최근(2023.07)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
multilingual 능력 향상을 목표로 한 1.7B & 13B 사이즈 다국어 모델.
학습 데이터에 영어가 아닌 데이터의 비중을 크게 높이고,
multilingual self-instruct method를 적용한 것이 특징
- 배경
현재까지 많은 LLM들이 주목을 받았음에도 불구하고, 대부분의 모델들은 영어 데이터로 위주로 학습되었기 때문에 영어가 아닌 언어들에 대해서는 아쉬운 성능을 보여주고 있습니다.
보통 데이터셋을 구축할 때 고품질의 데이터를 인터넷으로부터 획득하는 경우가 대부분인데, 다른 언어들은 실사용자가 많다고 하더라도 인터넷에 대한 접근성이 떨어져 이러한 문제점이 생기는 것으로 분석됩니다.
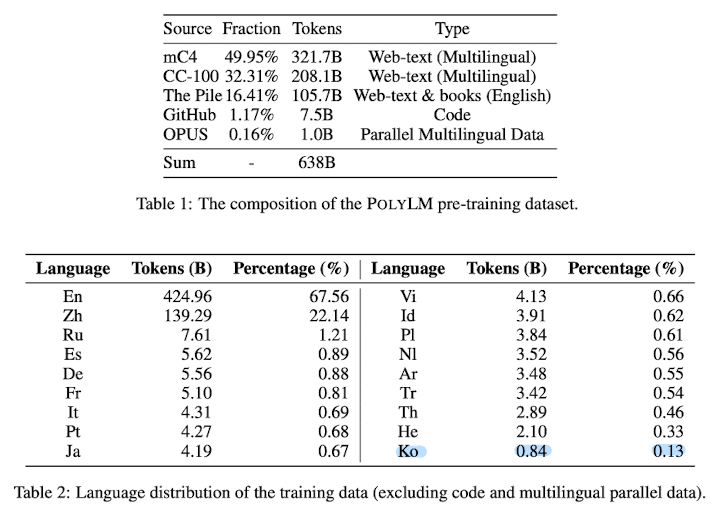
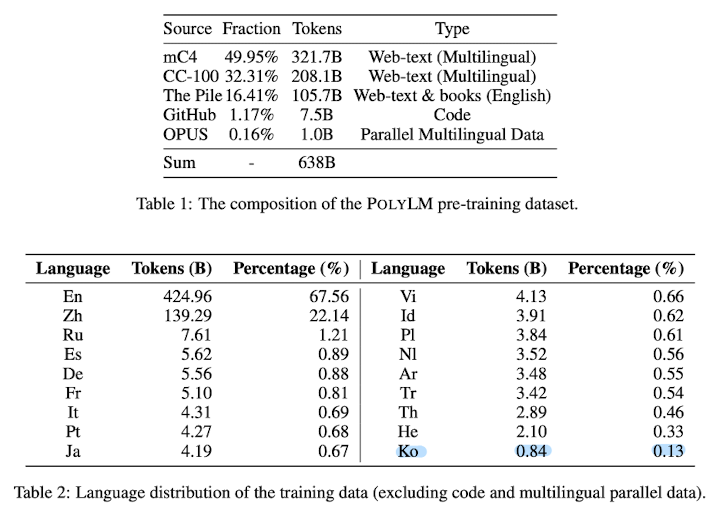
본 논문에서는 이를 극복하기 위해 640B 토큰이나 되는 학습 데이터의 32% 정도를 영어가 아닌 데이터로 구성했습니다.
또한 self-instruct method를 개선하여 multilingual 상황에 특화시킴으로써 모델 성능을 극대화했다고 합니다.
- 특징
1) 데이터셋
위에서 언급했다시피 전체 데이터의 68%는 영어, 나머지 32%는 다른 언어로 구성되어 있습니다.
다른 LLM들이 일반적으로 갖는 학습 데이터의 비율과 비교해본다면 상당히 파격적이라고 볼 수 있습니다.
한국어 데이터도 전체의 0.13%를 차지하고 있는데 이도 다른 모델들에 비하면 상대적으로 많은 양입니다.
데이터를 수집할 때는 다음 기준으로 필터링했다고 합니다.
