
오늘 5/11(목), 한국 기준 새벽 두 시에 Google I/O가 시작되었죠!
저는 자느라고 못 봤지만 일어나보니 재밌는 뉴스들이 조금 있는 것 같았습니다.
폴더블 스마트폰의 출시도 앞으로 시장에 어떤 영향을 줄지 기대가 되는데요,
역시 가장 눈에 띄는 것은 PaLM 2의 등장이겠죠?
이것도 논문..은 아니고 technical report의 형태로 실험 결과 등이 공개되었는데 이를 살펴보고 간략하게 정리해보았습니다.
어차피 아키텍쳐나 구체적인 학습 방법 등에 대한 설명은 포함되지 않았기에 최대한 간단히 특징들만 추려보았어요.
좀 더 자세한 내용이 궁금하시거나 자료 등이 필요하시다면 직접 레포트를 확인해보시길 권장드립니다!
혹시라도 잘못되거나 부족한 내용이 있다면 댓글 부탁드립니다 🙇♂️
구글의 PaLM을 개선한 최신 multi-lingual 모델. 5/11 구글 I/O에서 공개.
- 결론
- PaLM 2는 PaLM에 비해 더 짧은 추론 시간으로 훨씬 좋은 결과물을 내는 SOTA 모델이다.
- PaLM 2는 다양한 태스크, 다양한 언어에 대해 우수한 성능을 보인다.
- 모델의 성능을 향상시키기 위해서는 훈련 토큰수와 모델 사이즈를 1:1 비율로 키워야 한다.
- 아키텍쳐와 object를 개선하는 것도 모델의 성능 향상에 큰 영향을 준다.
- 학습을 위한 데이터 선별도 아주 중요하다.
- 한정된 자원으로는 사이즈가 작은 모델에 더 많은 학습 데이터를 사용하는 것이 좋다.
- 배경
