
최근(2023.06)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Meta]
기존의 parameter-efficient fine-tuning(PEFT) 방식들을 집대성하여 만든 fine-tuning 기법,
Generalized LoRA(GLoRA)
large-scale deep neural network는 지난 몇 년 간 눈부신 발전을 이룩했습니다.
특히 transformer 아키텍쳐를 기반으로 NLP 분야가 엄청나게 빠른 성장을 이룬 것에 영향을 받아, 이 아키텍쳐는 이미지 분야로까지 전파되어 기존의 연구 성과들을 다 엎을 수준의 영향을 주었죠.
이는 인공지능 모델들의 사이즈가 굉장히 커지는, 즉 더 많은 연산량이 요구되는 결과로 이어지게 되었습니다.
그에 따라서 많은 연구자들이 학습에 필요한 자원의 수나 시간을 줄이는 방법들에 대해서도 연구하기 시작했고, 최근 가장 주목을 크게 받고 많이 활용되는 방식 중 하나가 LoRA입니다.
간단히만 말하자면 LoRA는 행렬을 decomposition하여 같은 결과물(사실 차원수만 동일한 것이지만)을 뽑아내는데 필요한 연산량을 크게 줄여주는 기법입니다.
이것 외에도 다양한 방식들이 존재하는데, 본 논문에서는 이러한 여러 기법들을 하나로 합쳐서 일반화 성능이 높은 tuning 방식을 구현했습니다.
이전의 방식들은 아키텍쳐의 한계로 인해 task-specific한 학습을 할 수밖에 없었는데 이를 극복하기 위해서 여러 좋은 방식들을 하나로 합친 것으로 이해할 수 있습니다.
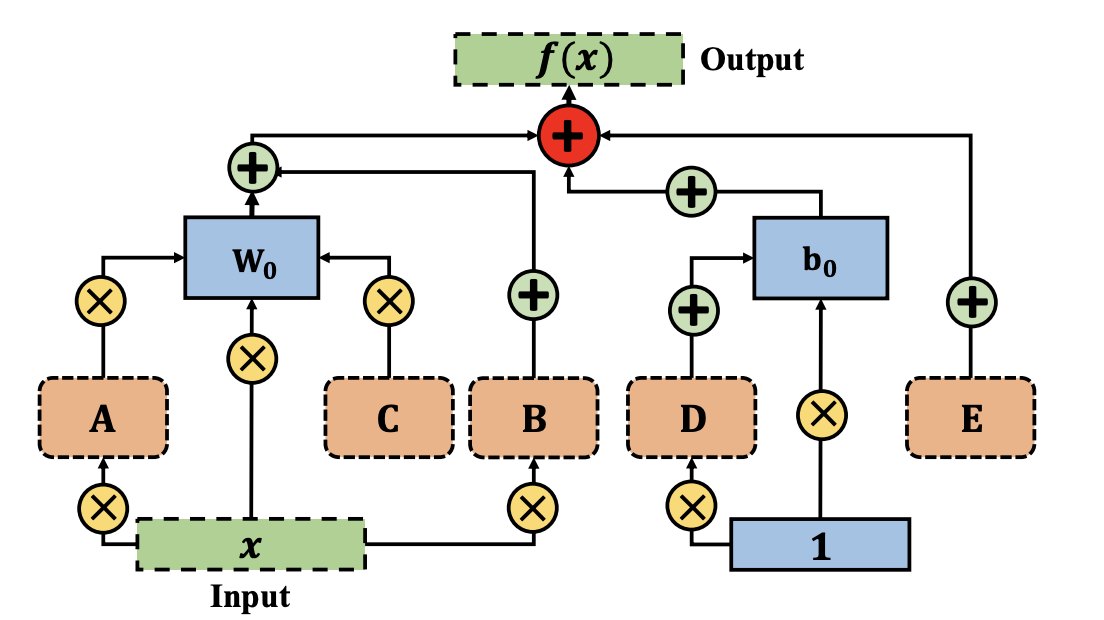
위의 이미지를 보면 연산상 가중치(W) 행렬과 관계를 맺는 A,B,C, 그리고 편향(b) 행렬과 관계를 맺는 D,E가 GLoRA의 구성 요소입니다.
각 알파벳들은 weight를 키우거나, input을 키우거나, weight를 옮기거나 등등의 역할을 수행합니다.
