
최근에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Microsoft Research]
단순히 Large Foundation Models(LFMs)의 결론을 모방하지 않고, LFM의 추론 과정(reasoning process)을 배워야 성능 향상으로 이어진다.
그러나 아직까지도 LFM의 능력을 제대로 follow-up하지는 못한다(GPT-4의 벽).
ChatGPT가 뜨거운 관심을 받으면서 한편으로는 모델 경량화에 대한 관심도 엄청나게 커졌습니다.
지금도 마찬가지인게 GPT나 BARD 등 사람들에게 잘 알려진 챗봇의 기반이 되는 모델들의 사이즈가 너무 커져서 개인이 운용하기가 너무 힘들어졌기 때문입니다.
그러면서 주목을 받은 것이 모델의 사이즈는 작지만 LLM의 성능에 준하는 LLaMA와 같은 모델들입니다. 특히 여기에 다양한 tuning 기법을 적용하면서 성능을 최대치로 끌어올리는 연구가 인기가 많았습니다.
아주 대표적으로 Standford 대학에서 만든 alpaca나, ChatGPT와 실제 유저간의 대화 데이터를 바탕으로 학습한 Vicuna 등이 이에 속합니다.
이런 모델들도 굉장히 좋은 성능을 보이면서 사람들의 주목을 크게 받았는데요, 본 논문에서는 이런 모델들의 한계를 지적합니다.
바로 추론 및 이해 능력이 부족하다는 것이죠.
표현을 빌리자면 단순히 결과물만을 모방하는 방식으로는 제대로 학습하기 어렵다는 것입니다.
추론 능력이 요구되는 대표적인 태스크가 Math Word Problem Solving입니다.
하지만 일종의 distillation 기법으로 학습된 작은 모델들이 이와 같은 태스크를 유독 잘 처리하지 못한다는 것이 추론 능력을 얻지 못한채로 모방만 하고 있다는 증거가 되는 것이죠.
결국 저자는 <query, response> 데이터 쌍을 증강시키고 이러한 추론 과정을 위주로 모델을 학습시킵니다.
또 그냥 데이터 쌍의 개수를 증가시킨 것 뿐만 아니라 모델에게 제공하는 instruction의 난이도도 높였는데 이것이 유의미한 성능 향상으로 이어졌습니다.
이러한 학습 방식을 Explanation Tuning이라고 부릅니다.
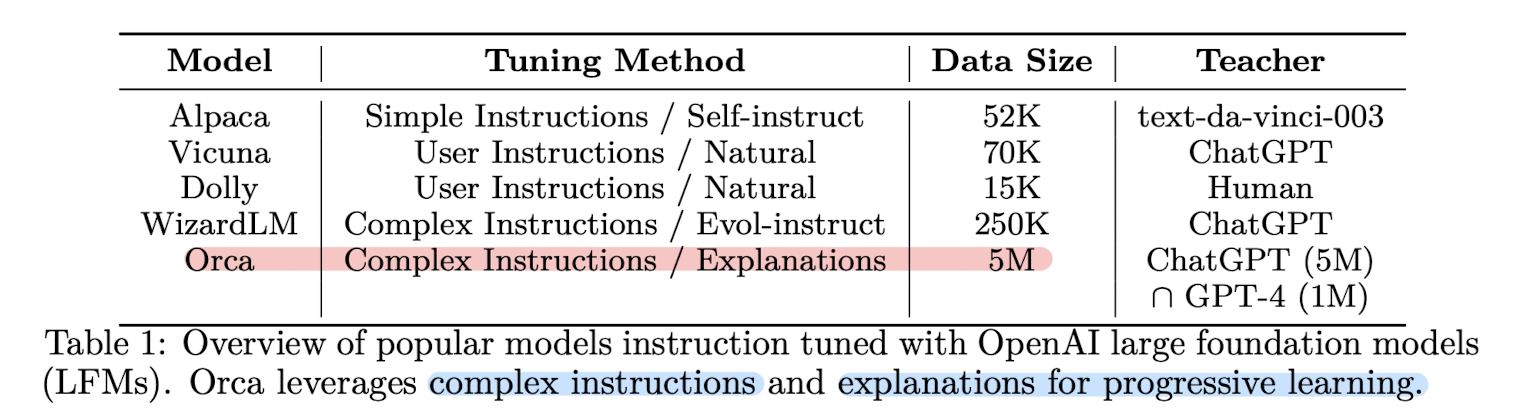
그래서 사실 학습 방법을 보면 일반적인 instruction tuning과 크게 차이가 있지는 않습니다.
