
최근에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
LLaVA: Large Language and Vision Assistant, end-to-end 거대 멀티모달 모델. vision encoder와 LLM을 연결한 구조를 갖고 있다.
- 배경
인공지능 모델이 생성한 데이터를 기반으로 LLM을 Instruction tuning하는 것이 모델의 성능 향상에 큰 도움이 된다는 것은 잘 알려져 있다.
이런 방식을 통해 모델은 다양한 태스크를 두루 잘 처리할 수 있게 되었고, 덕분에 instruction tuning에 대한 관심이 뜨겁다.
그러나 multi-modal 분야(그중에서도 image-text)에 대해서는 자연어로 이미지를 간단히 설명하는 수준의 데이터셋만 존재했기에 사용자의 instruction을 제대로 따르기 어려운 상황이 이어졌다.
본 논문에서는 기존의 한계를 극복하기 위해 ChatGPT나 GPT-4를 이용하여 multimodal instruction-following data를 생성하고 이것으로 학습한 모델, LLaVA를 제안한다.
- Visual Instruction 데이터 생성(GPT-assisted)
이미지 Xv, caption Xc, 질문 Xq에 대해 다음과 같은 포맷을 따른다.
Human : Xq Xv <STOP>
Assistant : Xc <STOP> \n
이때 caption은 다양한 관점에서 시각적 자료를 묘사한 것을 말한다.
또한 이미지 내에 탐지된 사물의 위치에 대한 정보인 bounding boxes도 포함될 수 있다.
한편 데이터는 Conversation, Detailed Description, Coplex Reasoning 셋 중 하나의 방식으로 생성된다.
- 모델 컨셉
backbone이 되는 LLM은 LLaMA이다.
이미지를 encoding하는 것은 CLIP visual encoder인 ViT-L/14이다.
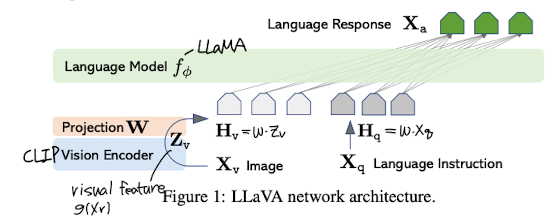
입력으로 받은 이미지와 instruction을 각각 embedding하고, 이를 projection matrix와 곱한 뒤 두 결과를 연결한다.
이를 바탕으로 response를 생성하게 된다.
- 개인적 감상
👍🏻
이 논문도 Microsoft와 연관이 있던데 진짜 무서울 지경이다 ㄷㄷ..
여기서 가장 흥미로운 점은 ‘GPT로 필요한 데이터셋을 생성한다’는 것이다.
LLM의 성능 향상으로 인해 사람들이 가장 많이 기대하는 것 중 하나는 자동화인 것 같다.
여러가지 일들을 정말 사람의 수준으로 처리할 수 있게 되는데, 그것이 심지어 사람의 언어 형태를 갖춘 결과물을 반환한다면 어떨까.
실제로 사람들이 평가 데이터를 annotation한 것보다 GPT-4가 한 것이 더 좋은 결과물이었다는 연구 결과도 존재한다.
앞으로는 사람이 직접 수행하기에는 너무 비효율적인(시간과 자원을 지나치게 많이 필요로하는) 작업들을 LLM이 대체할 여지가 더 많을 것이라는 생각이 더욱 확고하게 들었다.
👎🏻
개인적으로 가독성도 좋고 내용도 좋은 잘 쓰인 논문이라는 생각이 들어서 아쉬울 건 크게 없는 것 같다.
약간의 궁금증 정도라면 왜 backbone LLM을 LLaMA로 사용했는가..정도?
어떤 특장점에 대해서 논한 내용을 잘 찾아보지 못했는데 왜 많은 모델중에 이것을 사용하는지에 대한 설명도 디테일하게 포함되어 있었으면 좋겠다는 생각이 들었다.
출처 : https://arxiv.org/abs/2304.08485
Visual Instruction Tuning
Instruction tuning large language models (LLMs) using machine-generated instruction-following data has improved zero-shot capabilities on new tasks, but the idea is less explored in the multimodal field. In this paper, we present the first attempt to use l
arxiv.org
'Paper Review' 카테고리의 다른 글
| <Normalzation> ResiDual: Transformer with Dual Residual Connections (0) | 2023.05.13 |
|---|---|
| <LLM> PaLM2 Technical Report (0) | 2023.05.11 |
| <Prompt> [Gist] Learning to Compress Prompts with Gist Tokens (1) | 2023.05.09 |
| <Reasoning> [Self-Notes] Learning to Reason and Memorize with Self-Notes (0) | 2023.05.08 |
| <PEFT> LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model (0) | 2023.05.07 |
최근에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
LLaVA: Large Language and Vision Assistant, end-to-end 거대 멀티모달 모델. vision encoder와 LLM을 연결한 구조를 갖고 있다.
