
최근(2023.06)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Microsoft Research]
reverse KLD를 이용하여 사이즈가 큰 생성 모델로부터 distill을 적용한 MINILLM.
우수한 성능과 함께, 더 큰 사이즈의 모델에도 적용할 수 있다는 특징, 즉 scability가 특징이다.
- 배경
LLM이 크게 주목을 받으면서 이를 운용하기 위해 필요한 자원상의 한계가 항상 지적되었습니다.
덕분에 적은 자원을 사용하면서도 준수한 성능을 유지할 수 있도록 하는 기법들이 많이 연구되었습니다.
그중에서도 Knowledge Distillation(KD) 방식도 아주 활발히 사용되는데, 큰 모델이 사전학습을 통해 가진 확률 분포를 작은 모델이 일종의 증류(distillation) 방식으로 취하게 되는 것입니다.
본 논문에서는 큰 모델의 지식을 효과적으로 습득할 수 있는 방법론인 MINILLM을 제시합니다.
- 특징
KD의 주된 목표(objectives)는 forward Kullback-Leibler divergence(KLD, 쿨백-라이블러 발산)를 최소화하는 것입니다.
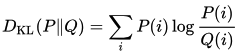
여기서 P는 large model(teacher)의 확률 분포를, Q는 small model(student)의 확률 분포를 의미합니다.
reverse KLD는 P와 Q의 위치를 바꾼식을 의미하고, 이것이 기존과 다른 결과를 가져다 줄 수 있다는 것은 애초에 KLD가 거리 함수가 아니라는 점을 시사합니다.
어쨌든 둘의 위치를 바꾸는 이유는 간단히 표현하면 large model이 가진 확률 분포에 과적합되는 것을 방지하기 위함입니다.
