Embeddings (0) | 2023.04.22 |
Sentiment classification problem
Sequence Model로 처리할 수 있는 대표적 태스크 중 하나인 sentiment classification(감성/감정 분류)입니다.
입력(X)을 문장으로 받고, 각 문장이 어떤 평점에 해당하는지를 정답(Y)으로 삼는 구조입니다.
Simple sentiment classification model
따라서 단어(토큰)마다 임베딩을 추출하여 평균을 구하고, 여기에 softmax를 적용하여 예측값을 구합니다.
- 만약 한 문장 내에 감성에 영향을 줄 수 있는 표현이 여러 번 등장하는 경우(예시에서는 good), 평균값에 이 vector의 값이 제일 많이 반영될 것입니다.
RNN for sentiment classification
위에서 설명한 것을 RNN 아키텍쳐에 반영하면 이와 같습니다.
결국 마지막 단어(토큰)에 이르러서 softmax를 적용하고, 어떤 평점에 분류될 것인지를 구하게 됩니다.
따라서 Sequence Model로 처리하는 여러 태스크 중에서 many-to-one, 즉 입력은 여러 개지만 출력은 한 개인 형태입니다.
출처: Coursera, Sequence Models, DeepLearning.AI
'Sequence Models > 2주차' 카테고리의 다른 글
| Applications Using Word Embeddings(2) : Debiasing Word Embeddings (0) | 2023.04.25 |
|---|---|
| Learning Word Embeddings(4) : GloVe word vectors (0) | 2023.04.24 |
| Learning Word Embeddings(3) : Negative Sampling (0) | 2023.04.24 |
| Learning Word Embeddings(2) : Word2Vec (0) | 2023.04.24 |
| Learning Word Embeddings(1) : Learning Word Embeddings (0) | 2023.04.22 |