
최근에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
프롬프트를 Gist(요점) 토큰에 압축함으로써 모델의 태스크 처리 시간을 단축하고 메모리 효율성을 높일 수 있다.
- 배경
최근 LM(Language Model)을 활용하는 주된 방법 중 하나는 모델에 prompt를 제공하고 모델이 반환하는 answer를 사용하는 것이다.
태스크나 여러 상황에 따라 적절한 프롬프트를 구성하는 전략이 중요해졌고, 심지어 프롬프트 엔지니어라는 이름의 새직종이 생겨날만큼 많은 관심을 받고 있다.
그러나 모델이 입력으로 받을 수 있는 길이에 제한이 존재한다는 점을 감안하면, 길이가 꽤 되는 프롬프트를 반복적으로 사용하는 것은 꽤나 치명적인 문제가 될 수 있다.
본 논문에서는 이를 해결하기 위해 프롬프트를 스페셜 토큰에 압축하는 방법론을 제안한다.
- 관련 연구
prompting, fine-tuning, distillation 등
fine-tuning은 사전학습된 모델을 특정 태스크에 적합하도록 추가 학습하는 방식을 말한다.
distillation은 학습하고자 하는 모델이 사전학습된 모델의 분포를 따르도록 하는 방식을 말한다.
그렇기 때문에 두 방식은 태스크에 따라 모델 전체를 재학습해야한다는 문제점이 있다.
본 논문에서 제안하는 Gisting 방식은 위 두 방식을 절충하며 한계를 극복한 것으로 볼 수 있다.
- 컨셉
입력 x, 태스크 t가 주어졌을 때 정답 y가 나올 수 있도록 하는 방식이 prompting이다.
fine-tuning과 distillation은 여기에서 태스크 t는 제외하고 여러 데이터쌍에 대해 학습하게 된다.
Gisting의 경우 prompting의 태스크 t를 gist token k개로 대체한다.
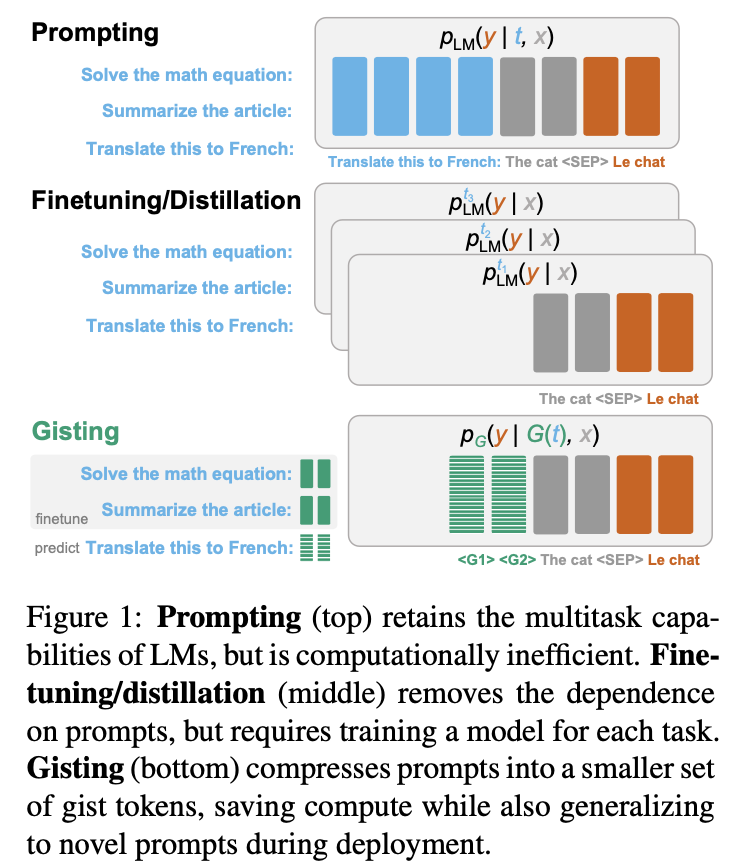
transformer 기반의 모델들은 크게 Autoregressive Decoder, Bidirectional Encoder, Decoder Cross-Attention 방식으로 구분할 수 있다.
