
최근(2023.06)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Meta AI]
LLM이 상관 관계로부터 인과 추론을 할 수 있을까?에 대한 답변은 No.
관계를 나타내는 그래프 이론을 통해 LLM이 지닌 추론 능력의 한계를 드러낸 논문.
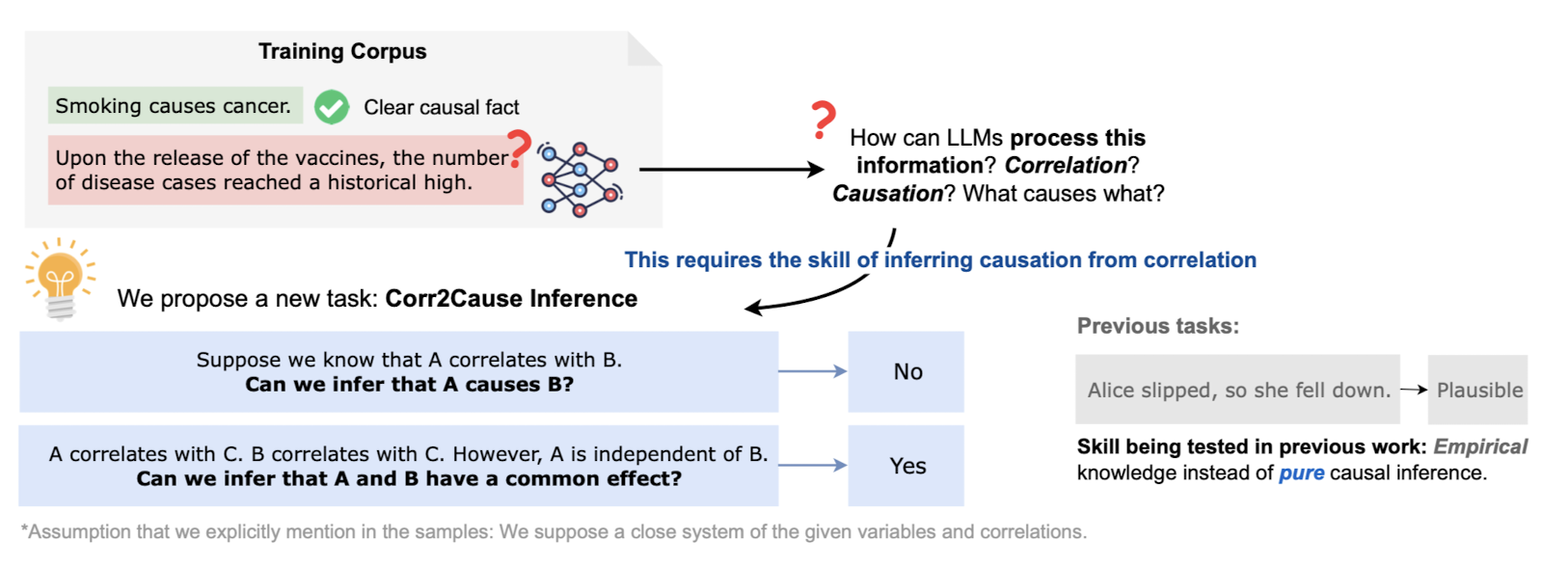
causality, 인과성을 지녔는지를 확인하는 방법은 크게 두 가지로 나뉩니다.
경험적 지식을 바탕으로 추론하고 있는가를 확인, 혹은 순수한 인과 추론 능력 확인입니다.
지금까지의 연구들은 전자에 집중되어 있습니다.
다르게 말하자면 여러 LLM들이 실제로 추론 능력을 갖추고 있는지에 대해서는 큰 관심이 없고, 대신 학습한 확률 분포를 기반으로 다음에 올 토큰을 예측하는 것 뿐이었죠.
논문 저자는 LLM이 실제로 추론 능력을 갖추고 있는지를 판단하기 위한 기존의 방식들, 즉 벤치마크가 잘못 형성되었다고 주장하며 새로운 벤치마크를 구성합니다.
이것이 40만개의 샘플로 구성된 데이터셋으로 LLM의 추론 능력을 판단할 수 있는 CORR2CAUSE입니다.
이를 구성할 때 사용된 개념을 이해하는 것은 쉽지 않아 보입니다.
관계를 나타내는 그래프 이론을 사용했기 때문인데요, 예를 들어 i, j, k의 관계에 따라 parent, child, confounder 등 다양한 개념이 적용되었습니다.
저자가 보고 싶어한 것은 LLM이 이런 객체 간의 관계를 토대로 인과성을 추론할 수 있는지입니다.
이를테면 i가 j의 부모, j가 i의 자식인 관계일 때 i가 j의 발생 원인이 된다는 것을 LLM이 논리적으로 학습한지 확인하는 것이지요.
사실 겉으로 보기에는 LLM이 그러한 능력을 지닌 것 같지만, 본 논문의 실험에 따르면 그렇지 않습니다.
단순히 i, j의 순서를 바꾸는 것만으로도 예측 정확도가 확연히 낮아졌기 때문입니다(파괴적인 성능 하락..!)
즉 LLM이 어떤 논리적, 인과적인 관계에 대해서 학습을 제대로 했다기 보다는, 단순히 확률에 기반해서 다음 토큰을 예측하고 있다는 것이고, 이는 사실상 사람들이 우려하는 것처럼 AGI가 도래했나..? 하는 걱정을 누그러뜨려줄 수 있는 근거가 되기도 합니다.
