최근에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
언어가 지닌 ambiguity(모호성)을 인공지능 모델이 이해할 수 있는지 확인할 수 있는 벤치마크 제작
- 배경
언어의 모호성(ambiguity)는 인간 언어 이해에 있어서 중요한 요소입니다.
중의적인 표현에 대한 해석을 간단한 예로 떠올려 볼 수 있습니다.
때로는 문법적인 오류로 인해 중의적인 의미를 지니는 문장이 될 수도 있지만, 주변 단어들과의 관계에 의해 의미 차이가 발생하는 경우도 존재합니다.
LLM을 기반으로 한 챗봇, 즉 대화형 인공지능 모델이 큰 인기를 얻음에 따라, 인공지능 모델이 사람의 언어에 존재하는 이러한 모호성을 이해하고 좋은 판단을 내릴 수 있는지에 대한 관심도 커지고 있습니다.
맥락을 잘 파악하고 중의적인 표현을 이해하거나 잘 사용하는 모델에 대해서는 흔히 ‘센스가 있다’고 표현하곤 합니다.
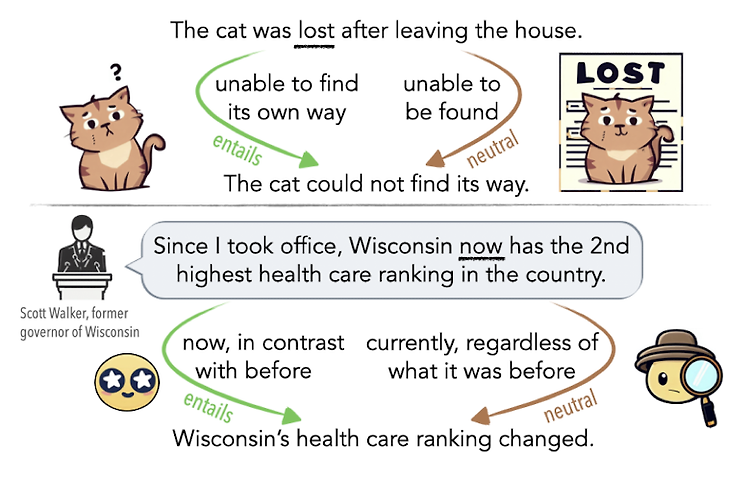
본 논문에서는 이와 같은 문장의 모호성에 대해 인공지능 모델이 인지하고 있는 정도를 측정할 수 있는 NLI 벤치마크를 구성했습니다.
- 특징
인공지능 모델의 ambiguity에 관한 능력을 파악하기 위해 NLI(Natural Language Interface) 벤치마크를 구성했습니다.
이는 premise(전제), hypothesis(가설) 쌍으로 구성되어 있으며 이에 대한 label(가설)은 entailment(포함), neutral(중립), contradiction(상충) 관계 중 하나입니다.
이처럼 기존의 NLI 태스크는 three-way 방식으로 접근하는 것에 반해, 본 논문에서는 여러 개의 정답이 존재할 수 있는 multi-label 방식으로도 이 문제를 풀어낸 것을 연구 결과에 담았습니다.
데이터를 제작하는 방식은 크게 두 가지로 나뉩니다.
curation과 generation입니다.
기존의 데이터셋을 손보는 것과, 인공지능 모델을 통해 생성하고 label을 annotation한 것으로 구분된다고 이해할 수 있습니다.
- 개인적 감상
본 논문에서처럼 인공지능 모델(특히 GPT-4)을 이용하여 데이터셋을 제작하고 이를 이용하여 학습을 하는 등의 방식을 보면 참 묘한 기분이 드는 것 같습니다.
컴퓨터가 학습하기 위한 데이터를 컴퓨터가 생성하고, 이를 사람이 사용하며 새로운 데이터가 생겨나며, 다시 이것으로 학습이 반복되는 이 독특한 구조가 참 기묘한 것 같습니다.
심지어 데이터를 생성하는 과정에서 사람이 평가를 내리고, 사람 간의 평가가 얼마나 일치하는지도 수치화하여 비교하고..
특정 태스크를 처리하거나 목적을 달성하기 위해 필요한 데이터들을 모으는 새로운 방식이 자리를 잡은 것이기도 하지만, 그렇다면 어떤 작업을 잘 처리하는 모델이라는 것도 지나치게 주관적인 기준에 의한 것이 아닐까하는 생각이 계속 듭니다.
결국 지금까지도 억지로 수치화하고는 있지만 사실 그렇게 유지하는 것이 너무 어려워 보인다는 느낌..?
그렇기 때문에 이 논문에서도 NLI로 벤치마크를 구성한 것도 약간 억지스럽게 느껴지는 듯합니다.
왜냐하면 사람의 언어라는 것은 당연히도 ‘포함’, ‘중립’, ‘대립’관계로만 구성되는 것이 아니기 때문이죠…
이것이 언어 간의 보편적인 관계인 것도 맞지만 이러한 평가 지표는 과연 정말로 이전의 것과 달리 유의미한 것인가,라는 질문에 명쾌한 대답이 나오기는 어렵다는 느낌입니다.
출처 : https://arxiv.org/abs/2304.14399
We're Afraid Language Models Aren't Modeling Ambiguity
Ambiguity is an intrinsic feature of natural language. Managing ambiguity is a key part of human language understanding, allowing us to anticipate misunderstanding as communicators and revise our interpretations as listeners. As language models (LMs) are i
arxiv.org
'Paper Review' 카테고리의 다른 글
최근에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
언어가 지닌 ambiguity(모호성)을 인공지능 모델이 이해할 수 있는지 확인할 수 있는 벤치마크 제작
- 배경
언어의 모호성(ambiguity)는 인간 언어 이해에 있어서 중요한 요소입니다.