논문에서 과적합이라는 표현을 직접적으로 사용하고 있지는 않지만 개념적으로는 상당히 유사합니다.
사이즈가 작은 모델의 경우 capacity가 제한적이라는 점이 지적됩니다.
따라서 큰 모델의 확률 분포를 단순 모방하게 되는 경우 확률 분포 그래프상 tail에 해당 하는 문제들(일종의 edge case)을 거의 전혀 처리할 수 없게 됩니다.
다르게 말하자면 학습 데이터와 추론 데이터 사이의 괴리(distribution shift)에 대해 유연하게 대처할 능력이 전혀 없다는 것이죠.
따라서 기존의 forward KLD를 최소화하는 방식으로는 이러한 한계를 극복하기 어렵기 때문에 reverse KLD를 도입했다고 이해할 수 있습니다.
또한 이 포스팅에서 자세히 다루지는 않겠지만, Single-Step Regularization과 Teacher-Mixed Sampling, Length Normalization 등이 MINILLM을 구현하는데 사용된 두드러진 특징입니다.
- 실험 및 결과
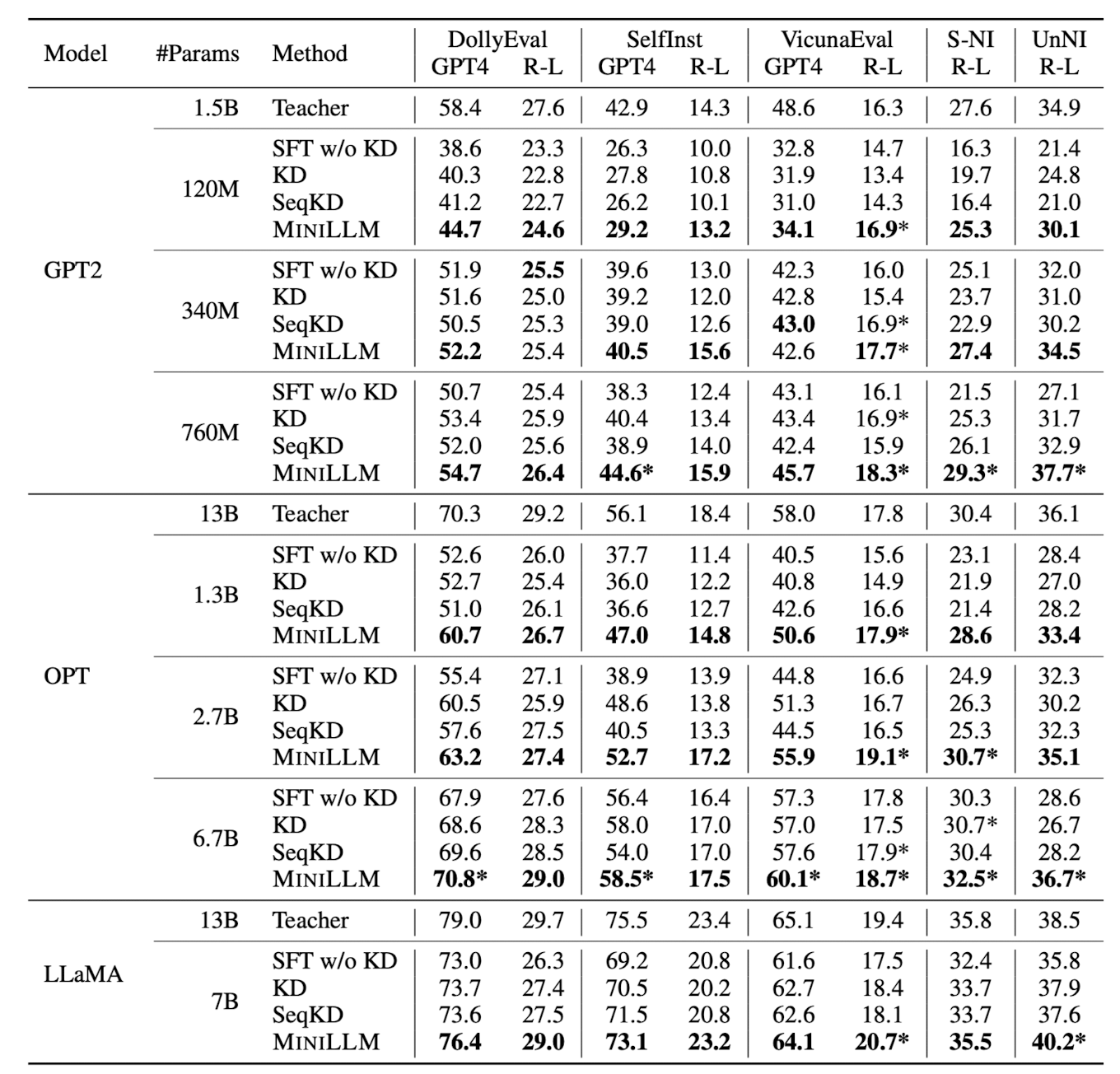
모델의 성능을 검증하기 위해 사용된 데이터셋들은 ‘instruction-following’ 방식의 다섯 개 벤치마크이고,
여기에 사용된 metric은 R-L(Rogue-L)과 GPT-4입니다.
GPT-4를 평가자(?)로 사용하는 방식이 여기에도 적용되었습니다.
개인적으로는 capacity가 작은 모델이 생성하는 문장이 길어질수록 오류를 포함할 확률이 증가하지 않고 현상 유지된다는 실험 결과가 눈에 띄었습니다.
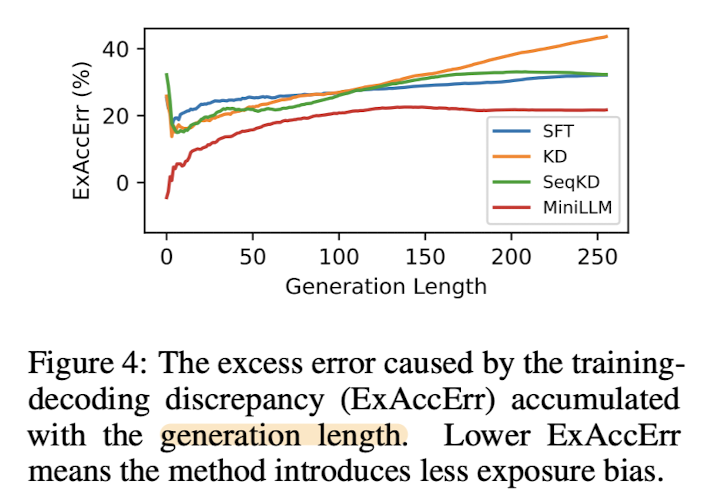
또한 주목할만한 특징 중 하나는 Scability입니다.