(이전 solution들 중에서 필요한 요소를 가져온 것으로 이해할 수 있습니다. 자세한 정보가 필요하다면 각 방식에 대해 따로 공부할 필요가 있어보입니다.)
GLoRA가 강조하는 가장 큰 특징은,
“학습 시간은 길어졌지만 추론 시간에 추가적으로 요구되는 것은 없다. 또한 학습 시간이 길어진 것도 하이퍼 파리미터 튜닝을 위한 것이기 때문에 문제되지 않는다.”
입니다.
논문의 표현을 빌리자면 Evolutionary Search를 통해 각 레이어에 필요한 configuration을 최적화합니다.
즉 GLoRA 방식에서는 트랜스포머 기반의 각 레이어마다 다른 세팅을 줄 수가 있는데(당연히 학습 파라미터가 다른 값을 갖게 되겠죠), 최적의 세팅을 찾기 위해서 학습 시간이 길어지는 것 뿐이라는 뜻입니다.
정확한 이해는 어렵긴 하지만 이전 연구들의 경우엔 하이퍼 파라미터 튜닝을 직접하는 수밖에는 없다고 하는데, 이를 자동화 및 최적화 할 수 있게 되었다고 하는 것은 엄청난 성과라고 볼 수 있겠습니다.
GLoRA의 성능을 확인하기 위해서 사용된 베이스 모델은 ViT-B이고 VTAB-1K이라는 벤치마크를 대상으로 실험을 수행했다고 합니다.
다른 연구들과 마찬가지로 GLoRA의 사이즈를 large, medium, small로 구분하여 모델을 세팅하고 실험을 했는데,
재밌는 것은 심지어 가장 작은 사이즈의 학습 방식으로도 다른 PEFT 학습 방식들을 압살하는 결과를 보여주었다는 점입니다.
쉽게 말하자면 Large Scale Model을 대상으로 적용되는 기존의 PEFT 대비,
가장 압도적인 성능을 심지어 자신들의 가장 작은 아키텍쳐로도 달성했다는 것이죠.
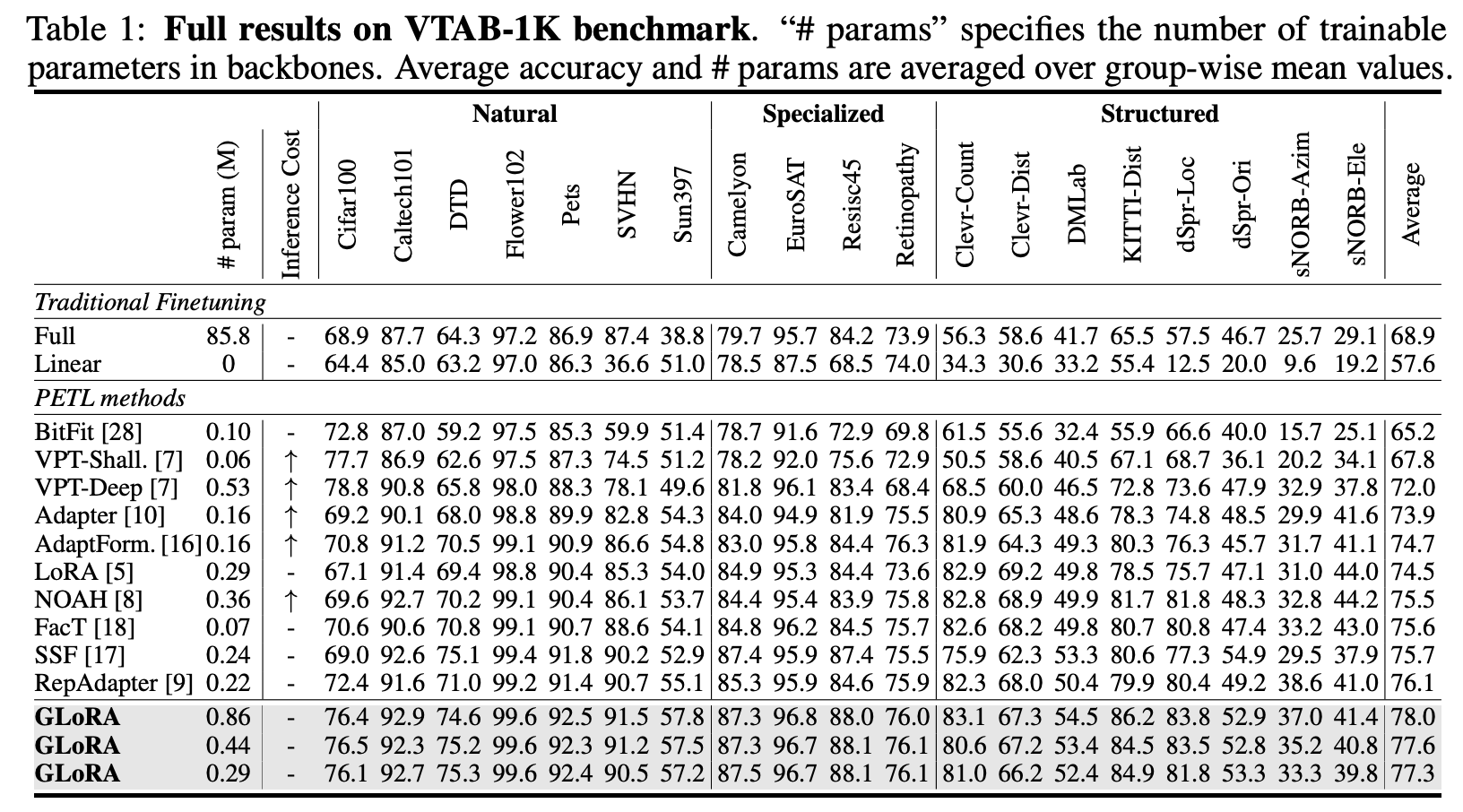
자세히 살펴보면 파라미터 수가 사실은 가장 작은 것이라고 할지라도 다른 방식들에 비하면 보통 수준입니다.
따라서 다른 방식들과 연산량에서 큰 차이는 없더라도 tuning 하기가 굉장히 용이하고 성능이 준수하며, 추론 시간은 굉장히 짧은 기법으로 이해할 수 있습니다.
이뿐만 아니라 Few-shot Learning, Domain Generalization 등에 대해서도 다른 방식들에 비해 우수한 결과를 보여주었습니다.