- Language identification : 무슨 언어의 데이터인지 확신할 수 없다면 필터링
- Rule-based filtering : 동일한 내용이 지나치게 많이 반복되는 경우 필터링
- ML-based quality filtering : n-gram based 언어 모델로 필터링
- Deduplication : 유사한 문서를 필터링
2) Pre-LN
transformer는 여러 layer로 구성되어 있고, 각 layer에 대해 normalization을 적용합니다.
특정 모델들은 layer에 입력을 제공하기 전에 normalization을 적용하는 Pre-LN 기법을 사용하는데, 본 모델도 이를 채택했습니다.
3) Mixed-Precision
bfloat16 자료형으로 학습하여 메모리를 절약하고 학습 효율을 높였습니다.
그러나 float32 자료형으로 학습할 때와 달리 loss spike가 발생한다는 문제점이 있었고, 이를 해결하기 위해 residual connection & attention layers는 float32 자료형을 사용했다고 합니다.
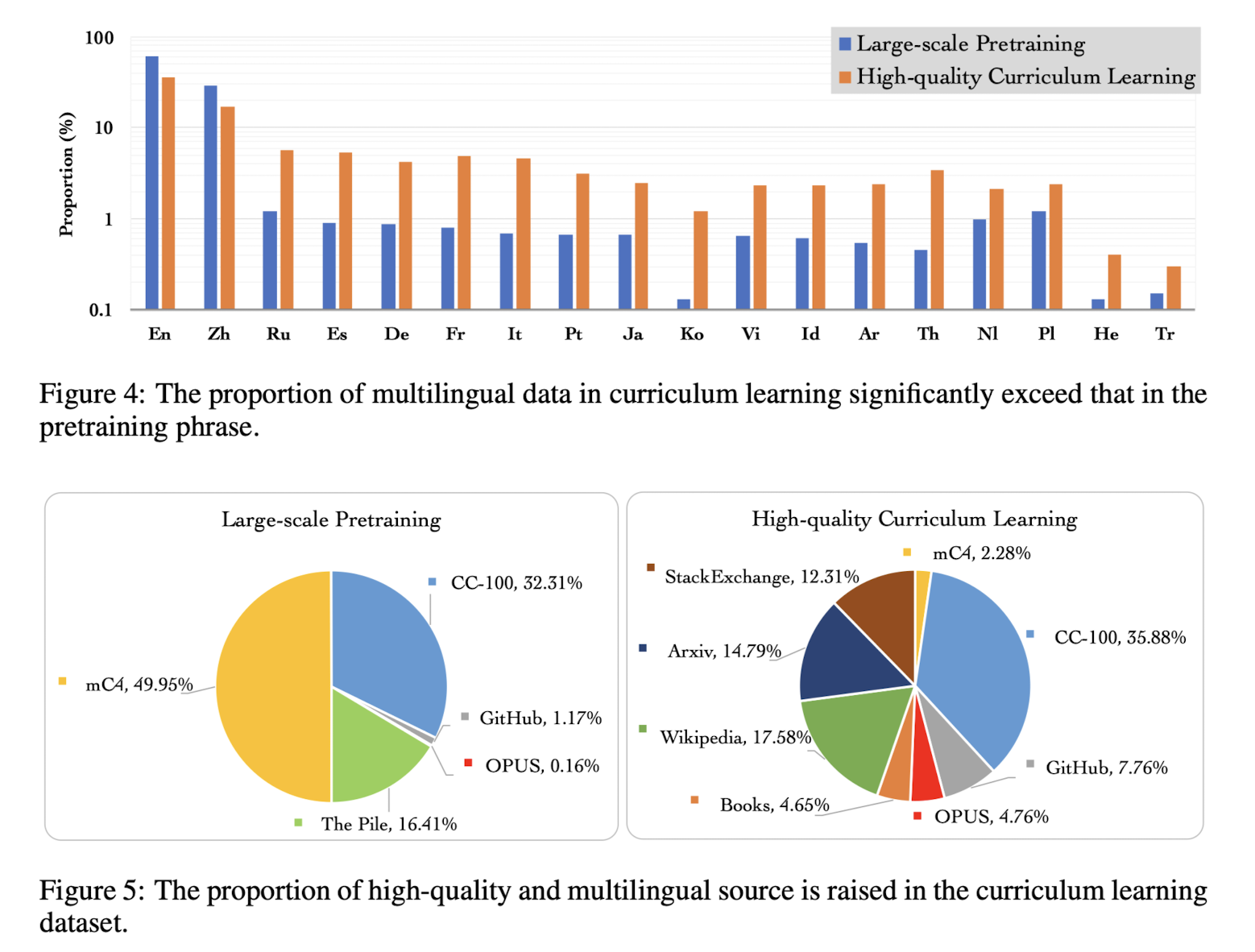
4) Curriculum Learning
모델의 입장에서 난이도가 낮은 것부터 학습하고 점차 난이도를 높이는 학습 방식을 말합니다.