결국 앞으로의 LLM이 넘어야 할 것은 단순히 이전에 학습한 데이터들을 토대로 다음에 올 확률이 가장 높은 토큰 단위를 예측하는 것이 아닌라 진정한 추론 능력을 갖추는 것이고,
이를 본 논문에서 제시하는 벤치마크와 같은 수단들을 통해 입증할 수 있을 것입니다.
하지만 저자가 스스로 밝힌 바와 같이 어떤 객체 간의 관계를 규명하는 것도 사람이 직접 임의로 하는 것 뿐이기도 하고,
그렇기 때문에 미처 캐치하지 못한 숨겨진 객체 간의 관계도 존재할 수 있다는 한계점이 존재합니다.
한편으로는 그러한 한계도 많은 데이터가 주어지고 LLM이 이 데이터 간의 피쳐를 잘 추출하게 된다면 극복하게 될 수 있는 문제라는 생각도 들지만,
이미 엄청난 데이터들을 통해 학습한 LLM의 한계를 지적한 것이 본 논문이니 참 아이러니하다는 생각이 들기도 합니다.
출처 : https://arxiv.org/abs//2306.05836
Can Large Language Models Infer Causation from Correlation?
Causal inference is one of the hallmarks of human intelligence. While the field of CausalNLP has attracted much interest in the recent years, existing causal inference datasets in NLP primarily rely on discovering causality from empirical knowledge (e.g.,
arxiv.org
'Paper Review' 카테고리의 다른 글
최근(2023.06)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Meta AI]
LLM이 상관 관계로부터 인과 추론을 할 수 있을까?에 대한 답변은 No.
관계를 나타내는 그래프 이론을 통해 LLM이 지닌 추론 능력의 한계를 드러낸 논문.
causality, 인과성을 지녔는지를 확인하는 방법은 크게 두 가지로 나뉩니다.
경험적 지식을 바탕으로 추론하고 있는가를 확인, 혹은 순수한 인과 추론 능력 확인입니다.
지금까지의 연구들은 전자에 집중되어 있습니다.
다르게 말하자면 여러 LLM들이 실제로 추론 능력을 갖추고 있는지에 대해서는 큰 관심이 없고, 대신 학습한 확률 분포를 기반으로 다음에 올 토큰을 예측하는 것 뿐이었죠.
논문 저자는 LLM이 실제로 추론 능력을 갖추고 있는지를 판단하기 위한 기존의 방식들, 즉 벤치마크가 잘못 형성되었다고 주장하며 새로운 벤치마크를 구성합니다.
이것이 40만개의 샘플로 구성된 데이터셋으로 LLM의 추론 능력을 판단할 수 있는 CORR2CAUSE입니다.
이를 구성할 때 사용된 개념을 이해하는 것은 쉽지 않아 보입니다.
관계를 나타내는 그래프 이론을 사용했기 때문인데요, 예를 들어 i, j, k의 관계에 따라 parent, child, confounder 등 다양한 개념이 적용되었습니다.
저자가 보고 싶어한 것은 LLM이 이런 객체 간의 관계를 토대로 인과성을 추론할 수 있는지입니다.
이를테면 i가 j의 부모, j가 i의 자식인 관계일 때 i가 j의 발생 원인이 된다는 것을 LLM이 논리적으로 학습한지 확인하는 것이지요.
사실 겉으로 보기에는 LLM이 그러한 능력을 지닌 것 같지만, 본 논문의 실험에 따르면 그렇지 않습니다.
단순히 i, j의 순서를 바꾸는 것만으로도 예측 정확도가 확연히 낮아졌기 때문입니다(파괴적인 성능 하락..!)
즉 LLM이 어떤 논리적, 인과적인 관계에 대해서 학습을 제대로 했다기 보다는, 단순히 확률에 기반해서 다음 토큰을 예측하고 있다는 것이고, 이는 사실상 사람들이 우려하는 것처럼 AGI가 도래했나..? 하는 걱정을 누그러뜨려줄 수 있는 근거가 되기도 합니다.
결국 앞으로의 LLM이 넘어야 할 것은 단순히 이전에 학습한 데이터들을 토대로 다음에 올 확률이 가장 높은 토큰 단위를 예측하는 것이 아닌라 진정한 추론 능력을 갖추는 것이고,
이를 본 논문에서 제시하는 벤치마크와 같은 수단들을 통해 입증할 수 있을 것입니다.
하지만 저자가 스스로 밝힌 바와 같이 어떤 객체 간의 관계를 규명하는 것도 사람이 직접 임의로 하는 것 뿐이기도 하고,
그렇기 때문에 미처 캐치하지 못한 숨겨진 객체 간의 관계도 존재할 수 있다는 한계점이 존재합니다.
한편으로는 그러한 한계도 많은 데이터가 주어지고 LLM이 이 데이터 간의 피쳐를 잘 추출하게 된다면 극복하게 될 수 있는 문제라는 생각도 들지만,
이미 엄청난 데이터들을 통해 학습한 LLM의 한계를 지적한 것이 본 논문이니 참 아이러니하다는 생각이 들기도 합니다.
출처 : https://arxiv.org/abs//2306.05836
Can Large Language Models Infer Causation from Correlation?
Causal inference is one of the hallmarks of human intelligence. While the field of CausalNLP has attracted much interest in the recent years, existing causal inference datasets in NLP primarily rely on discovering causality from empirical knowledge (e.g.,
arxiv.org