논문 저자가 이 방식은 이미지, 텍스트 두 도메인에서 각각 강점을 발휘할 수 있을 것이라고 했는데, 이 점이 가장 기대가 됩니다.
특히 1M 이하의 학습 파라미터를 가지는 경우에 single GPU로 학습이 가능하다고 판단을 하던데 좀 더 공부를 해보면 실제로 이런 시도들을 직접 해볼 수 있지 않을까 싶습니다.
출처 : https://arxiv.org/abs//2306.07967
One-for-All: Generalized LoRA for Parameter-Efficient Fine-tuning
We present Generalized LoRA (GLoRA), an advanced approach for universal parameter-efficient fine-tuning tasks. Enhancing Low-Rank Adaptation (LoRA), GLoRA employs a generalized prompt module to optimize pre-trained model weights and adjust intermediate act
arxiv.org
'Paper Review' 카테고리의 다른 글
최근(2023.06)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Meta]
기존의 parameter-efficient fine-tuning(PEFT) 방식들을 집대성하여 만든 fine-tuning 기법,
Generalized LoRA(GLoRA)
large-scale deep neural network는 지난 몇 년 간 눈부신 발전을 이룩했습니다.
특히 transformer 아키텍쳐를 기반으로 NLP 분야가 엄청나게 빠른 성장을 이룬 것에 영향을 받아, 이 아키텍쳐는 이미지 분야로까지 전파되어 기존의 연구 성과들을 다 엎을 수준의 영향을 주었죠.
이는 인공지능 모델들의 사이즈가 굉장히 커지는, 즉 더 많은 연산량이 요구되는 결과로 이어지게 되었습니다.
그에 따라서 많은 연구자들이 학습에 필요한 자원의 수나 시간을 줄이는 방법들에 대해서도 연구하기 시작했고, 최근 가장 주목을 크게 받고 많이 활용되는 방식 중 하나가 LoRA입니다.
간단히만 말하자면 LoRA는 행렬을 decomposition하여 같은 결과물(사실 차원수만 동일한 것이지만)을 뽑아내는데 필요한 연산량을 크게 줄여주는 기법입니다.
