최근에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
단순히 추론 결과가 아닌 그에 대한 설명(rationale)을 학습하여 엄청나게 적은 자원과 작은 모델로 훌륭한 퍼포먼스를 내는 distillation 기법
- 배경
LLM의 훌륭한 능력을 이용하는 방법은 크게 finetuning, distillation 두 가지로 나눠집니다.
그러나 finetuning은 전체 파라미터를 학습해야 하기 때문에 computing 자원을 많이 필요로 하고, distillation은 unlabeled data가 많이 필요하며 특정 task에 대해서만 학습이 가능하다는 문제점이 존재합니다.
이러한 문제점을 해결하기 위해 ‘적은 자원’, ‘작은 모델 사이즈’, ‘적은 데이터’를 활용하여 ‘우수한 퍼포먼스’를 달성한 기법이 distilling step-by-step입니다.
이는 student 모델이 teacher 모델의 distribution을 그대로 학습하던 것과 달리, reasoning의 근거를 rationale로 풀어내고(CoT) 이 과정을 학습하는 방식입니다.
- 컨셉 & 결과
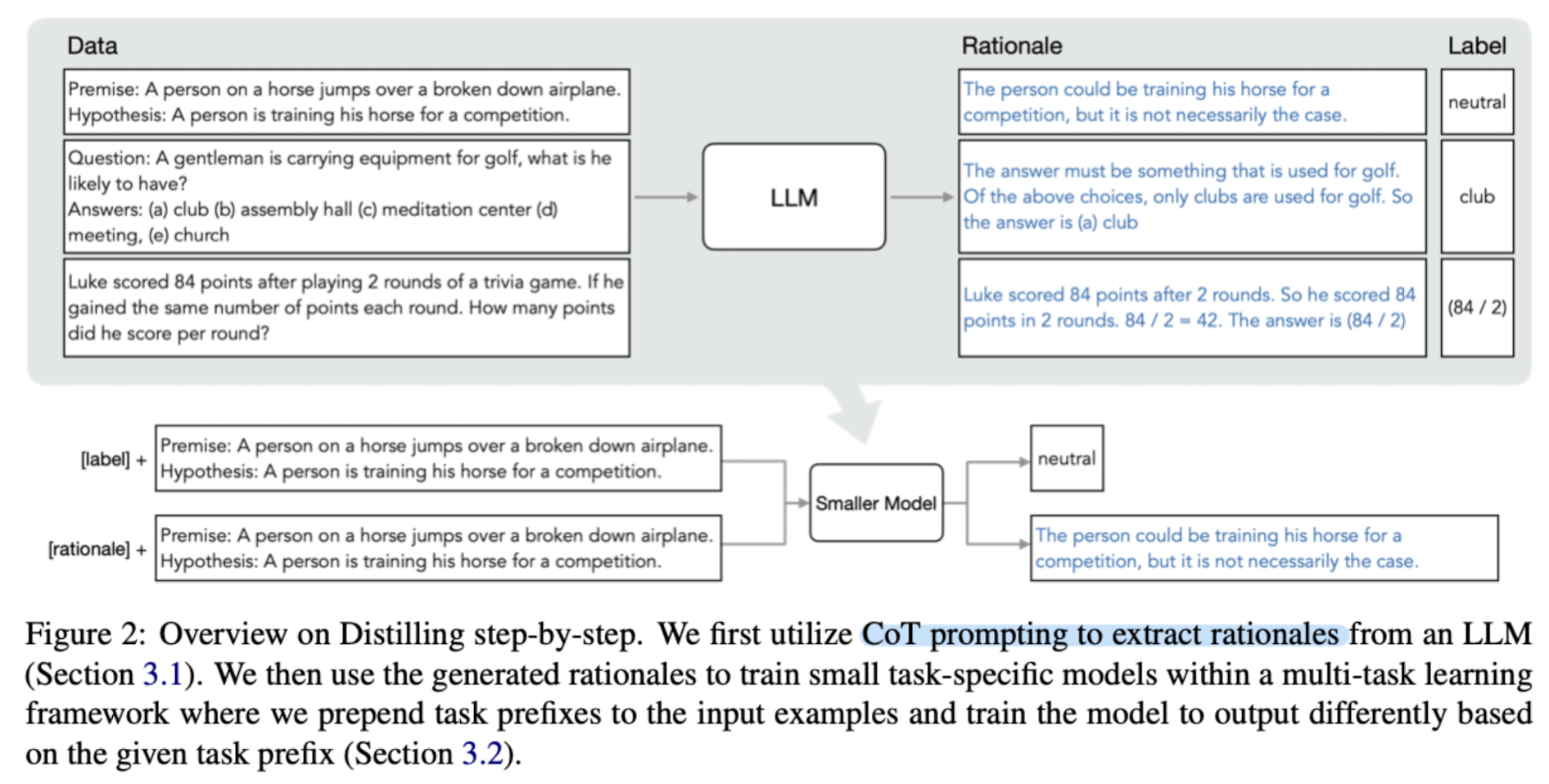
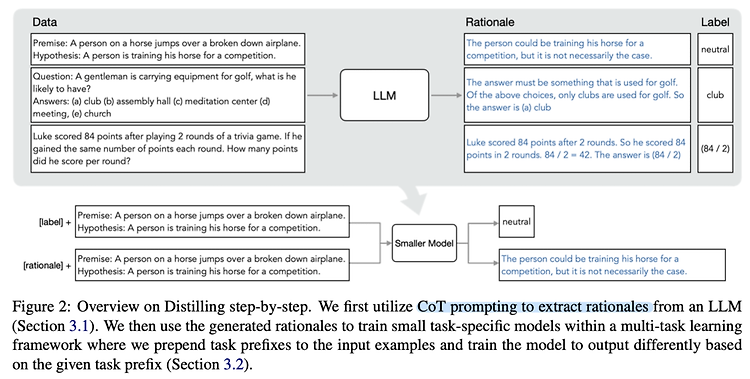
주어진 데이터를 바탕으로 LLM이 예측을 수행합니다.
