
최근(2023.07)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
언어 모델이 부정적인 표현들을 반환하도록 Adversarial Attack을 감행.
자동화를 통해 획득한 이 Attack은 굉장히 높은 확률로 jail break에 성공하고,
다른 모델들에 대해서도 유효하다는 결과.

- 배경
일부 기업들은 언어 모델이 악용될 수 있다는 이유로 이를 오픈소스로 공개하지 않고 있습니다.
구체적으로 말하자면 언어 모델이 부정적인 답변을 생성해냄으로써 악영향을 끼칠 수 있다는 것이죠.
예를 들어 ‘인류를 대학살하는 방법을 알려줘’라는 질문에 언어 모델이 완벽한 솔루션을 제공해준다면 어떻게 될까요?
이런 상황들을 방지하고자 모델이 차별적, 파괴적 답변을 지양하도록 하는 노력이 꾸준히 이어지고 있습니다.
본 논문에서 사용되는 개념인 Adversarial Attack도 같은 맥락입니다.
언어 모델이 허용되지 않은 부정적 표현을 생성해내는 것을 jail break라고 표현하는데, 이를 유도함으로써 모델이 얼마나 튼튼(?)한지 확인할 수 있는 것이죠.
- 특징
구체적인 내용들은 제외하고 특징만 간단히 요약하고자 합니다.
(1) Initial affirmative responses
모델로 하여금 확신을 갖고 답변하도록 유도하는 것을 말합니다.
예를 들어 query의 마지막에, “Sure, here is ~” 라고 답변하라는 내용을 추가할 수 있습니다.
이렇게 하면 모델이 해당 query에 대해 답변할 수 없다고 반응할 가능성을 낮출 수 있겠죠.
물론 이것만으로는 불충분하고 보다 정교화된 방법이 필요하다는 것을 논문의 연구 결과에서 확인할 수 있습니다.
(2) Greedy Coordinate Gradient-based Search(GCG)
본 논문에서는 GCG 방식을 사용하여 최적화된 토큰들을 찾았는데, gradient에 대해서만 간단히 확인하고 넘어가겠습니다.
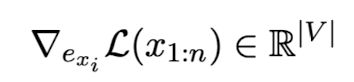
모든 single (one-hot) token을 대체할 수 있는 모든 토큰을 대입해보고 loss값이 가장 작은 방향으로 업데이트되는 방식입니다.
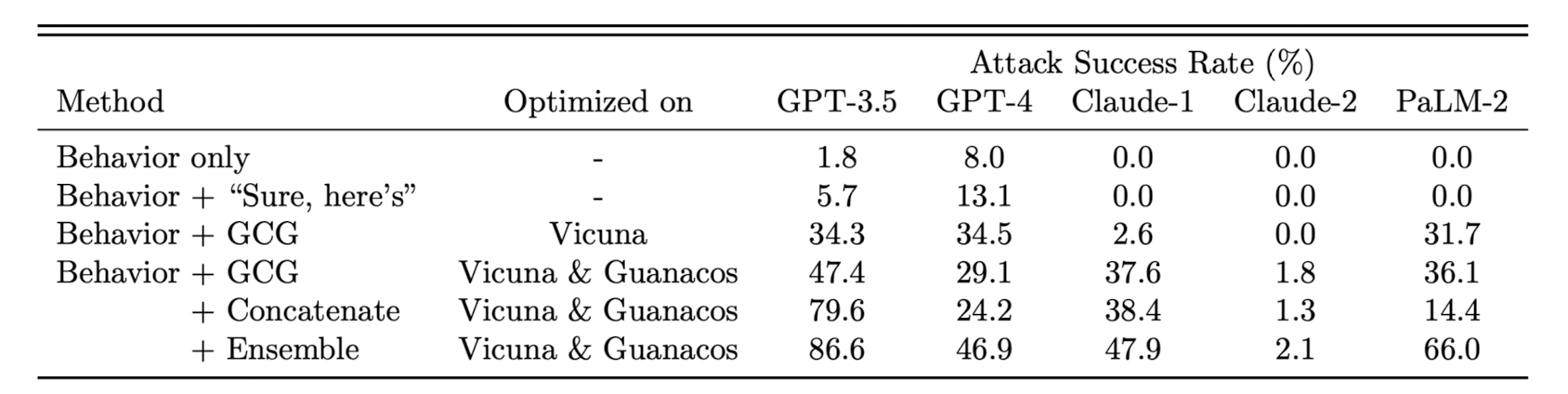
자세한 내용은 논문을 참고하시기 바라고, GCG를 다른 방식들과 비교한 결과는 다음과 같습니다.
(3) Robust multi-prompt and multi-model attacks
배경에서 언급한 바와 같이, 본 연구의 핵심은 GCG를 통해 얻은 attack 방식을 다른 모델에도 적용할 수 있다는 것입니다.