이것 외에도 다양한 방식들이 존재하는데, 본 논문에서는 이러한 여러 기법들을 하나로 합쳐서 일반화 성능이 높은 tuning 방식을 구현했습니다.
이전의 방식들은 아키텍쳐의 한계로 인해 task-specific한 학습을 할 수밖에 없었는데 이를 극복하기 위해서 여러 좋은 방식들을 하나로 합친 것으로 이해할 수 있습니다.
위의 이미지를 보면 연산상 가중치(W) 행렬과 관계를 맺는 A,B,C, 그리고 편향(b) 행렬과 관계를 맺는 D,E가 GLoRA의 구성 요소입니다.
각 알파벳들은 weight를 키우거나, input을 키우거나, weight를 옮기거나 등등의 역할을 수행합니다.
(이전 solution들 중에서 필요한 요소를 가져온 것으로 이해할 수 있습니다. 자세한 정보가 필요하다면 각 방식에 대해 따로 공부할 필요가 있어보입니다.)
GLoRA가 강조하는 가장 큰 특징은,
“학습 시간은 길어졌지만 추론 시간에 추가적으로 요구되는 것은 없다. 또한 학습 시간이 길어진 것도 하이퍼 파리미터 튜닝을 위한 것이기 때문에 문제되지 않는다.”
입니다.
논문의 표현을 빌리자면 Evolutionary Search를 통해 각 레이어에 필요한 configuration을 최적화합니다.
즉 GLoRA 방식에서는 트랜스포머 기반의 각 레이어마다 다른 세팅을 줄 수가 있는데(당연히 학습 파라미터가 다른 값을 갖게 되겠죠), 최적의 세팅을 찾기 위해서 학습 시간이 길어지는 것 뿐이라는 뜻입니다.
정확한 이해는 어렵긴 하지만 이전 연구들의 경우엔 하이퍼 파라미터 튜닝을 직접하는 수밖에는 없다고 하는데, 이를 자동화 및 최적화 할 수 있게 되었다고 하는 것은 엄청난 성과라고 볼 수 있겠습니다.
GLoRA의 성능을 확인하기 위해서 사용된 베이스 모델은 ViT-B이고 VTAB-1K이라는 벤치마크를 대상으로 실험을 수행했다고 합니다.
다른 연구들과 마찬가지로 GLoRA의 사이즈를 large, medium, small로 구분하여 모델을 세팅하고 실험을 했는데,
재밌는 것은 심지어 가장 작은 사이즈의 학습 방식으로도 다른 PEFT 학습 방식들을 압살하는 결과를 보여주었다는 점입니다.
쉽게 말하자면 Large Scale Model을 대상으로 적용되는 기존의 PEFT 대비,
가장 압도적인 성능을 심지어 자신들의 가장 작은 아키텍쳐로도 달성했다는 것이죠.
자세히 살펴보면 파라미터 수가 사실은 가장 작은 것이라고 할지라도 다른 방식들에 비하면 보통 수준입니다.
따라서 다른 방식들과 연산량에서 큰 차이는 없더라도 tuning 하기가 굉장히 용이하고 성능이 준수하며, 추론 시간은 굉장히 짧은 기법으로 이해할 수 있습니다.
이뿐만 아니라 Few-shot Learning, Domain Generalization 등에 대해서도 다른 방식들에 비해 우수한 결과를 보여주었습니다.
논문 저자가 이 방식은 이미지, 텍스트 두 도메인에서 각각 강점을 발휘할 수 있을 것이라고 했는데, 이 점이 가장 기대가 됩니다.
특히 1M 이하의 학습 파라미터를 가지는 경우에 single GPU로 학습이 가능하다고 판단을 하던데 좀 더 공부를 해보면 실제로 이런 시도들을 직접 해볼 수 있지 않을까 싶습니다.
출처 : https://arxiv.org/abs//2306.07967
One-for-All: Generalized LoRA for Parameter-Efficient Fine-tuning
We present Generalized LoRA (GLoRA), an advanced approach for universal parameter-efficient fine-tuning tasks. Enhancing Low-Rank Adaptation (LoRA), GLoRA employs a generalized prompt module to optimize pre-trained model weights and adjust intermediate act
arxiv.org