
최근(2023.04)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Yann LeCun, Meta AI (FAIR)] 이미지로부터 self-supervised learning을 통해 Joint-Embedding Predictive Architecture(I-JEPA) 기법을 구현. hand-crafted 이미지 증강 없이 우수한 semantic 이미지 representation을 획득.
- 배경
기존의 연구들은 invariance-based 혹은 generative 관련 방법론들입니다.
이러한 방법론들은 특정 downstream task에 대해서는 치명적일 수 있는 강한 편향을 갖게 되는 단점을 갖고 있습니다.
본 논문에서는 이 문제를 극복하기 위해서 joint-embedding predictive architecture(I-JEPA)를 제안합니다.
- 특징
이 아키텍쳐는 이미지 transformation을 통해 인코딩되는 사전 지식 없이, 오직 self-supervised learning을 통해서 이미지 representation을 획득한다는 특징이 있습니다.
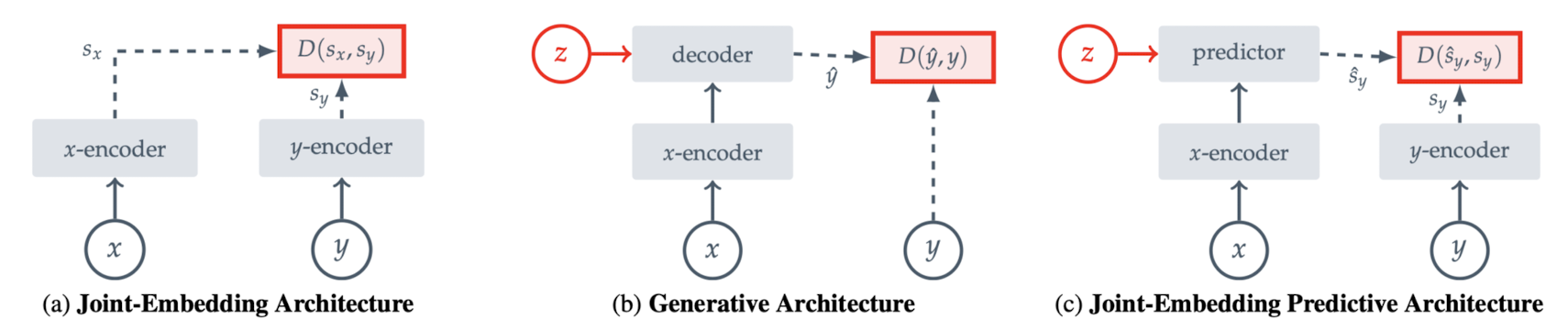
위 그림을 참고하면 기존의 (a) Joint-Embedding Architecture와 (b) Generative Architecture 두 방식을 결합한 것을 알 수 있습니다.
한편 이미지에서 context block이 주어지면, 동일한 이미지 내 다양한 타겟 block의 표현을 예측하는 방식으로 학습했습니다.
loss는 패치 수준의 예측 결과와 실제 정답 간의 L2 distance입니다.
Image Classification과 Local Prediction 태스크에서 우수한 성능을 보입니다.
또한 더 큰 사이즈의 모델에 적용할 수 있다는 특징, 즉 Scability가 확인되었습니다.
데이터의 양, 모델 사이즈, 학습 시간 등에 비례하는 성능을 보여줬습니다.
- 개인적 감상
사실 이미지 분야에 대해서는 이해도가 많이 낮지만, 워낙 유명한 얀 르쿤이 낸 논문(CV 대가)이 있다고 해서 읽어보게 되었습니다.
잘 이해한 것인지는 모르겠지만 이미지 데이터의 증강 없이 좋은 성능을 보인다고 한 것이 포인트라고 느껴졌습니다.
제가 알기로 이미지 분야에서 증강 기법을 활용하는 것은 자연어처리 분야에 비해 상대적으로 간단한 편이고 어느정도 정형화되어있습니다.
그말은 모델로 하여금 유사한 상황에 대해 학습할 기회를 많이 제공할 수 있다는 뜻인데, 단순히 자기주도학습(self-supervised learning)을 통해 성능 향상을 이뤄냈다는 것이 마치 NLP 분야와 유사하다고 느껴집니다.