각 방식에 맞게끔 Gist Token을 Task(t)와 Input(x) 사이에 배치한다.
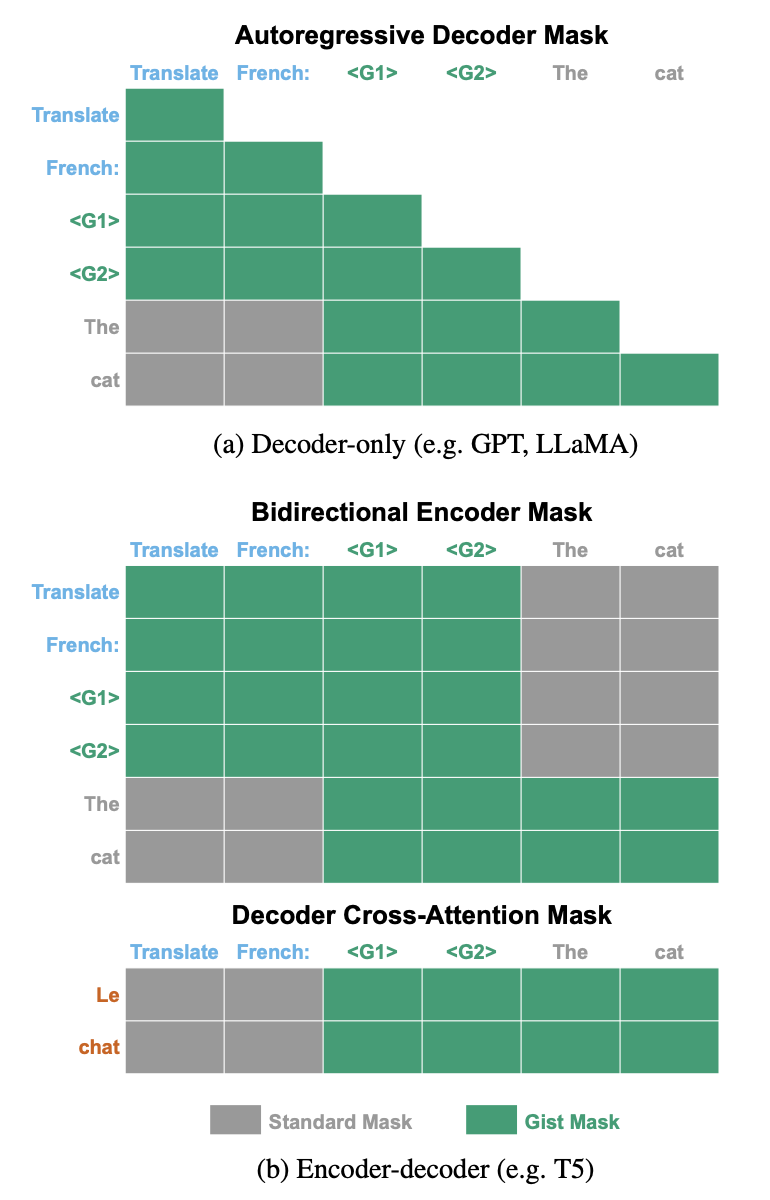
이때 gist token에 문맥 정보가 압축되어 학습될 수 있도록 task와 input 사이에는 attention이 이뤄지지 않도록 차단한다.
(BERT에서 [CLS] 토큰을 문장의 대표 토큰으로 사용하는 것과 유사한 맥락으로 이해할 수 있을 것 같다)
- 개인적 감상
👍🏻
확실히 요즘은 프롬프트에 대한 관심이 뜨거운데 시의 적절하고 유용한 방식을 제안했다는 생각이 든다.
