
최근(2023.07)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
전통적인 somftmax 기반의 attention 모델이 아닌 Linear Attention 기반의 LLM, TransNormerLLM. positional embedding, linear attention acceleration, gating mechanism, tensor normalization, inference acceleration 등의 방식을 적용.
linear attention을 가속화하는 Lightning Attention을 제시.
- 배경
대부분의 인공지능 모델들은 Transformer의 아키텍쳐를 기반으로 삼고 엄청난 속도로 발전해왔습니다.
이는 입력간 위치 정보들을 바탕으로 이전의 모델들에 비해 압도적인 성능을 보여주었고, 자연어처리 분야 뿐만 아니라 다양한 도메인에 활용되고 있습니다.
그러나 항상 지적되는 것은 시간 복잡도와 메모리의 문제입니다.
quadratic 연산이 요구되기 때문이죠.
그래서 모델의 크기를 키우고 싶어도 자원과 시간의 제약으로 인해 시도하기 어려운 경우들이 많았습니다.
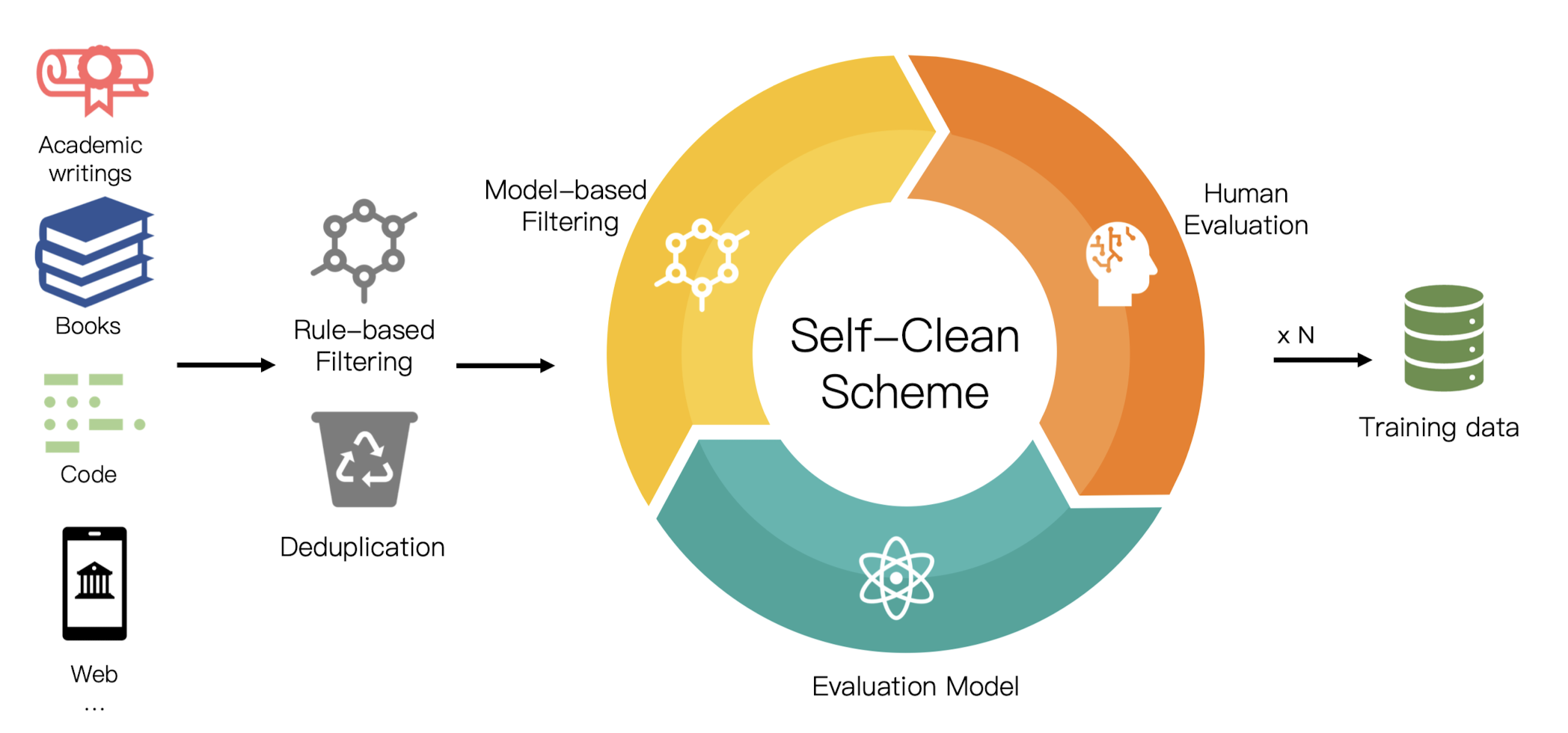
이러한 문제를 극복하기 위해 다양한 연구들이 이뤄졌고, 지금도 그러한 성과들이 제시되고 있는데요, 본 논문에서는 이전의 linear attention을 적용했던 TransNormer 모델을 LLM에 특화시킨 TransNormerLLM을 공개했습니다.