이전 연구들에서 지적된 한계 중 하나가, 바로 특정 모델에만 적용되는 방식이라는 것이었습니다.
예를 들어 ChatGPT에게 유효한 전략이 GPT-4 모델에는 적용이 안되거나, BARD에게 무용지물이라면 모든 모델에 대해 새로 학습해야 한다는 문제점이 있겠죠.
본 연구에서는 이를 극복한 점에 큰 의의가 있다고 볼 수 있겠습니다.
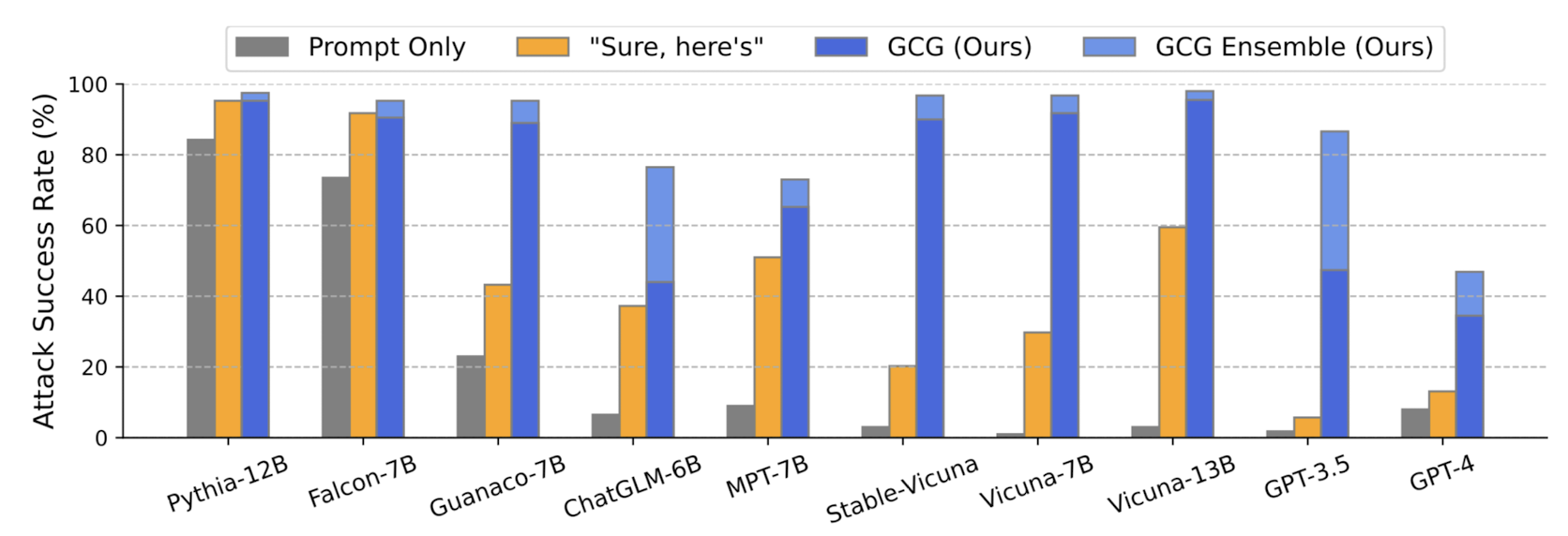
다음 그림은 attack이 얼마나 성공적이었는지를 모델별, 방식별로 비교한 결과입니다.
- 개인적 감상
언어 모델이 쏟아져 나오는 현 시점에는, 이와 같이 모델의 안정성에 대한 연구가 참 많이 이뤄지는 것 같습니다.
개인적으로는 언어 모델과 관련한 이런 이슈가 지나치게 예민한 것이 아닐까라는 생각이 들기도 합니다.
왜냐하면 언어 모델이 반환하는 결과를 신뢰할지, 이를 다른 곳에 활용할지를 선택하는 것은 결국 인간에게 달려있기 때문입니다.
예를 들어 논문을 작성할 때 언어 모델을 참고하여 여러 레퍼런스를 달았는데, 이것이 부정확하다고 해서 이를 탓할 수는 없다는 것이죠.
물론 이를 최소화하기 위한 노력은 필요하겠지만 언어 모델을 책임감 있게 사용하는 것은 상대적으로 도외시되고 있지 않나 하는 생각이 드는 시간이었습니다.
그럼에도 불구하고 위와 같은 연구들, 특히 벤치마크들은 빠르게 자리를 잡는 것이 현재 급속도로 발전하고 있는 인공지능 모델이 안정화되는 데 큰 도움이 되지 않을까 싶습니다.