좋은 결과물을 낼 수 있는 좋은 프롬프트 예시들을 보면 실제로 굉장히 그 길이가 긴 것들이 많다.
또한 같은 프롬프트를 이렇게 반복적으로 많이 사용해야 하나, 스스로도 생각해 본 적이 있어서 굉장히 공감이 잘 되는 내용이었다.
특히 task와 input 간의 attention을 제한함으로써 gist token에 문맥 정보가 집중되도록 한 점, 그리고 gist token의 개수에 따른 성능 검증 등을 잘 수행한 점 등이 훌륭하다는 생각이 들었다.
👎🏻
여러 태스크를 처리하기에 자유도가 많이 떨어지지 않을까 하는 걱정이 들었다.
물론 제한된, 혹은 이미 정해진 프롬프트를 사용하는 경우에는 이를 스페셜 토큰으로 압축하는 것이 문제가 없겠지만, 그런 것들이 딱 정해지기 어려운 경우에는 적용하기 어려운 기법이 아닐까 싶었다.
예를 들어 ChatGPT의 경우 사용자들이 어떤 식으로 프롬프트를 제시할지 예측 불가능하다.
그렇다면 이런 해결 방법은 분명 전문가의 입장에서 효율적이고 괜찮은 방법이 될 수 있지만 서비스단의 일반 사용자들에게는 그렇지 못할 가능성이 상당히 높다는 뜻이다.
프롬프트 엔지니어링이나 언어 모델이 큰 주목을 받게 된 데에는 ‘자연어’로 모델에게 명령을 내릴 수 있다는 점이 한 몫을 했는데 오히려 이를 압축해서 알아볼 수 없게 만드는 아이러니한 결과가 아닐까.
출처 : https://arxiv.org/abs/2304.08467?utm_source=substack&utm_medium=email
Learning to Compress Prompts with Gist Tokens
Prompting is now the primary way to utilize the multitask capabilities of language models (LMs), but prompts occupy valuable space in the input context window, and re-encoding the same prompt is computationally inefficient. Finetuning and distillation meth
arxiv.org
'Paper Review' 카테고리의 다른 글
| <LLM> PaLM2 Technical Report (0) | 2023.05.11 |
|---|---|
| <Multi-modal> [LLaVA] Visual Instruction Tuning (0) | 2023.05.10 |
| <Reasoning> [Self-Notes] Learning to Reason and Memorize with Self-Notes (0) | 2023.05.08 |
| <PEFT> LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model (0) | 2023.05.07 |
| <Evaluation> Are Emergent Abilities of Large Language Models a Mirage? (0) | 2023.05.03 |
최근에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
프롬프트를 Gist(요점) 토큰에 압축함으로써 모델의 태스크 처리 시간을 단축하고 메모리 효율성을 높일 수 있다.
- 배경
최근 LM(Language Model)을 활용하는 주된 방법 중 하나는 모델에 prompt를 제공하고 모델이 반환하는 answer를 사용하는 것이다.
태스크나 여러 상황에 따라 적절한 프롬프트를 구성하는 전략이 중요해졌고, 심지어 프롬프트 엔지니어라는 이름의 새직종이 생겨날만큼 많은 관심을 받고 있다.
그러나 모델이 입력으로 받을 수 있는 길이에 제한이 존재한다는 점을 감안하면, 길이가 꽤 되는 프롬프트를 반복적으로 사용하는 것은 꽤나 치명적인 문제가 될 수 있다.
본 논문에서는 이를 해결하기 위해 프롬프트를 스페셜 토큰에 압축하는 방법론을 제안한다.
- 관련 연구
prompting, fine-tuning, distillation 등
fine-tuning은 사전학습된 모델을 특정 태스크에 적합하도록 추가 학습하는 방식을 말한다.
distillation은 학습하고자 하는 모델이 사전학습된 모델의 분포를 따르도록 하는 방식을 말한다.
그렇기 때문에 두 방식은 태스크에 따라 모델 전체를 재학습해야한다는 문제점이 있다.