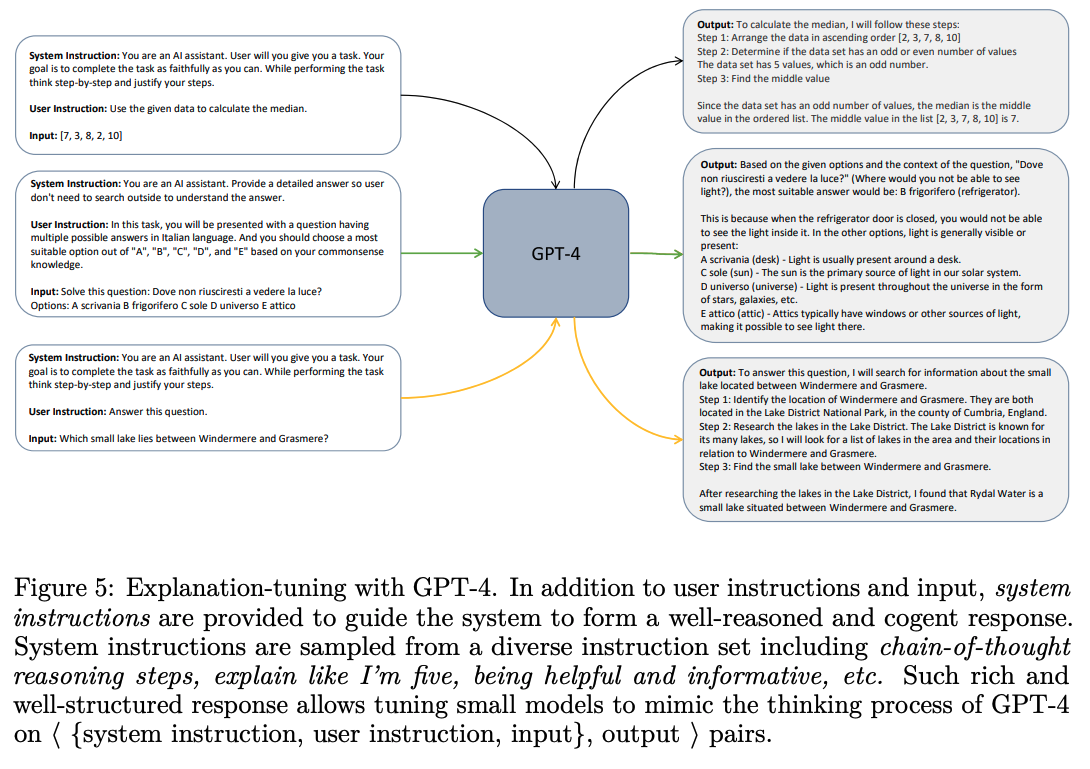
다만 GPT-4를 통해 < {system instruction, user instruction, input} , output > 쌍으로 학습한다는 차이점은 존재합니다.
본 논문에서 정리된 실험 결과를 살펴보면 그 결과를 한 문장으로 요약할 수 있습니다.
Orca는 Vicuna보다 확실히 뛰어나고, ChatGPT와는 비등하며, GPT-4에는 한참 뒤떨어진다.
사실 논문에서는 생성 관련 태스크들을 수행하면서 여러 모델들(모태는 다 GPT라고 봐야겠지만요..)을 비교했는데, 딱 위 문장으로 요약할 수 있는 결과들이 이어졌습니다.