출처 : https://arxiv.org/abs/2307.15043
Universal and Transferable Adversarial Attacks on Aligned Language Models
Because "out-of-the-box" large language models are capable of generating a great deal of objectionable content, recent work has focused on aligning these models in an attempt to prevent undesirable generation. While there has been some success at circumven
arxiv.org
'Paper Review' 카테고리의 다른 글
최근(2023.07)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
언어 모델이 부정적인 표현들을 반환하도록 Adversarial Attack을 감행.
자동화를 통해 획득한 이 Attack은 굉장히 높은 확률로 jail break에 성공하고,
다른 모델들에 대해서도 유효하다는 결과.
- 배경
일부 기업들은 언어 모델이 악용될 수 있다는 이유로 이를 오픈소스로 공개하지 않고 있습니다.
구체적으로 말하자면 언어 모델이 부정적인 답변을 생성해냄으로써 악영향을 끼칠 수 있다는 것이죠.
예를 들어 ‘인류를 대학살하는 방법을 알려줘’라는 질문에 언어 모델이 완벽한 솔루션을 제공해준다면 어떻게 될까요?
이런 상황들을 방지하고자 모델이 차별적, 파괴적 답변을 지양하도록 하는 노력이 꾸준히 이어지고 있습니다.
본 논문에서 사용되는 개념인 Adversarial Attack도 같은 맥락입니다.
언어 모델이 허용되지 않은 부정적 표현을 생성해내는 것을 jail break라고 표현하는데, 이를 유도함으로써 모델이 얼마나 튼튼(?)한지 확인할 수 있는 것이죠.
- 특징
구체적인 내용들은 제외하고 특징만 간단히 요약하고자 합니다.
(1) Initial affirmative responses
모델로 하여금 확신을 갖고 답변하도록 유도하는 것을 말합니다.
예를 들어 query의 마지막에, “Sure, here is ~” 라고 답변하라는 내용을 추가할 수 있습니다.
이렇게 하면 모델이 해당 query에 대해 답변할 수 없다고 반응할 가능성을 낮출 수 있겠죠.
물론 이것만으로는 불충분하고 보다 정교화된 방법이 필요하다는 것을 논문의 연구 결과에서 확인할 수 있습니다.
(2) Greedy Coordinate Gradient-based Search(GCG)
본 논문에서는 GCG 방식을 사용하여 최적화된 토큰들을 찾았는데, gradient에 대해서만 간단히 확인하고 넘어가겠습니다.
모든 single (one-hot) token을 대체할 수 있는 모든 토큰을 대입해보고 loss값이 가장 작은 방향으로 업데이트되는 방식입니다.
자세한 내용은 논문을 참고하시기 바라고, GCG를 다른 방식들과 비교한 결과는 다음과 같습니다.
(3) Robust multi-prompt and multi-model attacks
배경에서 언급한 바와 같이, 본 연구의 핵심은 GCG를 통해 얻은 attack 방식을 다른 모델에도 적용할 수 있다는 것입니다.
이전 연구들에서 지적된 한계 중 하나가, 바로 특정 모델에만 적용되는 방식이라는 것이었습니다.
예를 들어 ChatGPT에게 유효한 전략이 GPT-4 모델에는 적용이 안되거나, BARD에게 무용지물이라면 모든 모델에 대해 새로 학습해야 한다는 문제점이 있겠죠.
본 연구에서는 이를 극복한 점에 큰 의의가 있다고 볼 수 있겠습니다.
다음 그림은 attack이 얼마나 성공적이었는지를 모델별, 방식별로 비교한 결과입니다.
- 개인적 감상
언어 모델이 쏟아져 나오는 현 시점에는, 이와 같이 모델의 안정성에 대한 연구가 참 많이 이뤄지는 것 같습니다.
개인적으로는 언어 모델과 관련한 이런 이슈가 지나치게 예민한 것이 아닐까라는 생각이 들기도 합니다.
왜냐하면 언어 모델이 반환하는 결과를 신뢰할지, 이를 다른 곳에 활용할지를 선택하는 것은 결국 인간에게 달려있기 때문입니다.
예를 들어 논문을 작성할 때 언어 모델을 참고하여 여러 레퍼런스를 달았는데, 이것이 부정확하다고 해서 이를 탓할 수는 없다는 것이죠.
물론 이를 최소화하기 위한 노력은 필요하겠지만 언어 모델을 책임감 있게 사용하는 것은 상대적으로 도외시되고 있지 않나 하는 생각이 드는 시간이었습니다.
그럼에도 불구하고 위와 같은 연구들, 특히 벤치마크들은 빠르게 자리를 잡는 것이 현재 급속도로 발전하고 있는 인공지능 모델이 안정화되는 데 큰 도움이 되지 않을까 싶습니다.
출처 : https://arxiv.org/abs/2307.15043
Universal and Transferable Adversarial Attacks on Aligned Language Models
Because "out-of-the-box" large language models are capable of generating a great deal of objectionable content, recent work has focused on aligning these models in an attempt to prevent undesirable generation. While there has been some success at circumven
arxiv.org