본 논문에서 제안하는 Gisting 방식은 위 두 방식을 절충하며 한계를 극복한 것으로 볼 수 있다.
- 컨셉
입력 x, 태스크 t가 주어졌을 때 정답 y가 나올 수 있도록 하는 방식이 prompting이다.
fine-tuning과 distillation은 여기에서 태스크 t는 제외하고 여러 데이터쌍에 대해 학습하게 된다.
Gisting의 경우 prompting의 태스크 t를 gist token k개로 대체한다.
transformer 기반의 모델들은 크게 Autoregressive Decoder, Bidirectional Encoder, Decoder Cross-Attention 방식으로 구분할 수 있다.
각 방식에 맞게끔 Gist Token을 Task(t)와 Input(x) 사이에 배치한다.
이때 gist token에 문맥 정보가 압축되어 학습될 수 있도록 task와 input 사이에는 attention이 이뤄지지 않도록 차단한다.
(BERT에서 [CLS] 토큰을 문장의 대표 토큰으로 사용하는 것과 유사한 맥락으로 이해할 수 있을 것 같다)
- 개인적 감상
👍🏻
확실히 요즘은 프롬프트에 대한 관심이 뜨거운데 시의 적절하고 유용한 방식을 제안했다는 생각이 든다.
좋은 결과물을 낼 수 있는 좋은 프롬프트 예시들을 보면 실제로 굉장히 그 길이가 긴 것들이 많다.
또한 같은 프롬프트를 이렇게 반복적으로 많이 사용해야 하나, 스스로도 생각해 본 적이 있어서 굉장히 공감이 잘 되는 내용이었다.
특히 task와 input 간의 attention을 제한함으로써 gist token에 문맥 정보가 집중되도록 한 점, 그리고 gist token의 개수에 따른 성능 검증 등을 잘 수행한 점 등이 훌륭하다는 생각이 들었다.
👎🏻
여러 태스크를 처리하기에 자유도가 많이 떨어지지 않을까 하는 걱정이 들었다.
물론 제한된, 혹은 이미 정해진 프롬프트를 사용하는 경우에는 이를 스페셜 토큰으로 압축하는 것이 문제가 없겠지만, 그런 것들이 딱 정해지기 어려운 경우에는 적용하기 어려운 기법이 아닐까 싶었다.
예를 들어 ChatGPT의 경우 사용자들이 어떤 식으로 프롬프트를 제시할지 예측 불가능하다.
그렇다면 이런 해결 방법은 분명 전문가의 입장에서 효율적이고 괜찮은 방법이 될 수 있지만 서비스단의 일반 사용자들에게는 그렇지 못할 가능성이 상당히 높다는 뜻이다.
프롬프트 엔지니어링이나 언어 모델이 큰 주목을 받게 된 데에는 ‘자연어’로 모델에게 명령을 내릴 수 있다는 점이 한 몫을 했는데 오히려 이를 압축해서 알아볼 수 없게 만드는 아이러니한 결과가 아닐까.
출처 : https://arxiv.org/abs/2304.08467?utm_source=substack&utm_medium=email
Learning to Compress Prompts with Gist Tokens
Prompting is now the primary way to utilize the multitask capabilities of language models (LMs), but prompts occupy valuable space in the input context window, and re-encoding the same prompt is computationally inefficient. Finetuning and distillation meth
arxiv.org
'Paper Review' 카테고리의 다른 글
| <LLM> PaLM2 Technical Report (0) | 2023.05.11 |
|---|---|
| <Multi-modal> [LLaVA] Visual Instruction Tuning (0) | 2023.05.10 |
| <Reasoning> [Self-Notes] Learning to Reason and Memorize with Self-Notes (0) | 2023.05.08 |
| <PEFT> LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model (0) | 2023.05.07 |
| <Evaluation> Are Emergent Abilities of Large Language Models a Mirage? (0) | 2023.05.03 |