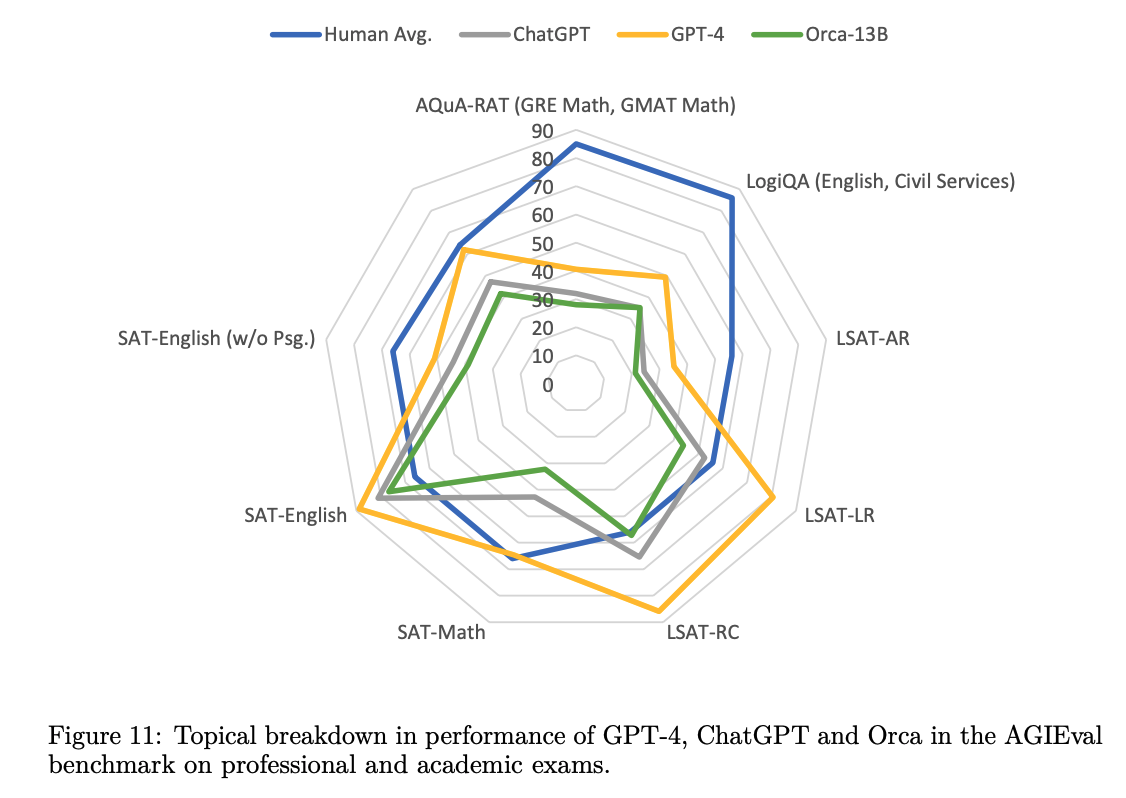
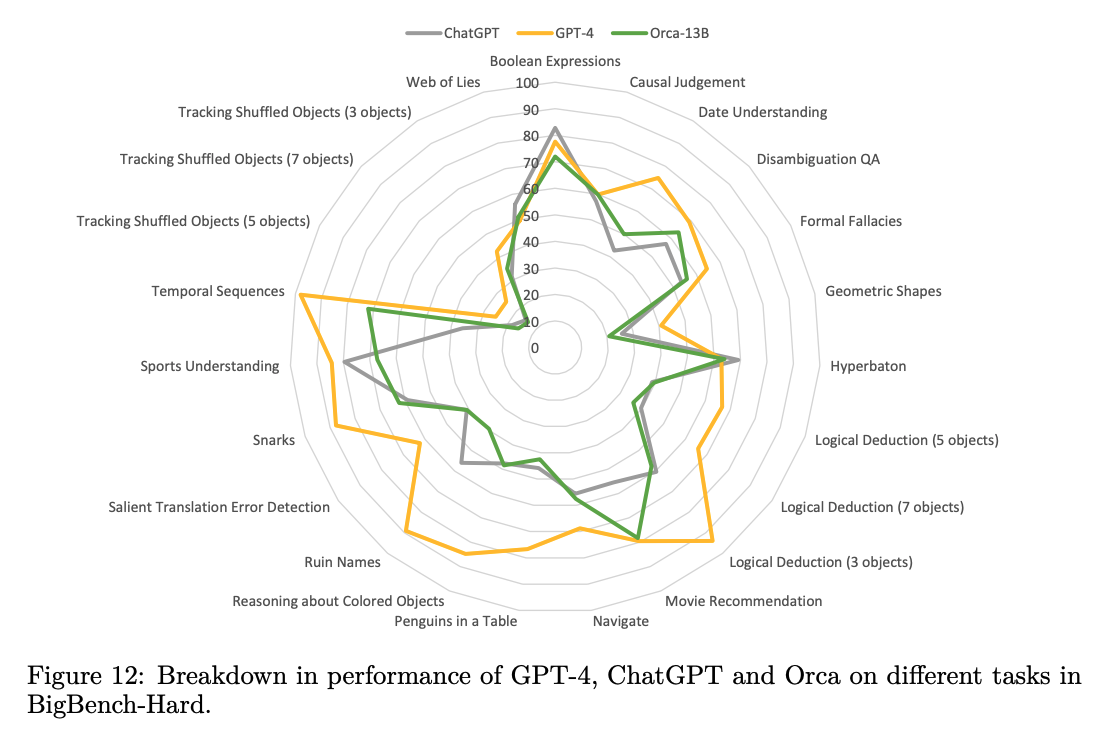
하지만 아이러니하게도 LFM이 아니기 때문에 일반적인 지식을 보유하거나 장기기억에 대한 능력이 부족해서 추론 능력이 떨어진다는 결과가 나옵니다.
한편 최근에 ChatGPT의 GPT-4에 plug-in 기능을 추가하여 외부 api를 활용하는 테크닉들이 잘 알려지고 있습니다.
이와 동일한 방식으로 Orca에 일종의 tool을 달아주어 성능을 확인해본 결과 이전에 비하면 LFM을 follow-up 할 수 있을 가능성이 있다고 논문 저자는 판단합니다.(future works로 남겼습니다)
내용을 요약하면 규모가 작은 모델(그렇다고 하더라도 LLaMA-7B을 의미하는 것입니다..!)이 LFM(Large Foundation Model)에 버금가는 인지 및 추론 능력을 갖추기 위해서는 이전과 다른 전략이 필요하다는 것입니다.
그리고 그 방식으로는 Explanation Tuning을 제시하여 실험을 수행했고, 그 결과는 Vicuna와 같은 모델들에 비하면 다소 준수하다고 볼 수 있습니다.
그럼에도 불구하고 진정으로 추론 능력을 갖추고 있는지에 대해서는 충분히 의문을 품을 만한데, GPT-4에 비하면 아직도 한~참 뒤떨어지는 퍼포먼스를 보여주었기 때문입니다.
(본 논문에서도 결국 아직 한계가 명확하다는 점을 지적하는 것 같습니다)
개인적인 견해로는 Tool Augmented 방식도 사실 LFM을 표면적으로만 모방한 것이라는 생각이 들어서 앞으로 LFM의 출력물로 학습하는 방식이 발전할 가능성은 무궁무진하다고 생각했습니다.
출처 : https://arxiv.org/abs/2306.02707
