
최근(2023.06)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Qualcomm AI Research] 자연어를 바탕으로 갖춘 연역적 추론의 포맷, Natural Program을 제작. step-by-step, CoT 방식에 있어서 더 철저한 reasoning step을 생성할 수 있게 되었음.
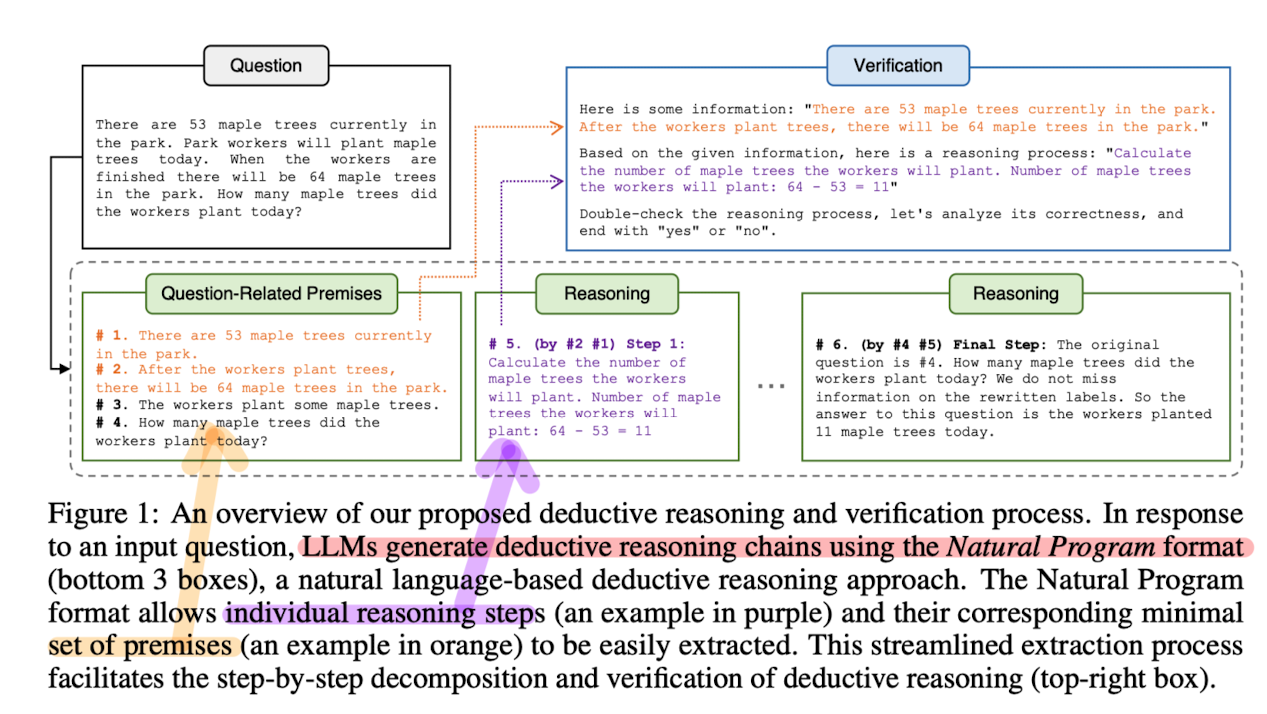
- 배경
Chain of Thought(CoT) 기법은 기존의 LLM들이 진가를 발휘할 수 있도록 돕는 방법으로 LLM계에 큰 파장을 일으켰습니다.
확률 분포를 기반으로 다음 토큰을 예측하기만 했던 LLM의 예측 방식이 정말 사람과 유사한 논리적 구조를 갖출 수 있게끔 도와준 것처럼 보이기도 했죠.
예를 들어 우리가 ChatGPT와 대화할 때 이녀석이 굉장히 논리적이고 체계적인 답변을 막힘없이 쏟아내는 걸 볼 때면 그런 느낌을 더 강하게 받는 것 같습니다.
하지만 인공지능의 아주 유명한 한계점 중 하나가 ‘hallucination’입니다.
겉으로 보기에는 굉장히 답변을 잘 한 것 같지만, 실제로 내용을 확인해보면 엉망진창인 경우가 많습니다.
즉 사실이 아닌 것을 마치 사실처럼 만들어내서 사용자로 하여금 아주 헷갈리게 만드는 것이죠.
특히 답변 내용이 사용자의 전문 분야와 동떨어진 경우 진위여부를 확인할 수 없게 되죠.
이런 문제점을 해결하기 위해 다양한 노력과 시도들이 이뤄지고 있는데, 본 논문도 그중 하나로 이해할 수 있을 것 같습니다.