여기에는 위에 언급된 다양한 기법들 뿐만 아니라 6TB(2 trillion 토큰) 크기의 정제된 데이터도 활용되었다고 밝혔습니다.
- 특징
1) Position Encoding
이전 모델인 TranasNormer에서는 DiagAttention이 사용되었는데, 이것이 지닌 token interaction 상의 한계를 극복하기 위해 LRPE에 weight decay를 적용한 것을 이용했다고 합니다.
논문에서는 이를 LRPE-d 라고 표현합니다.
이 position encoding 방식은 Linear Attention과 온전히 양립 가능하다고 합니다.
2) Gating mechanism
활성화 함수로 ‘1 + elu’를 사용하는 Gated Linear Attention(GLA) 방식이 있습니다.
여기서 활성화 함수를 제외한 Simple GLU(SGLU)를 이용했다고 하는데, 활성화 함수를 제외한 방식을 이용해도 모델의 성능이 하락하지 않음을 검증했다고 밝히고 있습니다.
3) Tensor normalization
Transformer 아키텍쳐와 다르게 softmax와 scaling 연산을 제외합니다.
그리고 RMSNorm 대신에 simple normalization function을 사용한 SimpleRMSNorm을 사용했고 그 식은 다음과 같습니다.
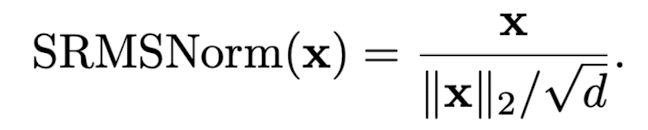
전체 아키텍쳐는 다음과 같습니다.
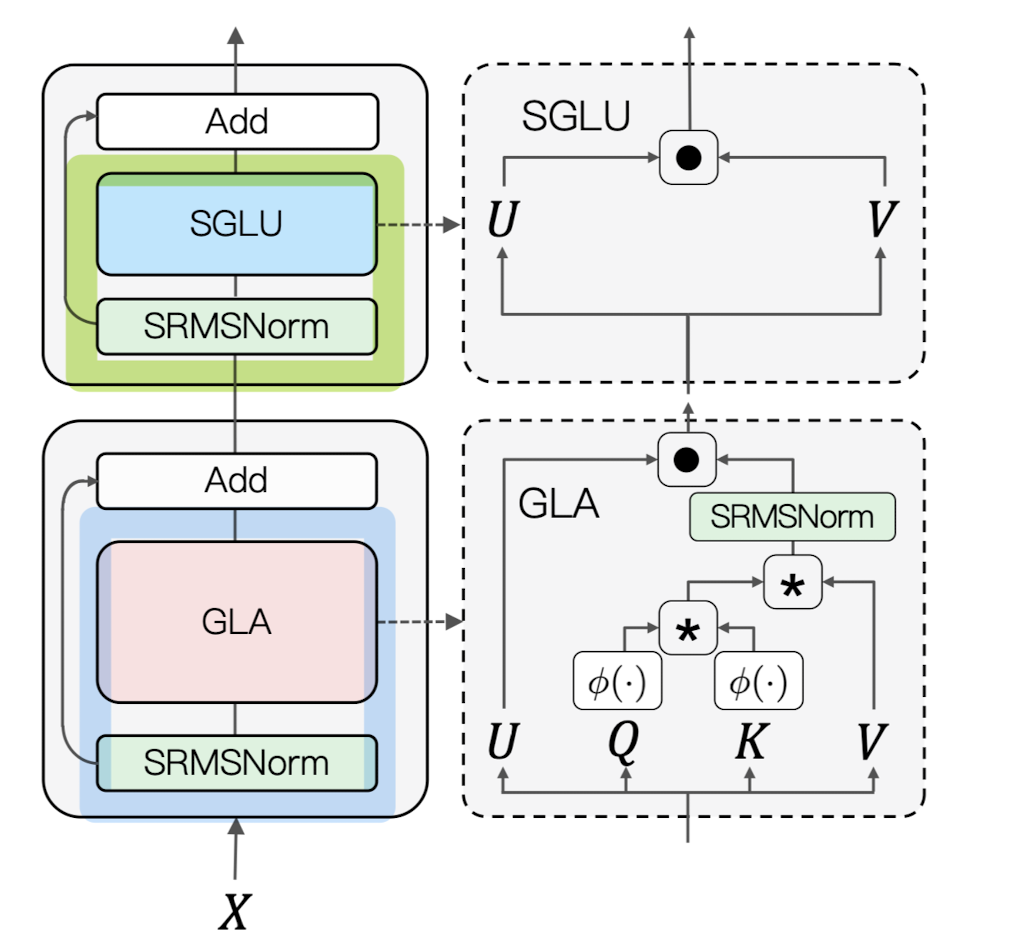
$X = X +GLA(SRMSNorm(X))$
$X = X + SGLU(SRMSNorm(X))$
이외에도 학습의 최적화를 위해 적용한 Lightning Attention 알고리즘과 병렬 처리를 위한 Fully Shareded Data Parrelel(FSDP), Automatic Mixed Precision(AMP) 등에 대한 설명이 기재되어 있습니다.