연구 단계에서도 그렇고 실질적으로 성능을 끌어올리는 데 있어서 가장 중요한 것 중 하나는 확장 가능성입니다.
이러한 기법이 굉장히 작은 사이즈의 모델에 대해서만 의미가 있거나 반대에 해당하는 경우가 많은데(LLM의 emergent ability를 극복하기 위한 노력 중 하나가 distillation이기도 하죠), 모델의 사이즈를 키워도 긍정적인 연구 결과가 이어졌다는 점이 인상깊습니다.
- 개인적 감상
수식에 대해 공부할 것이 너무 많이 남아있다는 생각이 드는 논문이었습니다 😂
확실히 어떤 기법들을 떠올리거나 새로 적용할 때, 이런 수학적 개념이 탄탄히 뒷받침되어 있어야 하는데 아직까지 그런 부분이 참 어려운 것 같습니다.
어쨌든 이 논문처럼 기존의 방식을 반전하여 좋은 성과를 보이는 것들은 특히나 기억에 잘 남는 것 같습니다.
(Microsoft Research라 그런 것이 아니라.! ㅎㅎ;)
약간 의문인 것은 distillation 기법을 적용할 수 있는 ‘작은’ 모델의 대체 기준이 뭘까 하는 점입니다.
본 논문에서는 GPT-2의 작은 사이즈부터 시작하긴 했는데, 뭐 이를테면 NLI에 특화된 BERT 기반의 모델들에 대해서는 이런 소식이 별로 없나 싶기도 하고요.
또 같은 GPT 패밀리 중에서도 GPT-3가 최근에는 비교 대상으로 항상 저격 당하는데 도대체 large, small은 뭘 기준으로 말하는 걸까, 싶은 생각이 최근에는 가장 많이 드는 것 같습니다.
출처 : https://arxiv.org/abs//2306.08543
Knowledge Distillation of Large Language Models
Knowledge Distillation (KD) is a promising technique for reducing the high computational demand of large language models (LLMs). However, previous KD methods are primarily applied to white-box classification models or training small models to imitate black
arxiv.org
'Paper Review' 카테고리의 다른 글
최근(2023.06)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Microsoft Research]
reverse KLD를 이용하여 사이즈가 큰 생성 모델로부터 distill을 적용한 MINILLM.
우수한 성능과 함께, 더 큰 사이즈의 모델에도 적용할 수 있다는 특징, 즉 scability가 특징이다.
- 배경
LLM이 크게 주목을 받으면서 이를 운용하기 위해 필요한 자원상의 한계가 항상 지적되었습니다.
덕분에 적은 자원을 사용하면서도 준수한 성능을 유지할 수 있도록 하는 기법들이 많이 연구되었습니다.
그중에서도 Knowledge Distillation(KD) 방식도 아주 활발히 사용되는데, 큰 모델이 사전학습을 통해 가진 확률 분포를 작은 모델이 일종의 증류(distillation) 방식으로 취하게 되는 것입니다.
본 논문에서는 큰 모델의 지식을 효과적으로 습득할 수 있는 방법론인 MINILLM을 제시합니다.
- 특징
KD의 주된 목표(objectives)는 forward Kullback-Leibler divergence(KLD, 쿨백-라이블러 발산)를 최소화하는 것입니다.
여기서 P는 large model(teacher)의 확률 분포를, Q는 small model(student)의 확률 분포를 의미합니다.
reverse KLD는 P와 Q의 위치를 바꾼식을 의미하고, 이것이 기존과 다른 결과를 가져다 줄 수 있다는 것은 애초에 KLD가 거리 함수가 아니라는 점을 시사합니다.