- 컨셉 및 실험 결과
“최종 답변만이 아닌, 모든 reasoning step이 옳고 그른지를 검사하겠다”
우선 주어진 질문과 context를 바탕으로 전제(premise)를 생성합니다.
그리고 추론 chain을 생성하도록 지시합니다.
이때 추론은 한꺼번에 이뤄지지 않고 개별 step 단위로 이뤄집니다.
전제를 기반으로 추론이 제대로 이뤄졌는지를 개별 step 단위로 확인 및 검증합니다.
이 과정을 여러 개 반복하여 만든 reasoning chain 후보들 중에서 가장 타당한 것 하나를 고릅니다.
이런 투표 방식은 Unanimity-Plurality Voting이라고 부릅니다.
결과는 뭐 당연히 좋은 실험 결과를 담아뒀을 것이기 때문에 흥미로운 점 하나만 짚고자 합니다.
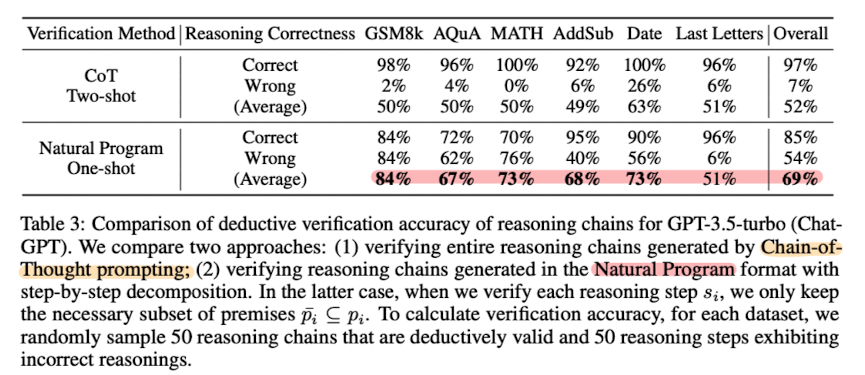
위 표는 연역적 추론의 대표적인 예시, 수학 문제 풀이 벤치마크 대상의 실험 결과입니다.
여러 벤치마크에서 평균적으로 우수한 성능을 보였다는 것이 강조되어 있는데요, Last Letters의 경우는 예외입니다.
이는 학습 과정에서 마지막 결과만 옳은 것은 제외하고, 모든 추론 과정이 일치하는 CoT만 학습시켰기 때문으로 추측됩니다.
즉, 모로가도 서울로만 가면 된다는 식으로 억지 학습한 경우는 이 케이스에 대해 좋은 성적을 거둘 수는 있지만, 실제로 추론 능력을 제대로 갖추기는 불가능하다는 것이죠.
반대로 모든 과정이 정확하게 학습된 경우, 아직까지 모든 경우에 대해서 우수할 수는 없지만, 적어도 정확한 추론 능력을 요하는 것들에 대해서는 뛰어난 퍼포먼스를 보여줄 수 있다는 것을 의미합니다.
- 개인적 감상
의도한 것은 아닌데 어떻게 또 읽다보니 수학 문제를 벤치마크로 삼고 있는 논문을 보게 되었네요.
개인적으로 대화형 인공지능이 일으키는 hallucination 문제를 어떻게 완화, 또는 극복할 수 있을지에 대해 관심이 조금 있었기 때문에 재밌게 읽었습니다.
자세한 내용들을 모두 다루지는 않았지만, 이 논문의 특징이라면 사실 최신 기법들을 잘 버무려 놓았다는 점 같습니다.
이를테면 최종 산출물을 기준으로 학습하는 것이 아니라 중간 과정을 학습해야 한다는 메인 컨셉도 그렇고, 프롬프트 엔지니어링이나 in-context learning 기법을 적극적으로 활용하는 점들이 그렇습니다.
결국 최근의 연구 흐름 중 의미있는 결과들을 만들어내는 것은 세상에 존재하지 않던 새로운 컨셉이 아니라 기존의 연구들을 목표에 맞게끔 잘 조합하는 것일까, 싶은 생각이 들었습니다.
Deductive Verification of Chain-of-Thought Reasoning
Large Language Models (LLMs) significantly benefit from Chain-of-Thought (CoT) prompting in performing various reasoning tasks. While CoT allows models to produce more comprehensive reasoning processes, its emphasis on intermediate reasoning steps can inad
arxiv.org
'Paper Review' 카테고리의 다른 글
최근(2023.06)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Qualcomm AI Research] 자연어를 바탕으로 갖춘 연역적 추론의 포맷, Natural Program을 제작. step-by-step, CoT 방식에 있어서 더 철저한 reasoning step을 생성할 수 있게 되었음.