또한 수집된 대량의 데이터를 정제한 방식, Transformer 기반 모델과의 성능 비교, 각 기법들에 대한 ablation study 등의 결과가 포함되어 있으니 관심 있으신 분들은 논문을 직접 참고하시면 되겠습니다.
- 개인적 감상
이미 인공지능 분야 전체를 뒤덮은 transformer 아키텍쳐에서 벗어나 새로운 방식을 제안하고 이를 고도화했다는 점이 칭찬할만한 것 같습니다.
물론 논문 제목부터 transformer에 종속된 느낌이 들어 상당히 아이러니하긴 합니다만..
현재 인공지능 모델들이 가지는 한계점을 극복하고 모델을 고도화하기 위해서는 이런 식으로 아예 다른 아키텍쳐가 필요할지도 모른다는 막연한 생각이 듭니다.
하지만 성능 검증에 대해서는 상당히 아쉽다는 생각이 듭니다.
이론상 위와 같은 결과라면 이제 아무도 transformer 기반의 모델을 사용할 필요가 없기 때문입니다.
메모리도 덜 차지하는데, 속도도 빠르고, 성능도 준수하다면..?
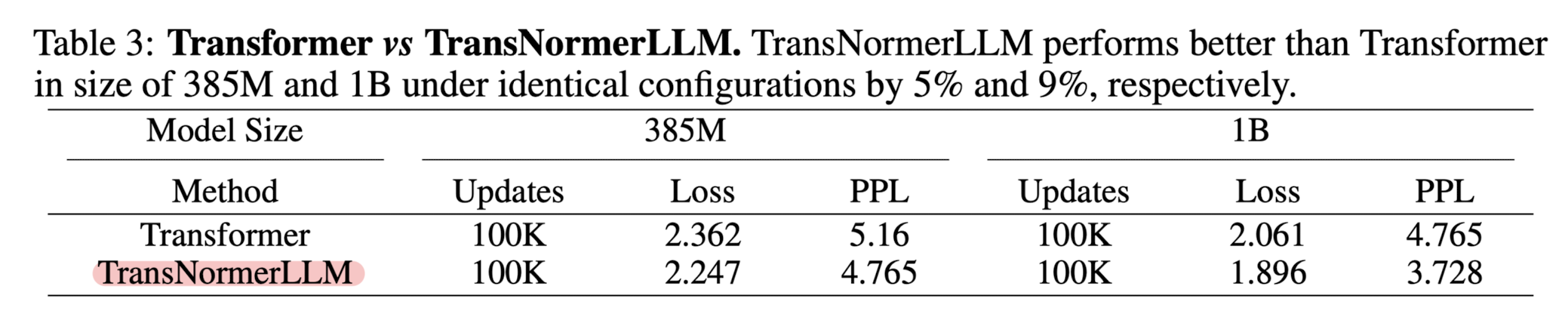
이러한 결과가 우연에 의한 것인지, 아니면 모델 사이즈가 너무 작기 때문에 LLM을 논하는 본 연구에 부적합한 것인지는 자세히 살펴보아야 알 수 있겠습니다만 상당히 편협한 검증을 거쳤을 것이라 짐작됩니다.
Scaling TransNormer to 175 Billion Parameters
We present TransNormerLLM, the first linear attention-based Large Language Model (LLM) that outperforms conventional softmax attention-based models in terms of both accuracy and efficiency. TransNormerLLM evolves from the previous linear attention architec
arxiv.org