흔히 인공 지능 모델의 사이즈를 키우면(파라미터수를 늘리면) 일정 크기 이상부터는 emergent ability가 나타나는 것으로 알려져있다.
이때 단순히 모델의 사이즈만 키우는 것이 아니라 학습에 사용되는 데이터의 양을 늘리는 것도 중요한 과제이다.
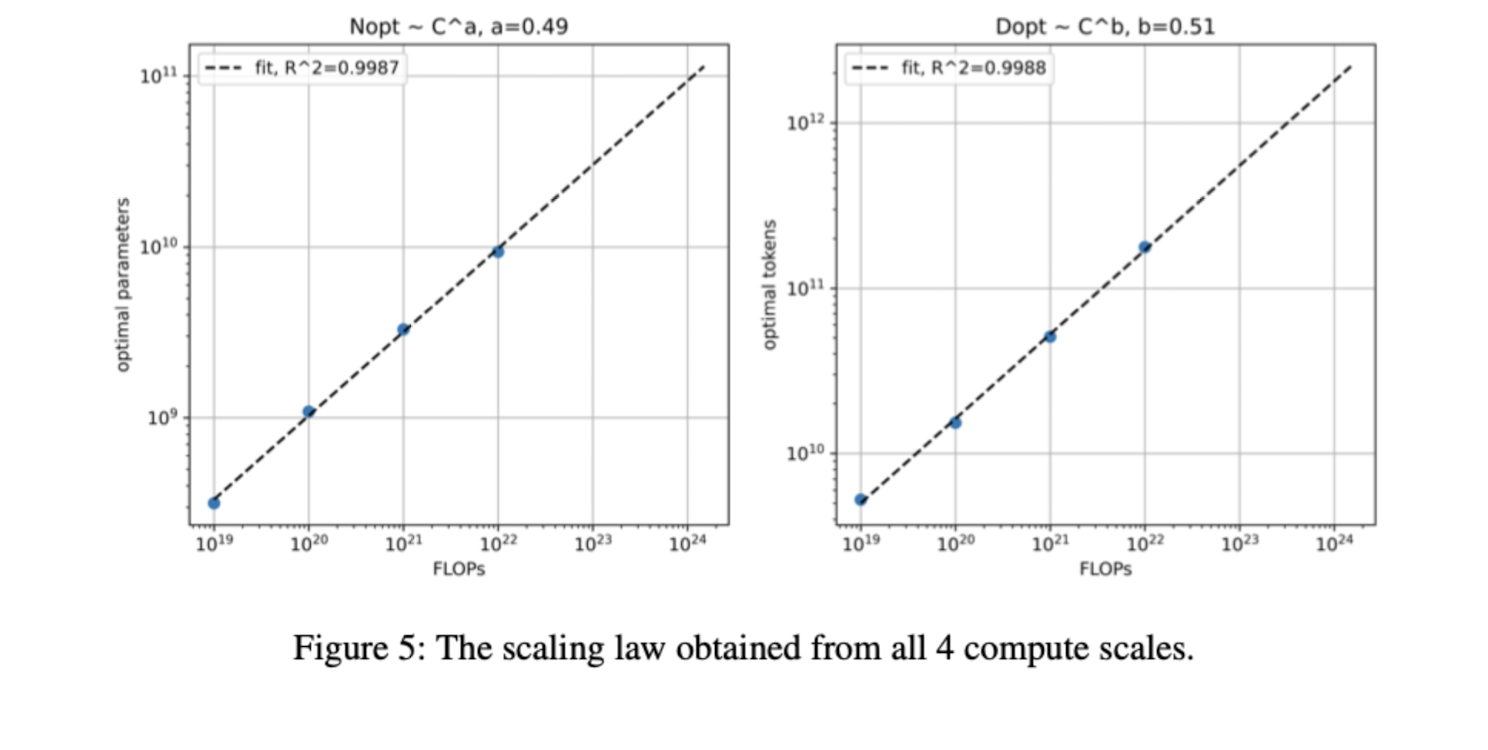
둘의 비율을 어떻게 조정할 것인지에 대한 연구도 존재하는데, 본 report에서는 둘을 1:1 비율로 scaling하는 것이 가장 최적의 결과로 이어졌음을 보여주었다.
또한 multi-lingual 모델의 특징을 잘 살릴 수 있도록 이전에 비해 더욱 다양한 종류의 언어 데이터를 선별했다.
뿐만 아니라 기존의 single causal / masked language modeling과 같은 object 등을 조합함으로써 모델의 다양한 언어의 여러 특징을 잘 학습할 수 있도록 했다.
이 모델의 특징 중 하나는 toxicity를 나타내는 스페셜 토큰을 사용했다는 것이다.
추론 단계에서 이 값을 조정하여 원하는 결과를 유도할 수 있다.
GPT 계열의 모델로 치면 temperature와 유사한 역할을 담당하는 것으로 이해할 수 있다.
- 평가
모델의 성능을 다양한 태스크에 대해서 검증했다.
사실 technical report나 paper에는 우수한 결과 혹은 이유가 거의 확실하게 밝혀진 경우들만 기록되기 때문에 아래 작성할 목록들에 대해서 PaLM 2가 뛰어난 성능을 보였다고 이해하면 쉽다.