Orca: Progressive Learning from Complex Explanation Traces of GPT-4
Recent research has focused on enhancing the capability of smaller models through imitation learning, drawing on the outputs generated by large foundation models (LFMs). A number of issues impact the quality of these models, ranging from limited imitation
arxiv.org
'Paper Review' 카테고리의 다른 글
최근에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Microsoft Research]
단순히 Large Foundation Models(LFMs)의 결론을 모방하지 않고, LFM의 추론 과정(reasoning process)을 배워야 성능 향상으로 이어진다.
그러나 아직까지도 LFM의 능력을 제대로 follow-up하지는 못한다(GPT-4의 벽).
ChatGPT가 뜨거운 관심을 받으면서 한편으로는 모델 경량화에 대한 관심도 엄청나게 커졌습니다.
지금도 마찬가지인게 GPT나 BARD 등 사람들에게 잘 알려진 챗봇의 기반이 되는 모델들의 사이즈가 너무 커져서 개인이 운용하기가 너무 힘들어졌기 때문입니다.
그러면서 주목을 받은 것이 모델의 사이즈는 작지만 LLM의 성능에 준하는 LLaMA와 같은 모델들입니다. 특히 여기에 다양한 tuning 기법을 적용하면서 성능을 최대치로 끌어올리는 연구가 인기가 많았습니다.