중의적인 표현에 대한 해석을 간단한 예로 떠올려 볼 수 있습니다.
때로는 문법적인 오류로 인해 중의적인 의미를 지니는 문장이 될 수도 있지만, 주변 단어들과의 관계에 의해 의미 차이가 발생하는 경우도 존재합니다.
LLM을 기반으로 한 챗봇, 즉 대화형 인공지능 모델이 큰 인기를 얻음에 따라, 인공지능 모델이 사람의 언어에 존재하는 이러한 모호성을 이해하고 좋은 판단을 내릴 수 있는지에 대한 관심도 커지고 있습니다.
맥락을 잘 파악하고 중의적인 표현을 이해하거나 잘 사용하는 모델에 대해서는 흔히 ‘센스가 있다’고 표현하곤 합니다.
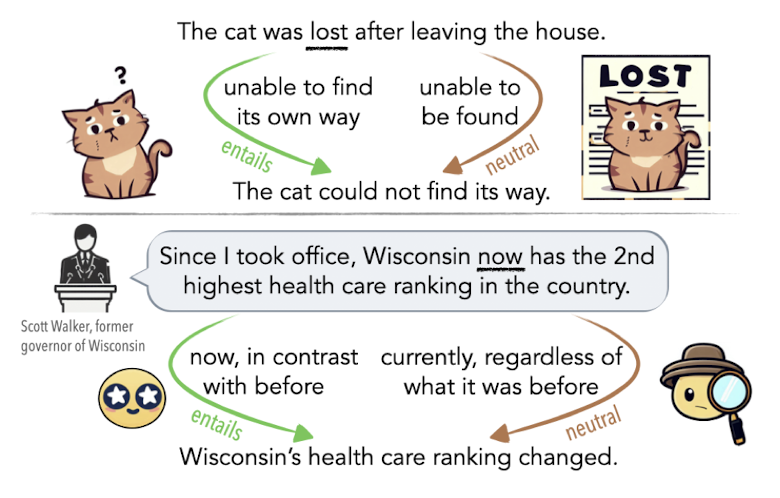
본 논문에서는 이와 같은 문장의 모호성에 대해 인공지능 모델이 인지하고 있는 정도를 측정할 수 있는 NLI 벤치마크를 구성했습니다.
- 특징
인공지능 모델의 ambiguity에 관한 능력을 파악하기 위해 NLI(Natural Language Interface) 벤치마크를 구성했습니다.
이는 premise(전제), hypothesis(가설) 쌍으로 구성되어 있으며 이에 대한 label(가설)은 entailment(포함), neutral(중립), contradiction(상충) 관계 중 하나입니다.
이처럼 기존의 NLI 태스크는 three-way 방식으로 접근하는 것에 반해, 본 논문에서는 여러 개의 정답이 존재할 수 있는 multi-label 방식으로도 이 문제를 풀어낸 것을 연구 결과에 담았습니다.
데이터를 제작하는 방식은 크게 두 가지로 나뉩니다.
curation과 generation입니다.
기존의 데이터셋을 손보는 것과, 인공지능 모델을 통해 생성하고 label을 annotation한 것으로 구분된다고 이해할 수 있습니다.
- 개인적 감상
본 논문에서처럼 인공지능 모델(특히 GPT-4)을 이용하여 데이터셋을 제작하고 이를 이용하여 학습을 하는 등의 방식을 보면 참 묘한 기분이 드는 것 같습니다.
컴퓨터가 학습하기 위한 데이터를 컴퓨터가 생성하고, 이를 사람이 사용하며 새로운 데이터가 생겨나며, 다시 이것으로 학습이 반복되는 이 독특한 구조가 참 기묘한 것 같습니다.
심지어 데이터를 생성하는 과정에서 사람이 평가를 내리고, 사람 간의 평가가 얼마나 일치하는지도 수치화하여 비교하고..
특정 태스크를 처리하거나 목적을 달성하기 위해 필요한 데이터들을 모으는 새로운 방식이 자리를 잡은 것이기도 하지만, 그렇다면 어떤 작업을 잘 처리하는 모델이라는 것도 지나치게 주관적인 기준에 의한 것이 아닐까하는 생각이 계속 듭니다.
결국 지금까지도 억지로 수치화하고는 있지만 사실 그렇게 유지하는 것이 너무 어려워 보인다는 느낌..?
그렇기 때문에 이 논문에서도 NLI로 벤치마크를 구성한 것도 약간 억지스럽게 느껴지는 듯합니다.
왜냐하면 사람의 언어라는 것은 당연히도 ‘포함’, ‘중립’, ‘대립’관계로만 구성되는 것이 아니기 때문이죠…
이것이 언어 간의 보편적인 관계인 것도 맞지만 이러한 평가 지표는 과연 정말로 이전의 것과 달리 유의미한 것인가,라는 질문에 명쾌한 대답이 나오기는 어렵다는 느낌입니다.
출처 : https://arxiv.org/abs/2304.14399
We're Afraid Language Models Aren't Modeling Ambiguity
Ambiguity is an intrinsic feature of natural language. Managing ambiguity is a key part of human language understanding, allowing us to anticipate misunderstanding as communicators and revise our interpretations as listeners. As language models (LMs) are i
arxiv.org