본 연구에서는 영어가 아닌 데이터의 양을 학습이 반복됨에 따라 점차 늘리는 방식을 채택했습니다.
이때 사전학습에는 전체 데이터셋을 활용하여 commonsense generalization ability를 확보하고, 사전학습 데이터의 일부(subset)을 이용하여 multilingual contetn에 대해 강점을 갖도록 했습니다.
모델 성능 평가를 위한 실험 결과는 논문에 자세히 기술되어 있으니 논문에서 직접 확인해보시길 권장드립니다.
- 개인적 감상
ChatGPT로 인해 LLM이 크게 주목받기 시작한 이래로, 이러한 모델들이 과연 한국어도 잘 처리할 수 있을까에 대한 의문이 제기되고 있습니다.
아쉽게도 데이터가 부족하다는 이유로 한국어에 대해서는 모델들이 약한 모습을 보이고 있죠.
그래서 되게 재밌는 것이 언어 모델에게 한국어를 대량으로 학습시키는 것보다는, 영어로 학습되어 좋은 성능을 보이는 모델에게 한국어 데이터를 영어로 번역하는 방식이 많이 활용되고 있습니다.
이것이 단기적으로는 경제적이고 효용성이 높겠지만, 장기적으로는 해외 기술력에 종속되는 결과로 이어지게 될 것이라는 생각이 들어 이와 같은 연구가 의미 있다고 생각합니다.
한편으로는 재밌는 것이 한국어 데이터를 얼마나 학습했는지보다, 학습한 데이터의 총량이 얼마나 되는지나 모델의 학습 방식이 더욱 중요하다는 것입니다.
Eluther AI에서 최근에 대량의 한국어 데이터로 학습한 모델을 공개했는데 생각보다 성능이 별로라는 평이 많습니다.
오히려 한국어 데이터를 훨씬 조금 사용하여 학습한 해외 모델들이 우위를 점하고 있다는 사실이 굉장히 아이러니하죠.
따라서 여러 개의 언어를 동시에 학습하거나 한 언어에 특화된 학습을 하는 것이 강점을 가질 수 있고, 이를 활용하여 소수 언어에 대해서도 강점을 갖는 모델을 개발할 수 있다는 생각이 듭니다.
출처 : https://arxiv.org/abs/2307.06018
PolyLM: An Open Source Polyglot Large Language Model
Large language models (LLMs) demonstrate remarkable ability to comprehend, reason, and generate following nature language instructions. However, the development of LLMs has been primarily focused on high-resource languages, such as English, thereby limitin
arxiv.org
'Paper Review' 카테고리의 다른 글
최근(2023.07)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
multilingual 능력 향상을 목표로 한 1.7B & 13B 사이즈 다국어 모델.
학습 데이터에 영어가 아닌 데이터의 비중을 크게 높이고,
multilingual self-instruct method를 적용한 것이 특징
- 배경
현재까지 많은 LLM들이 주목을 받았음에도 불구하고, 대부분의 모델들은 영어 데이터로 위주로 학습되었기 때문에 영어가 아닌 언어들에 대해서는 아쉬운 성능을 보여주고 있습니다.
보통 데이터셋을 구축할 때 고품질의 데이터를 인터넷으로부터 획득하는 경우가 대부분인데, 다른 언어들은 실사용자가 많다고 하더라도 인터넷에 대한 접근성이 떨어져 이러한 문제점이 생기는 것으로 분석됩니다.
본 논문에서는 이를 극복하기 위해 640B 토큰이나 되는 학습 데이터의 32% 정도를 영어가 아닌 데이터로 구성했습니다.
또한 self-instruct method를 개선하여 multilingual 상황에 특화시킴으로써 모델 성능을 극대화했다고 합니다.