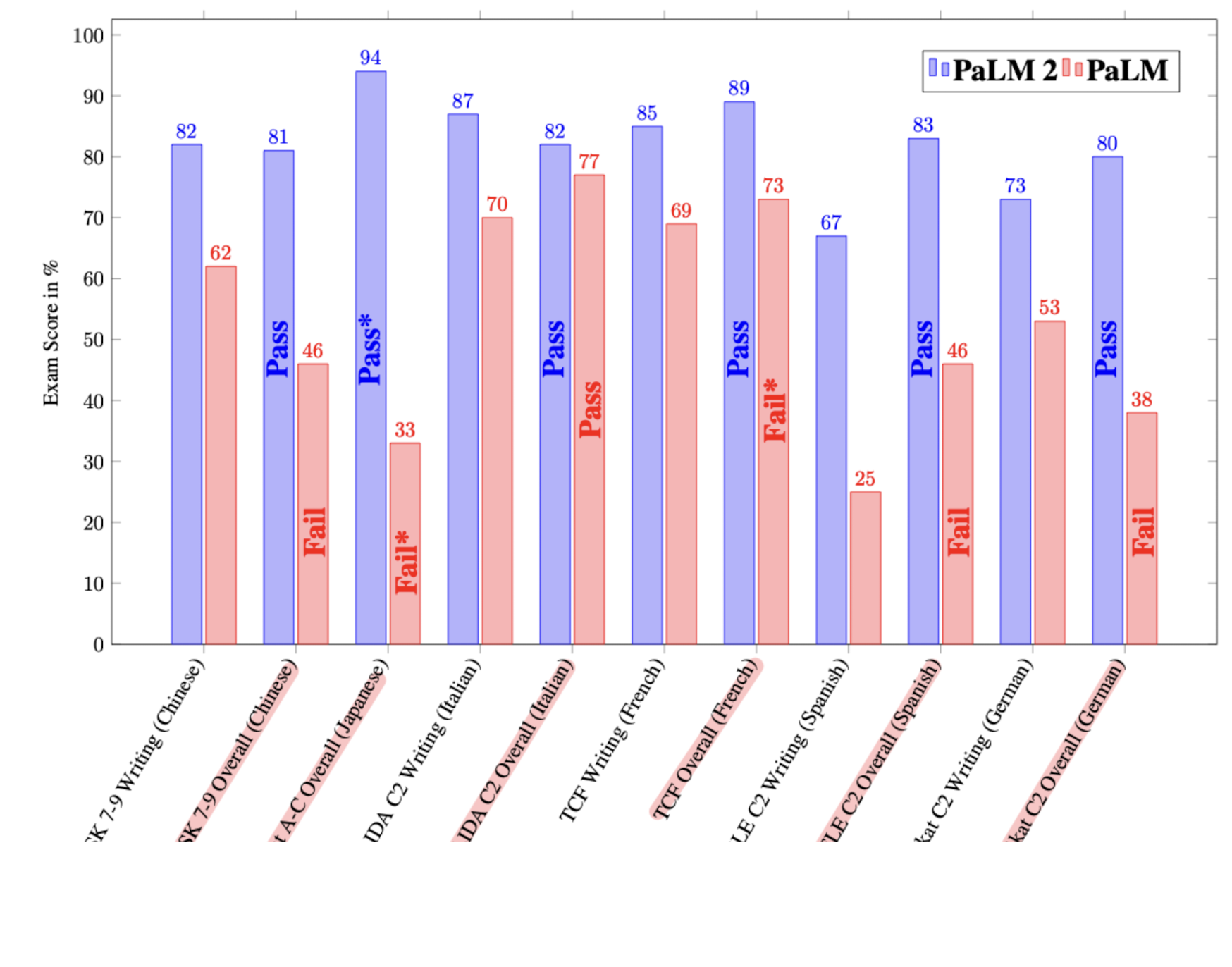
1. Language proficiency exams : PaLM에서는 통과하지 못했던 언어 시험도 좋은 성적으로 통과하기도 했다.
2. Classification and question answering : English QA and classification task, Multilingual QA, Multilingual capabilities 등
3. Reasoning : BIG-Bench Hard, Mathematical reasoning
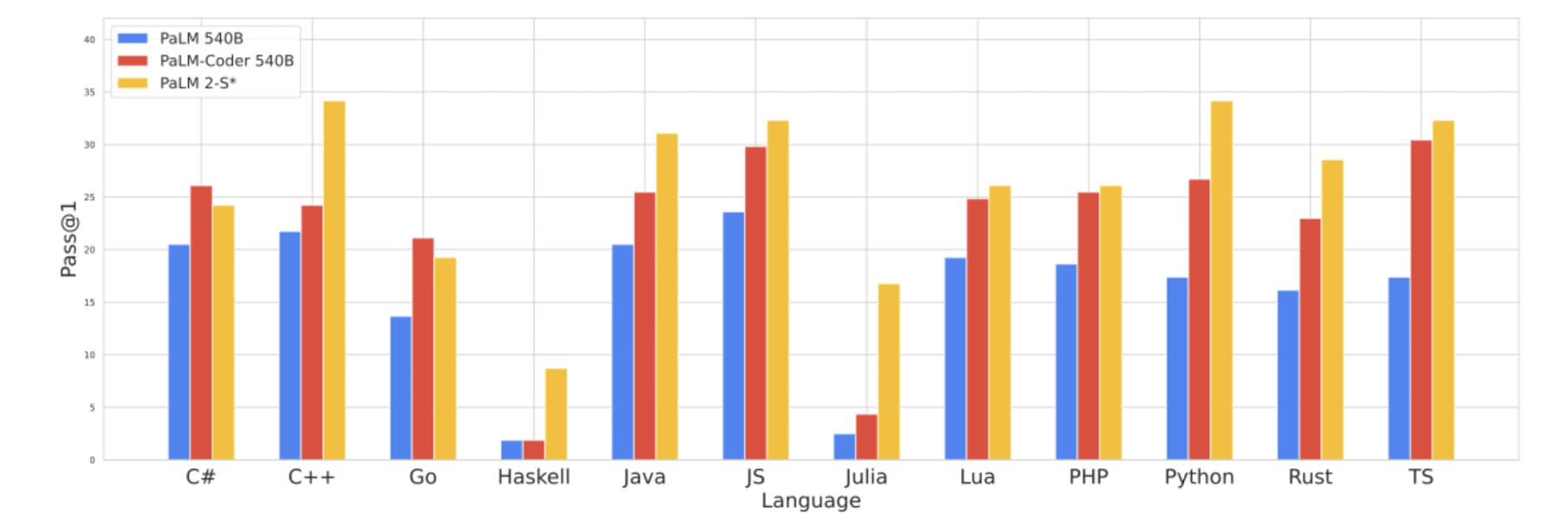
4. Coding : Code Generation, Multilingual Evaluation
5. Translation : WMT21 Experimental Setup, Regional translation experimental setup
6. Natural language generation : Evaluation on filtered datasets, Potential harms and bias
7. Memorization : Verbatim memorization, Improving memorization analysis with canaries, Memorization of the tail. 암기력이 오히려 낮아야 privacy 문제에서 안전
- 개인적 감상
극단적이긴 하지만.. 아직까지는 뭔가 요란한 껍데기같은 느낌이다.