- 배경
인공지능 모델이 생성한 데이터를 기반으로 LLM을 Instruction tuning하는 것이 모델의 성능 향상에 큰 도움이 된다는 것은 잘 알려져 있다.
이런 방식을 통해 모델은 다양한 태스크를 두루 잘 처리할 수 있게 되었고, 덕분에 instruction tuning에 대한 관심이 뜨겁다.
그러나 multi-modal 분야(그중에서도 image-text)에 대해서는 자연어로 이미지를 간단히 설명하는 수준의 데이터셋만 존재했기에 사용자의 instruction을 제대로 따르기 어려운 상황이 이어졌다.
본 논문에서는 기존의 한계를 극복하기 위해 ChatGPT나 GPT-4를 이용하여 multimodal instruction-following data를 생성하고 이것으로 학습한 모델, LLaVA를 제안한다.
- Visual Instruction 데이터 생성(GPT-assisted)
이미지 Xv, caption Xc, 질문 Xq에 대해 다음과 같은 포맷을 따른다.
Human : Xq Xv <STOP>
Assistant : Xc <STOP> \n
이때 caption은 다양한 관점에서 시각적 자료를 묘사한 것을 말한다.
또한 이미지 내에 탐지된 사물의 위치에 대한 정보인 bounding boxes도 포함될 수 있다.
한편 데이터는 Conversation, Detailed Description, Coplex Reasoning 셋 중 하나의 방식으로 생성된다.
- 모델 컨셉
backbone이 되는 LLM은 LLaMA이다.
이미지를 encoding하는 것은 CLIP visual encoder인 ViT-L/14이다.
입력으로 받은 이미지와 instruction을 각각 embedding하고, 이를 projection matrix와 곱한 뒤 두 결과를 연결한다.
이를 바탕으로 response를 생성하게 된다.
- 개인적 감상
👍🏻
이 논문도 Microsoft와 연관이 있던데 진짜 무서울 지경이다 ㄷㄷ..
여기서 가장 흥미로운 점은 ‘GPT로 필요한 데이터셋을 생성한다’는 것이다.
LLM의 성능 향상으로 인해 사람들이 가장 많이 기대하는 것 중 하나는 자동화인 것 같다.
여러가지 일들을 정말 사람의 수준으로 처리할 수 있게 되는데, 그것이 심지어 사람의 언어 형태를 갖춘 결과물을 반환한다면 어떨까.
실제로 사람들이 평가 데이터를 annotation한 것보다 GPT-4가 한 것이 더 좋은 결과물이었다는 연구 결과도 존재한다.
앞으로는 사람이 직접 수행하기에는 너무 비효율적인(시간과 자원을 지나치게 많이 필요로하는) 작업들을 LLM이 대체할 여지가 더 많을 것이라는 생각이 더욱 확고하게 들었다.
👎🏻
개인적으로 가독성도 좋고 내용도 좋은 잘 쓰인 논문이라는 생각이 들어서 아쉬울 건 크게 없는 것 같다.
약간의 궁금증 정도라면 왜 backbone LLM을 LLaMA로 사용했는가..정도?
어떤 특장점에 대해서 논한 내용을 잘 찾아보지 못했는데 왜 많은 모델중에 이것을 사용하는지에 대한 설명도 디테일하게 포함되어 있었으면 좋겠다는 생각이 들었다.
출처 : https://arxiv.org/abs/2304.08485
Visual Instruction Tuning
Instruction tuning large language models (LLMs) using machine-generated instruction-following data has improved zero-shot capabilities on new tasks, but the idea is less explored in the multimodal field. In this paper, we present the first attempt to use l
arxiv.org
'Paper Review' 카테고리의 다른 글
| <Normalzation> ResiDual: Transformer with Dual Residual Connections (0) | 2023.05.13 |
|---|---|
| <LLM> PaLM2 Technical Report (0) | 2023.05.11 |
| <Prompt> [Gist] Learning to Compress Prompts with Gist Tokens (1) | 2023.05.09 |
| <Reasoning> [Self-Notes] Learning to Reason and Memorize with Self-Notes (0) | 2023.05.08 |
| <PEFT> LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model (0) | 2023.05.07 |