- 배경
Chain of Thought(CoT) 기법은 기존의 LLM들이 진가를 발휘할 수 있도록 돕는 방법으로 LLM계에 큰 파장을 일으켰습니다.
확률 분포를 기반으로 다음 토큰을 예측하기만 했던 LLM의 예측 방식이 정말 사람과 유사한 논리적 구조를 갖출 수 있게끔 도와준 것처럼 보이기도 했죠.
예를 들어 우리가 ChatGPT와 대화할 때 이녀석이 굉장히 논리적이고 체계적인 답변을 막힘없이 쏟아내는 걸 볼 때면 그런 느낌을 더 강하게 받는 것 같습니다.
하지만 인공지능의 아주 유명한 한계점 중 하나가 ‘hallucination’입니다.
겉으로 보기에는 굉장히 답변을 잘 한 것 같지만, 실제로 내용을 확인해보면 엉망진창인 경우가 많습니다.
즉 사실이 아닌 것을 마치 사실처럼 만들어내서 사용자로 하여금 아주 헷갈리게 만드는 것이죠.
특히 답변 내용이 사용자의 전문 분야와 동떨어진 경우 진위여부를 확인할 수 없게 되죠.
이런 문제점을 해결하기 위해 다양한 노력과 시도들이 이뤄지고 있는데, 본 논문도 그중 하나로 이해할 수 있을 것 같습니다.
- 컨셉 및 실험 결과
“최종 답변만이 아닌, 모든 reasoning step이 옳고 그른지를 검사하겠다”
우선 주어진 질문과 context를 바탕으로 전제(premise)를 생성합니다.
그리고 추론 chain을 생성하도록 지시합니다.
이때 추론은 한꺼번에 이뤄지지 않고 개별 step 단위로 이뤄집니다.
전제를 기반으로 추론이 제대로 이뤄졌는지를 개별 step 단위로 확인 및 검증합니다.
이 과정을 여러 개 반복하여 만든 reasoning chain 후보들 중에서 가장 타당한 것 하나를 고릅니다.
이런 투표 방식은 Unanimity-Plurality Voting이라고 부릅니다.
결과는 뭐 당연히 좋은 실험 결과를 담아뒀을 것이기 때문에 흥미로운 점 하나만 짚고자 합니다.
위 표는 연역적 추론의 대표적인 예시, 수학 문제 풀이 벤치마크 대상의 실험 결과입니다.
여러 벤치마크에서 평균적으로 우수한 성능을 보였다는 것이 강조되어 있는데요, Last Letters의 경우는 예외입니다.
이는 학습 과정에서 마지막 결과만 옳은 것은 제외하고, 모든 추론 과정이 일치하는 CoT만 학습시켰기 때문으로 추측됩니다.
즉, 모로가도 서울로만 가면 된다는 식으로 억지 학습한 경우는 이 케이스에 대해 좋은 성적을 거둘 수는 있지만, 실제로 추론 능력을 제대로 갖추기는 불가능하다는 것이죠.
반대로 모든 과정이 정확하게 학습된 경우, 아직까지 모든 경우에 대해서 우수할 수는 없지만, 적어도 정확한 추론 능력을 요하는 것들에 대해서는 뛰어난 퍼포먼스를 보여줄 수 있다는 것을 의미합니다.
- 개인적 감상
의도한 것은 아닌데 어떻게 또 읽다보니 수학 문제를 벤치마크로 삼고 있는 논문을 보게 되었네요.
개인적으로 대화형 인공지능이 일으키는 hallucination 문제를 어떻게 완화, 또는 극복할 수 있을지에 대해 관심이 조금 있었기 때문에 재밌게 읽었습니다.
자세한 내용들을 모두 다루지는 않았지만, 이 논문의 특징이라면 사실 최신 기법들을 잘 버무려 놓았다는 점 같습니다.
이를테면 최종 산출물을 기준으로 학습하는 것이 아니라 중간 과정을 학습해야 한다는 메인 컨셉도 그렇고, 프롬프트 엔지니어링이나 in-context learning 기법을 적극적으로 활용하는 점들이 그렇습니다.
결국 최근의 연구 흐름 중 의미있는 결과들을 만들어내는 것은 세상에 존재하지 않던 새로운 컨셉이 아니라 기존의 연구들을 목표에 맞게끔 잘 조합하는 것일까, 싶은 생각이 들었습니다.
Deductive Verification of Chain-of-Thought Reasoning
Large Language Models (LLMs) significantly benefit from Chain-of-Thought (CoT) prompting in performing various reasoning tasks. While CoT allows models to produce more comprehensive reasoning processes, its emphasis on intermediate reasoning steps can inad
arxiv.org