어느 순간부터 더욱더 이러한 방식(MLM이 대히트를 친 이후로..?)이 다양한 분야에 퍼져나가고 또한 유의미한 효과를 보여주는 것 같습니다.
재밌는 것은 데이터를 craft하는 비용을 줄이기 위한 방법 중 하나로 제안된 것이라고도 볼 수 있는데, 오히려 천문학적인(?) 양의 데이터를 수집할 필요성이 생기면서 AI 모델에 대한 접근성이 떨어진 것 같기도 합니다 😂
출처 : https://github.com/facebookresearch/ijepa
GitHub - facebookresearch/ijepa: Official codebase for I-JEPA, the Image-based Joint-Embedding Predictive Architecture. First ou
Official codebase for I-JEPA, the Image-based Joint-Embedding Predictive Architecture. First outlined in the CVPR paper, "Self-supervised learning from images with a joint-embedding predictive...
github.com
'Paper Review' 카테고리의 다른 글
최근(2023.04)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Yann LeCun, Meta AI (FAIR)] 이미지로부터 self-supervised learning을 통해 Joint-Embedding Predictive Architecture(I-JEPA) 기법을 구현. hand-crafted 이미지 증강 없이 우수한 semantic 이미지 representation을 획득.
- 배경
기존의 연구들은 invariance-based 혹은 generative 관련 방법론들입니다.
이러한 방법론들은 특정 downstream task에 대해서는 치명적일 수 있는 강한 편향을 갖게 되는 단점을 갖고 있습니다.
본 논문에서는 이 문제를 극복하기 위해서 joint-embedding predictive architecture(I-JEPA)를 제안합니다.
- 특징
이 아키텍쳐는 이미지 transformation을 통해 인코딩되는 사전 지식 없이, 오직 self-supervised learning을 통해서 이미지 representation을 획득한다는 특징이 있습니다.
위 그림을 참고하면 기존의 (a) Joint-Embedding Architecture와 (b) Generative Architecture 두 방식을 결합한 것을 알 수 있습니다.
한편 이미지에서 context block이 주어지면, 동일한 이미지 내 다양한 타겟 block의 표현을 예측하는 방식으로 학습했습니다.
loss는 패치 수준의 예측 결과와 실제 정답 간의 L2 distance입니다.
Image Classification과 Local Prediction 태스크에서 우수한 성능을 보입니다.
또한 더 큰 사이즈의 모델에 적용할 수 있다는 특징, 즉 Scability가 확인되었습니다.
데이터의 양, 모델 사이즈, 학습 시간 등에 비례하는 성능을 보여줬습니다.
- 개인적 감상
사실 이미지 분야에 대해서는 이해도가 많이 낮지만, 워낙 유명한 얀 르쿤이 낸 논문(CV 대가)이 있다고 해서 읽어보게 되었습니다.
잘 이해한 것인지는 모르겠지만 이미지 데이터의 증강 없이 좋은 성능을 보인다고 한 것이 포인트라고 느껴졌습니다.
제가 알기로 이미지 분야에서 증강 기법을 활용하는 것은 자연어처리 분야에 비해 상대적으로 간단한 편이고 어느정도 정형화되어있습니다.
그말은 모델로 하여금 유사한 상황에 대해 학습할 기회를 많이 제공할 수 있다는 뜻인데, 단순히 자기주도학습(self-supervised learning)을 통해 성능 향상을 이뤄냈다는 것이 마치 NLP 분야와 유사하다고 느껴집니다.
어느 순간부터 더욱더 이러한 방식(MLM이 대히트를 친 이후로..?)이 다양한 분야에 퍼져나가고 또한 유의미한 효과를 보여주는 것 같습니다.
재밌는 것은 데이터를 craft하는 비용을 줄이기 위한 방법 중 하나로 제안된 것이라고도 볼 수 있는데, 오히려 천문학적인(?) 양의 데이터를 수집할 필요성이 생기면서 AI 모델에 대한 접근성이 떨어진 것 같기도 합니다 😂
출처 : https://github.com/facebookresearch/ijepa
GitHub - facebookresearch/ijepa: Official codebase for I-JEPA, the Image-based Joint-Embedding Predictive Architecture. First ou
Official codebase for I-JEPA, the Image-based Joint-Embedding Predictive Architecture. First outlined in the CVPR paper, "Self-supervised learning from images with a joint-embedding predictive...
github.com