GPT-4가 발표되었을 때의 패턴과 동일하다.
전작에 비해 어떤 식으로 개선이 이뤄졌고 앞으로의 발전 방향성이 무엇인지 갈피를 잡기는 굉장히 어렵고, 단순히 다양한 데이터를 때려 박고 모델의 사이즈를 키운 것만이 눈에 띄는 글이다.
나는 연구자의 수준도 아니지만 어떤 발전적인 내용을 쉽게 캐치하기 어렵다는 점에 대해서는 아쉽다는 생각이 든다.
기대가 되면서도 걱정되는 부분은 실제 모델이 활용될 가능성과 활용되었을 때의 성능이다.
구글이 부랴부랴 내놓은듯한 Bard는 LaMDA를 기반으로 한 서비스였는데 결국 성능이 좋지 않아서 사람들의 혹평을 피하지 못했다.
그래서 초거대언어모델 PaLM으로 대체될 계획을 알린 적 있었는데 이미 챗봇 시장은 OpenAI와 Microsoft에 의해 점령되었다는 느낌을 지우기는 어려운 것 같다.
현시점에서 PaLM의 성능도 아직 검증되기까지는 멀었다고 느껴지는데 과연 유의미한 성과가 있는게 맞을지 의심스럽다.
그렇게 뛰어나다는 GPT-4 조차도 공개된지 한 달이 넘은 지금 시점에, 대중들에게는 plug-in 공개도 못하고 multi-modal 기능도 제공하지 못하는 상태인데..
그런 GPT-4와 비교했을 때 일부 태스크에서 근사한 성능이라고 한다면.. 🤨
출처 : https://ai.google/discover/palm2
Google AI PaLM 2 – Google AI
PaLM 2 - Google’s next generation large language model.
ai.google
'Paper Review' 카테고리의 다른 글
오늘 5/11(목), 한국 기준 새벽 두 시에 Google I/O가 시작되었죠!
저는 자느라고 못 봤지만 일어나보니 재밌는 뉴스들이 조금 있는 것 같았습니다.
폴더블 스마트폰의 출시도 앞으로 시장에 어떤 영향을 줄지 기대가 되는데요,
역시 가장 눈에 띄는 것은 PaLM 2의 등장이겠죠?
이것도 논문..은 아니고 technical report의 형태로 실험 결과 등이 공개되었는데 이를 살펴보고 간략하게 정리해보았습니다.
어차피 아키텍쳐나 구체적인 학습 방법 등에 대한 설명은 포함되지 않았기에 최대한 간단히 특징들만 추려보았어요.
좀 더 자세한 내용이 궁금하시거나 자료 등이 필요하시다면 직접 레포트를 확인해보시길 권장드립니다!
혹시라도 잘못되거나 부족한 내용이 있다면 댓글 부탁드립니다 🙇♂️
구글의 PaLM을 개선한 최신 multi-lingual 모델. 5/11 구글 I/O에서 공개.
- 결론
- PaLM 2는 PaLM에 비해 더 짧은 추론 시간으로 훨씬 좋은 결과물을 내는 SOTA 모델이다.
- PaLM 2는 다양한 태스크, 다양한 언어에 대해 우수한 성능을 보인다.
- 모델의 성능을 향상시키기 위해서는 훈련 토큰수와 모델 사이즈를 1:1 비율로 키워야 한다.