어쨌든 둘의 위치를 바꾸는 이유는 간단히 표현하면 large model이 가진 확률 분포에 과적합되는 것을 방지하기 위함입니다.
논문에서 과적합이라는 표현을 직접적으로 사용하고 있지는 않지만 개념적으로는 상당히 유사합니다.
사이즈가 작은 모델의 경우 capacity가 제한적이라는 점이 지적됩니다.
따라서 큰 모델의 확률 분포를 단순 모방하게 되는 경우 확률 분포 그래프상 tail에 해당 하는 문제들(일종의 edge case)을 거의 전혀 처리할 수 없게 됩니다.
다르게 말하자면 학습 데이터와 추론 데이터 사이의 괴리(distribution shift)에 대해 유연하게 대처할 능력이 전혀 없다는 것이죠.
따라서 기존의 forward KLD를 최소화하는 방식으로는 이러한 한계를 극복하기 어렵기 때문에 reverse KLD를 도입했다고 이해할 수 있습니다.
또한 이 포스팅에서 자세히 다루지는 않겠지만, Single-Step Regularization과 Teacher-Mixed Sampling, Length Normalization 등이 MINILLM을 구현하는데 사용된 두드러진 특징입니다.
- 실험 및 결과
모델의 성능을 검증하기 위해 사용된 데이터셋들은 ‘instruction-following’ 방식의 다섯 개 벤치마크이고,
여기에 사용된 metric은 R-L(Rogue-L)과 GPT-4입니다.
GPT-4를 평가자(?)로 사용하는 방식이 여기에도 적용되었습니다.
개인적으로는 capacity가 작은 모델이 생성하는 문장이 길어질수록 오류를 포함할 확률이 증가하지 않고 현상 유지된다는 실험 결과가 눈에 띄었습니다.
또한 주목할만한 특징 중 하나는 Scability입니다.
연구 단계에서도 그렇고 실질적으로 성능을 끌어올리는 데 있어서 가장 중요한 것 중 하나는 확장 가능성입니다.
이러한 기법이 굉장히 작은 사이즈의 모델에 대해서만 의미가 있거나 반대에 해당하는 경우가 많은데(LLM의 emergent ability를 극복하기 위한 노력 중 하나가 distillation이기도 하죠), 모델의 사이즈를 키워도 긍정적인 연구 결과가 이어졌다는 점이 인상깊습니다.
- 개인적 감상
수식에 대해 공부할 것이 너무 많이 남아있다는 생각이 드는 논문이었습니다 😂
확실히 어떤 기법들을 떠올리거나 새로 적용할 때, 이런 수학적 개념이 탄탄히 뒷받침되어 있어야 하는데 아직까지 그런 부분이 참 어려운 것 같습니다.
어쨌든 이 논문처럼 기존의 방식을 반전하여 좋은 성과를 보이는 것들은 특히나 기억에 잘 남는 것 같습니다.
(Microsoft Research라 그런 것이 아니라.! ㅎㅎ;)
약간 의문인 것은 distillation 기법을 적용할 수 있는 ‘작은’ 모델의 대체 기준이 뭘까 하는 점입니다.
본 논문에서는 GPT-2의 작은 사이즈부터 시작하긴 했는데, 뭐 이를테면 NLI에 특화된 BERT 기반의 모델들에 대해서는 이런 소식이 별로 없나 싶기도 하고요.
또 같은 GPT 패밀리 중에서도 GPT-3가 최근에는 비교 대상으로 항상 저격 당하는데 도대체 large, small은 뭘 기준으로 말하는 걸까, 싶은 생각이 최근에는 가장 많이 드는 것 같습니다.
출처 : https://arxiv.org/abs//2306.08543
Knowledge Distillation of Large Language Models
Knowledge Distillation (KD) is a promising technique for reducing the high computational demand of large language models (LLMs). However, previous KD methods are primarily applied to white-box classification models or training small models to imitate black
arxiv.org