- 특징
1) 데이터셋
위에서 언급했다시피 전체 데이터의 68%는 영어, 나머지 32%는 다른 언어로 구성되어 있습니다.
다른 LLM들이 일반적으로 갖는 학습 데이터의 비율과 비교해본다면 상당히 파격적이라고 볼 수 있습니다.
한국어 데이터도 전체의 0.13%를 차지하고 있는데 이도 다른 모델들에 비하면 상대적으로 많은 양입니다.
데이터를 수집할 때는 다음 기준으로 필터링했다고 합니다.
- Language identification : 무슨 언어의 데이터인지 확신할 수 없다면 필터링
- Rule-based filtering : 동일한 내용이 지나치게 많이 반복되는 경우 필터링
- ML-based quality filtering : n-gram based 언어 모델로 필터링
- Deduplication : 유사한 문서를 필터링
2) Pre-LN
transformer는 여러 layer로 구성되어 있고, 각 layer에 대해 normalization을 적용합니다.
특정 모델들은 layer에 입력을 제공하기 전에 normalization을 적용하는 Pre-LN 기법을 사용하는데, 본 모델도 이를 채택했습니다.
3) Mixed-Precision
bfloat16 자료형으로 학습하여 메모리를 절약하고 학습 효율을 높였습니다.
그러나 float32 자료형으로 학습할 때와 달리 loss spike가 발생한다는 문제점이 있었고, 이를 해결하기 위해 residual connection & attention layers는 float32 자료형을 사용했다고 합니다.
4) Curriculum Learning
모델의 입장에서 난이도가 낮은 것부터 학습하고 점차 난이도를 높이는 학습 방식을 말합니다.
본 연구에서는 영어가 아닌 데이터의 양을 학습이 반복됨에 따라 점차 늘리는 방식을 채택했습니다.
이때 사전학습에는 전체 데이터셋을 활용하여 commonsense generalization ability를 확보하고, 사전학습 데이터의 일부(subset)을 이용하여 multilingual contetn에 대해 강점을 갖도록 했습니다.
모델 성능 평가를 위한 실험 결과는 논문에 자세히 기술되어 있으니 논문에서 직접 확인해보시길 권장드립니다.
- 개인적 감상
ChatGPT로 인해 LLM이 크게 주목받기 시작한 이래로, 이러한 모델들이 과연 한국어도 잘 처리할 수 있을까에 대한 의문이 제기되고 있습니다.
아쉽게도 데이터가 부족하다는 이유로 한국어에 대해서는 모델들이 약한 모습을 보이고 있죠.
그래서 되게 재밌는 것이 언어 모델에게 한국어를 대량으로 학습시키는 것보다는, 영어로 학습되어 좋은 성능을 보이는 모델에게 한국어 데이터를 영어로 번역하는 방식이 많이 활용되고 있습니다.
이것이 단기적으로는 경제적이고 효용성이 높겠지만, 장기적으로는 해외 기술력에 종속되는 결과로 이어지게 될 것이라는 생각이 들어 이와 같은 연구가 의미 있다고 생각합니다.
한편으로는 재밌는 것이 한국어 데이터를 얼마나 학습했는지보다, 학습한 데이터의 총량이 얼마나 되는지나 모델의 학습 방식이 더욱 중요하다는 것입니다.
Eluther AI에서 최근에 대량의 한국어 데이터로 학습한 모델을 공개했는데 생각보다 성능이 별로라는 평이 많습니다.
오히려 한국어 데이터를 훨씬 조금 사용하여 학습한 해외 모델들이 우위를 점하고 있다는 사실이 굉장히 아이러니하죠.
따라서 여러 개의 언어를 동시에 학습하거나 한 언어에 특화된 학습을 하는 것이 강점을 가질 수 있고, 이를 활용하여 소수 언어에 대해서도 강점을 갖는 모델을 개발할 수 있다는 생각이 듭니다.
출처 : https://arxiv.org/abs/2307.06018
PolyLM: An Open Source Polyglot Large Language Model
Large language models (LLMs) demonstrate remarkable ability to comprehend, reason, and generate following nature language instructions. However, the development of LLMs has been primarily focused on high-resource languages, such as English, thereby limitin
arxiv.org