- 아키텍쳐와 object를 개선하는 것도 모델의 성능 향상에 큰 영향을 준다.
- 학습을 위한 데이터 선별도 아주 중요하다.
- 한정된 자원으로는 사이즈가 작은 모델에 더 많은 학습 데이터를 사용하는 것이 좋다.
- 배경
흔히 인공 지능 모델의 사이즈를 키우면(파라미터수를 늘리면) 일정 크기 이상부터는 emergent ability가 나타나는 것으로 알려져있다.
이때 단순히 모델의 사이즈만 키우는 것이 아니라 학습에 사용되는 데이터의 양을 늘리는 것도 중요한 과제이다.
둘의 비율을 어떻게 조정할 것인지에 대한 연구도 존재하는데, 본 report에서는 둘을 1:1 비율로 scaling하는 것이 가장 최적의 결과로 이어졌음을 보여주었다.
또한 multi-lingual 모델의 특징을 잘 살릴 수 있도록 이전에 비해 더욱 다양한 종류의 언어 데이터를 선별했다.
뿐만 아니라 기존의 single causal / masked language modeling과 같은 object 등을 조합함으로써 모델의 다양한 언어의 여러 특징을 잘 학습할 수 있도록 했다.
이 모델의 특징 중 하나는 toxicity를 나타내는 스페셜 토큰을 사용했다는 것이다.
추론 단계에서 이 값을 조정하여 원하는 결과를 유도할 수 있다.
GPT 계열의 모델로 치면 temperature와 유사한 역할을 담당하는 것으로 이해할 수 있다.
- 평가
모델의 성능을 다양한 태스크에 대해서 검증했다.
사실 technical report나 paper에는 우수한 결과 혹은 이유가 거의 확실하게 밝혀진 경우들만 기록되기 때문에 아래 작성할 목록들에 대해서 PaLM 2가 뛰어난 성능을 보였다고 이해하면 쉽다.
1. Language proficiency exams : PaLM에서는 통과하지 못했던 언어 시험도 좋은 성적으로 통과하기도 했다.
2. Classification and question answering : English QA and classification task, Multilingual QA, Multilingual capabilities 등
3. Reasoning : BIG-Bench Hard, Mathematical reasoning
4. Coding : Code Generation, Multilingual Evaluation
5. Translation : WMT21 Experimental Setup, Regional translation experimental setup
6. Natural language generation : Evaluation on filtered datasets, Potential harms and bias
7. Memorization : Verbatim memorization, Improving memorization analysis with canaries, Memorization of the tail. 암기력이 오히려 낮아야 privacy 문제에서 안전
- 개인적 감상
극단적이긴 하지만.. 아직까지는 뭔가 요란한 껍데기같은 느낌이다.
GPT-4가 발표되었을 때의 패턴과 동일하다.
전작에 비해 어떤 식으로 개선이 이뤄졌고 앞으로의 발전 방향성이 무엇인지 갈피를 잡기는 굉장히 어렵고, 단순히 다양한 데이터를 때려 박고 모델의 사이즈를 키운 것만이 눈에 띄는 글이다.
나는 연구자의 수준도 아니지만 어떤 발전적인 내용을 쉽게 캐치하기 어렵다는 점에 대해서는 아쉽다는 생각이 든다.
기대가 되면서도 걱정되는 부분은 실제 모델이 활용될 가능성과 활용되었을 때의 성능이다.
구글이 부랴부랴 내놓은듯한 Bard는 LaMDA를 기반으로 한 서비스였는데 결국 성능이 좋지 않아서 사람들의 혹평을 피하지 못했다.
그래서 초거대언어모델 PaLM으로 대체될 계획을 알린 적 있었는데 이미 챗봇 시장은 OpenAI와 Microsoft에 의해 점령되었다는 느낌을 지우기는 어려운 것 같다.
현시점에서 PaLM의 성능도 아직 검증되기까지는 멀었다고 느껴지는데 과연 유의미한 성과가 있는게 맞을지 의심스럽다.
그렇게 뛰어나다는 GPT-4 조차도 공개된지 한 달이 넘은 지금 시점에, 대중들에게는 plug-in 공개도 못하고 multi-modal 기능도 제공하지 못하는 상태인데..
그런 GPT-4와 비교했을 때 일부 태스크에서 근사한 성능이라고 한다면.. 🤨
출처 : https://ai.google/discover/palm2
Google AI PaLM 2 – Google AI
PaLM 2 - Google’s next generation large language model.
ai.google