아주 대표적으로 Standford 대학에서 만든 alpaca나, ChatGPT와 실제 유저간의 대화 데이터를 바탕으로 학습한 Vicuna 등이 이에 속합니다.
이런 모델들도 굉장히 좋은 성능을 보이면서 사람들의 주목을 크게 받았는데요, 본 논문에서는 이런 모델들의 한계를 지적합니다.
바로 추론 및 이해 능력이 부족하다는 것이죠.
표현을 빌리자면 단순히 결과물만을 모방하는 방식으로는 제대로 학습하기 어렵다는 것입니다.
추론 능력이 요구되는 대표적인 태스크가 Math Word Problem Solving입니다.
하지만 일종의 distillation 기법으로 학습된 작은 모델들이 이와 같은 태스크를 유독 잘 처리하지 못한다는 것이 추론 능력을 얻지 못한채로 모방만 하고 있다는 증거가 되는 것이죠.
결국 저자는 <query, response> 데이터 쌍을 증강시키고 이러한 추론 과정을 위주로 모델을 학습시킵니다.
또 그냥 데이터 쌍의 개수를 증가시킨 것 뿐만 아니라 모델에게 제공하는 instruction의 난이도도 높였는데 이것이 유의미한 성능 향상으로 이어졌습니다.
이러한 학습 방식을 Explanation Tuning이라고 부릅니다.
그래서 사실 학습 방법을 보면 일반적인 instruction tuning과 크게 차이가 있지는 않습니다.
다만 GPT-4를 통해 < {system instruction, user instruction, input} , output > 쌍으로 학습한다는 차이점은 존재합니다.
본 논문에서 정리된 실험 결과를 살펴보면 그 결과를 한 문장으로 요약할 수 있습니다.
Orca는 Vicuna보다 확실히 뛰어나고, ChatGPT와는 비등하며, GPT-4에는 한참 뒤떨어진다.
사실 논문에서는 생성 관련 태스크들을 수행하면서 여러 모델들(모태는 다 GPT라고 봐야겠지만요..)을 비교했는데, 딱 위 문장으로 요약할 수 있는 결과들이 이어졌습니다.
하지만 아이러니하게도 LFM이 아니기 때문에 일반적인 지식을 보유하거나 장기기억에 대한 능력이 부족해서 추론 능력이 떨어진다는 결과가 나옵니다.
한편 최근에 ChatGPT의 GPT-4에 plug-in 기능을 추가하여 외부 api를 활용하는 테크닉들이 잘 알려지고 있습니다.
이와 동일한 방식으로 Orca에 일종의 tool을 달아주어 성능을 확인해본 결과 이전에 비하면 LFM을 follow-up 할 수 있을 가능성이 있다고 논문 저자는 판단합니다.(future works로 남겼습니다)
내용을 요약하면 규모가 작은 모델(그렇다고 하더라도 LLaMA-7B을 의미하는 것입니다..!)이 LFM(Large Foundation Model)에 버금가는 인지 및 추론 능력을 갖추기 위해서는 이전과 다른 전략이 필요하다는 것입니다.
그리고 그 방식으로는 Explanation Tuning을 제시하여 실험을 수행했고, 그 결과는 Vicuna와 같은 모델들에 비하면 다소 준수하다고 볼 수 있습니다.
그럼에도 불구하고 진정으로 추론 능력을 갖추고 있는지에 대해서는 충분히 의문을 품을 만한데, GPT-4에 비하면 아직도 한~참 뒤떨어지는 퍼포먼스를 보여주었기 때문입니다.
(본 논문에서도 결국 아직 한계가 명확하다는 점을 지적하는 것 같습니다)
개인적인 견해로는 Tool Augmented 방식도 사실 LFM을 표면적으로만 모방한 것이라는 생각이 들어서 앞으로 LFM의 출력물로 학습하는 방식이 발전할 가능성은 무궁무진하다고 생각했습니다.
출처 : https://arxiv.org/abs/2306.02707
Orca: Progressive Learning from Complex Explanation Traces of GPT-4
Recent research has focused on enhancing the capability of smaller models through imitation learning, drawing on the outputs generated by large foundation models (LFMs). A number of issues impact the quality of these models, ranging from limited imitation
arxiv.org