이때 CoT 방식을 택하고, 예측 결과를 내놓기 전 중간 과정에 해당하는 Rationale 자체를 학습하도록 합니다.


따라서 기존에 입력, rationale을 바탕으로 label을 예측했던 것과 달리, 입력이 주어지면 어떤 rationale이 올지를 예측하게 되고 이것으로 loss를 구합니다.
그 결과 아래 예시 뿐만 아니라 여러 태스크에서 ‘더 작은 모델 사이즈, 더 적은 학습 데이터’로 ‘더 우수한 성능’을 이끌어내는 것에 성공했습니다.
- 개인적 감상
👍🏻
결과가 좋기 때문이기도 하지만 접근이 굉장히 좋다고 생각했습니다.
개인적으로는 이런 다양한 시도들에 대해서 특히나 인간적인 사고/학습 방식과 유사한 것들에 더욱 큰 흥미가 생기는 것 같아요.
우리가 수학 문제를 푼다고 했을 때 문제에 대한 정답을 외우는 것은 수학을 공부하는 데 있어서 전혀 도움이 되지 않습니다.
원리와 과정을 이해해야 한다는 관점에서는 이런 논리적인 사고와 과정이 필요한 태스크에 대해 학습하는 방식이 인간과 굉장히 유사하지 않나, 그렇기 때문에 성능이 좋았던 것이 아닐까 싶습니다.
👎🏻
한편 성능이 뛰어난만큼 다양한 케이스에 대해 강건한 것인지도 확인하면 좋았을 것 같다는 아쉬움이 남았습니다.
단순히 기존의 벤치마크로 확인하기에 조금 어렵지 않을까 싶기도 했거든요.
논문 저자도 언급하긴 했지만 좀 더 복잡한 추론이 필요한 문제들에 대해서는 어떻게 될 지에 대해서도 직접 다뤘다면 더 좋았을 것 같습니다.
