
The problem of bias of word embeddings

인공지능 모델은 텍스트의 정보를 그대로 학습하기 때문에, 텍스트에 녹아 있는 편향적인 내용을 그대로 반영할 수도 있습니다.
- 가장 대표적인 예시는 위와 같이 성과 관련된 것으로, 남-여 : 프로그래머-주부 / 의사-간호사 등으로 구분하게 된 모델이 있었습니다.
사실 실제 사회상을 잘 반영하는 것으로 볼 수도 있지만, 악의적으로 편향된 학습을 하게 된 모델이 미칠 영향은 생각보다 클 수 있습니다.
인공지능에 대한 신뢰도가 높아질수록 의사결정에 더 큰 영향력이 행사될 수 있기 때문이죠.
(참고로 여기서 언급하는 bias는 딥러닝 모델에서 흔히 언급되는 variance-bias와 의미상 차이가 있습니다)
Addressing bias in word embeddings
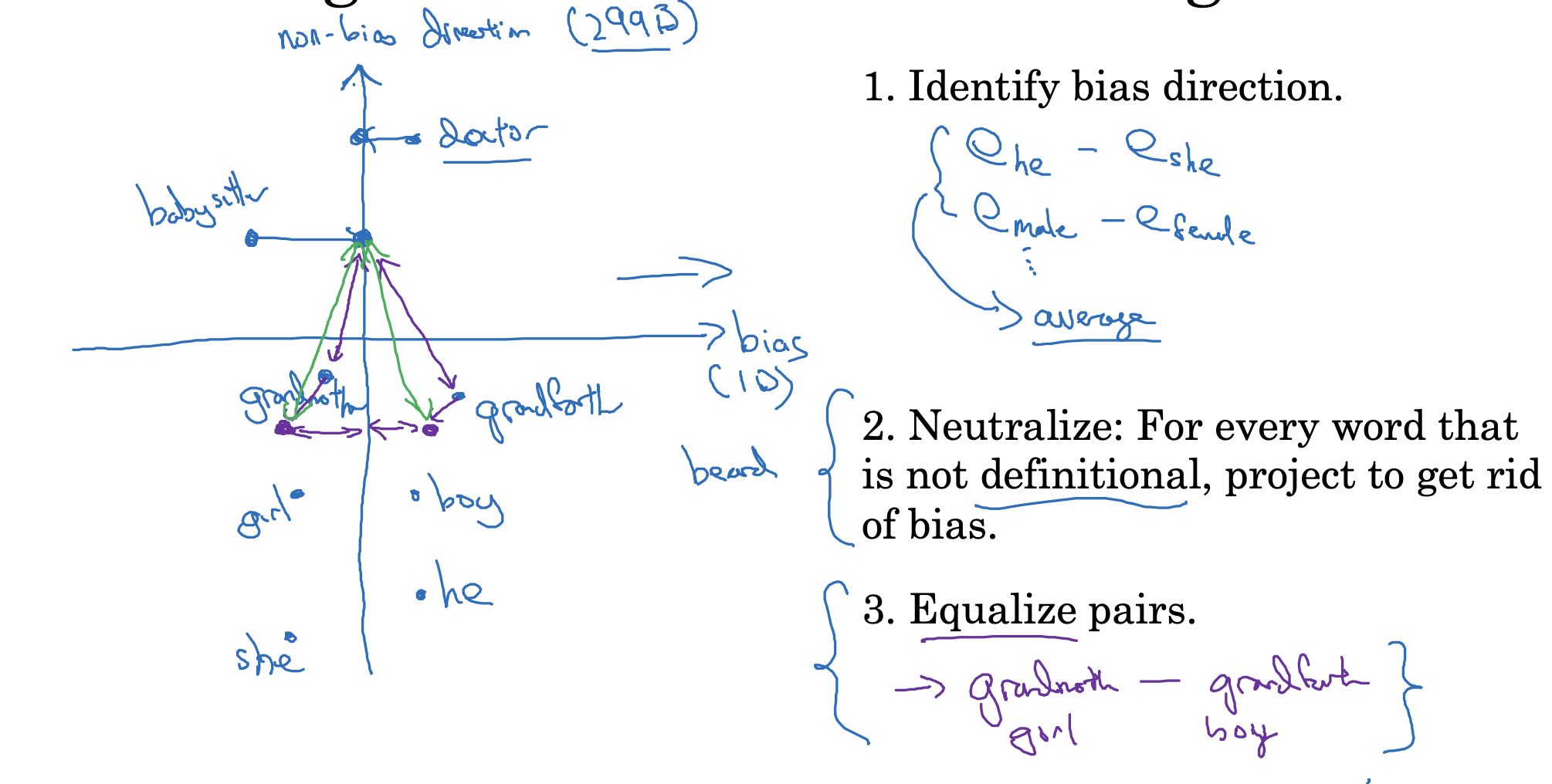
학습된 embedding의 편향을 줄이는 방법은 간단히 요약하면 다음과 같습니다.
- 우선 bias direction(방향)을 파악합니다.
embedding이란 어떤 공간 내 벡터로의 표상(representation)이기 때문에 방향이 존재합니다.
이 방향을 구할 때는 편향을 가질 수 있는 단어 간의 차, 그리고 이것들의 평균으로 구합니다. - bias direction과 상관 없는(정확히는 수직인) non-bias direction을 구합니다.
그리고 단어 중에서 성별과 정의상 무관한 단어들을 이 방향으로 근사시킵니다.
즉 단어에 포함된 편향이 더 적은 공간으로 보내는 것입니다. - 그리고 이를 기준으로 삼아 짝을 이루는 단어쌍의 균형을 맞춰줍니다.
예를 들어 babysitter는 grandfather보다 grandmother와 더 가깝기 때문에 성별 편향의 문제를 안고 있습니다.
따라서 babysitter를 기준으로 두 단어의 임베딩 간 거리가 동일할 수 있게끔 조정해줍니다.
출처: Coursera, Sequence Models, DeepLearning.AI
'Sequence Models > 2주차' 카테고리의 다른 글
| Applications Using Word Embeddings(1) : Sentiment Classification (0) | 2023.04.25 |
|---|---|
| Learning Word Embeddings(4) : GloVe word vectors (0) | 2023.04.24 |
| Learning Word Embeddings(3) : Negative Sampling (0) | 2023.04.24 |
| Learning Word Embeddings(2) : Word2Vec (0) | 2023.04.24 |
| Learning Word Embeddings(1) : Learning Word Embeddings (0) | 2023.04.22 |