출처 : https://arxiv.org/abs/2305.02301
Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes
Deploying large language models (LLMs) is challenging because they are memory inefficient and compute-intensive for practical applications. In reaction, researchers train smaller task-specific models by either finetuning with human labels or distilling usi
arxiv.org
'Paper Review' 카테고리의 다른 글
| <Multi-modal> IMAGEBIND: One Embedding Space to Bind Them All (0) | 2023.05.23 |
|---|---|
| <LLM> AutoML-GPT: Automatic Machine Learning with GPT (0) | 2023.05.21 |
| <Benchmark> [AmbiEnt] We're Afraid Language Models Aren't Modeling Ambiguity (0) | 2023.05.13 |
| <Normalzation> ResiDual: Transformer with Dual Residual Connections (0) | 2023.05.13 |
| <LLM> PaLM2 Technical Report (0) | 2023.05.11 |
최근에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
단순히 추론 결과가 아닌 그에 대한 설명(rationale)을 학습하여 엄청나게 적은 자원과 작은 모델로 훌륭한 퍼포먼스를 내는 distillation 기법
- 배경
LLM의 훌륭한 능력을 이용하는 방법은 크게 finetuning, distillation 두 가지로 나눠집니다.
그러나 finetuning은 전체 파라미터를 학습해야 하기 때문에 computing 자원을 많이 필요로 하고, distillation은 unlabeled data가 많이 필요하며 특정 task에 대해서만 학습이 가능하다는 문제점이 존재합니다.
이러한 문제점을 해결하기 위해 ‘적은 자원’, ‘작은 모델 사이즈’, ‘적은 데이터’를 활용하여 ‘우수한 퍼포먼스’를 달성한 기법이 distilling step-by-step입니다.
이는 student 모델이 teacher 모델의 distribution을 그대로 학습하던 것과 달리, reasoning의 근거를 rationale로 풀어내고(CoT) 이 과정을 학습하는 방식입니다.
- 컨셉 & 결과
주어진 데이터를 바탕으로 LLM이 예측을 수행합니다.
이때 CoT 방식을 택하고, 예측 결과를 내놓기 전 중간 과정에 해당하는 Rationale 자체를 학습하도록 합니다.
따라서 기존에 입력, rationale을 바탕으로 label을 예측했던 것과 달리, 입력이 주어지면 어떤 rationale이 올지를 예측하게 되고 이것으로 loss를 구합니다.
그 결과 아래 예시 뿐만 아니라 여러 태스크에서 ‘더 작은 모델 사이즈, 더 적은 학습 데이터’로 ‘더 우수한 성능’을 이끌어내는 것에 성공했습니다.
- 개인적 감상
👍🏻
결과가 좋기 때문이기도 하지만 접근이 굉장히 좋다고 생각했습니다.
개인적으로는 이런 다양한 시도들에 대해서 특히나 인간적인 사고/학습 방식과 유사한 것들에 더욱 큰 흥미가 생기는 것 같아요.
우리가 수학 문제를 푼다고 했을 때 문제에 대한 정답을 외우는 것은 수학을 공부하는 데 있어서 전혀 도움이 되지 않습니다.
원리와 과정을 이해해야 한다는 관점에서는 이런 논리적인 사고와 과정이 필요한 태스크에 대해 학습하는 방식이 인간과 굉장히 유사하지 않나, 그렇기 때문에 성능이 좋았던 것이 아닐까 싶습니다.
👎🏻
한편 성능이 뛰어난만큼 다양한 케이스에 대해 강건한 것인지도 확인하면 좋았을 것 같다는 아쉬움이 남았습니다.
단순히 기존의 벤치마크로 확인하기에 조금 어렵지 않을까 싶기도 했거든요.
논문 저자도 언급하긴 했지만 좀 더 복잡한 추론이 필요한 문제들에 대해서는 어떻게 될 지에 대해서도 직접 다뤘다면 더 좋았을 것 같습니다.
출처 : https://arxiv.org/abs/2305.02301
Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes
Deploying large language models (LLMs) is challenging because they are memory inefficient and compute-intensive for practical applications. In reaction, researchers train smaller task-specific models by either finetuning with human labels or distilling usi
arxiv.org
'Paper Review' 카테고리의 다른 글
| <Multi-modal> IMAGEBIND: One Embedding Space to Bind Them All (0) | 2023.05.23 |
|---|---|
| <LLM> AutoML-GPT: Automatic Machine Learning with GPT (0) | 2023.05.21 |
| <Benchmark> [AmbiEnt] We're Afraid Language Models Aren't Modeling Ambiguity (0) | 2023.05.13 |
| <Normalzation> ResiDual: Transformer with Dual Residual Connections (0) | 2023.05.13 |
| <LLM> PaLM2 Technical Report (0) | 2023.05.11 |