
최근(2023.08)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Google Cloud AI Research]
demo가 아닌 documentation을 이용하여 zero shot만으로 적절한 tool을 사용할 수 있도록 함.
unseen tool에 대한 확장 가능성을 보여줌.
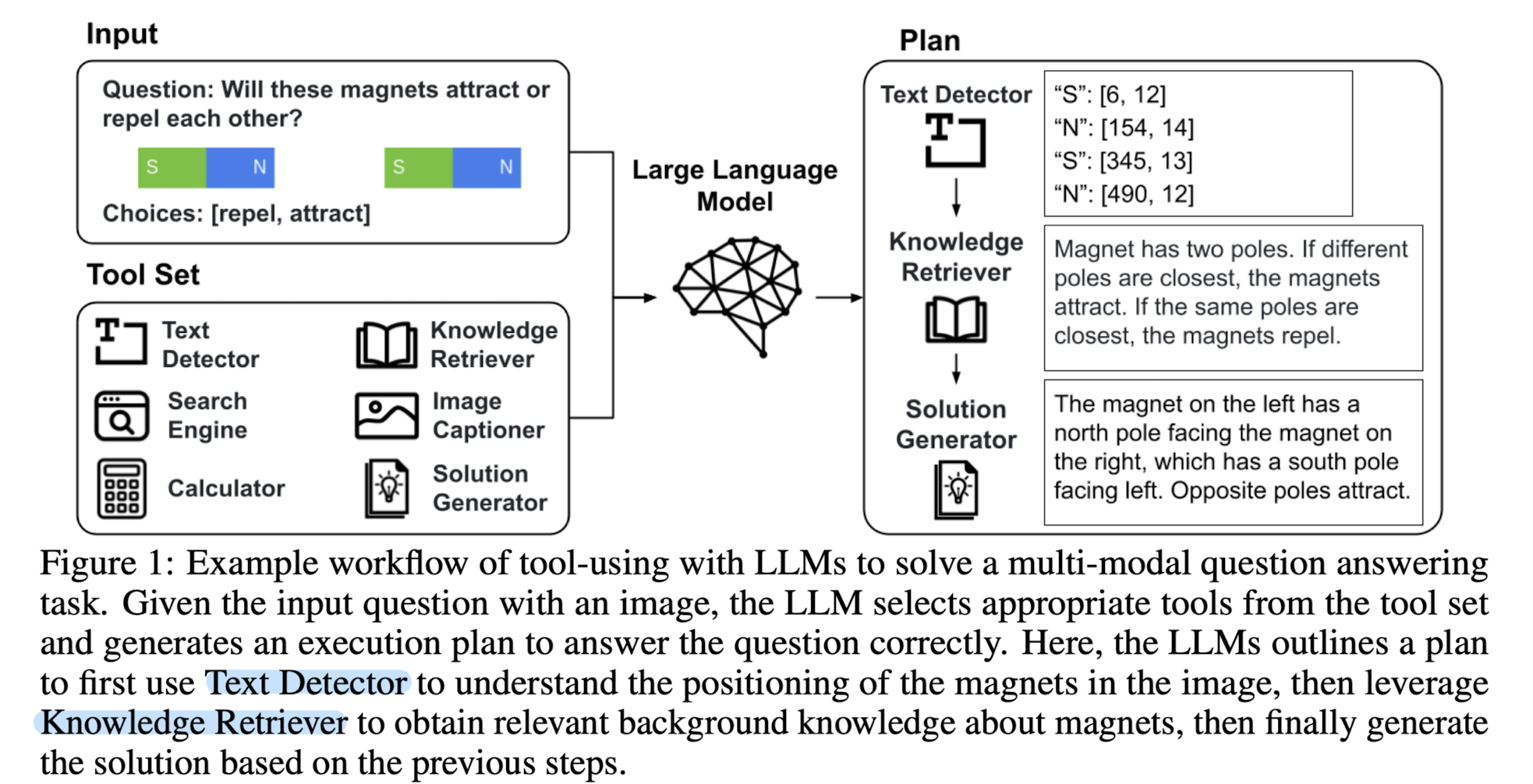
- 배경
LLM이 여러 태스크들에 대해 뛰어난 성능을 보이는 것은 사실이지만, 현실의 다양한 일들을 모두 잘하도록 만드는 것에는 분명히 한계가 있습니다.
특히 다른 modality를 다루는 모델을 개발하는 것은 더욱 어려운 일이구요.
그러다보니 최근에는 모델이 직접 어떤 태스크를 처리하는 것보다 다른 기술들을 활용하도록 하는 연구도 많이 이뤄지고 있습니다.
이는 주로 다른 인공지능 모델이나 구현된 API를 불러오는 방식으로 이뤄집니다.
그러나 이런 방식들 조차도 모델에게 여러 개의 예시를 항상 알려줘야 한다는 한계를 지니고 있었습니다.
심지어 이런 예시가 어떻게 구성되는지에 따라 모델 성능이 크게 영향을 받기 때문에, 적절한 예시를 만드는 작업의 난이도가 꽤 높습니다.
뿐만 아니라 이런 방식으로는 새로운 기술을 접목시키기 어렵습니다.
본 논문에서는 위처럼 모델에게 예시(few-shot)를 들어 적절한 도구 활용을 유도하는 demo 방식과 달리,
각 도구들의 특징을 종류별로 기술하고 상황에 적합한 것을 찾아 사용하도록 하는 documentation 방식을 연구했습니다.
- 특징
(1) demo vs doc

기존의 demo(nstration) 방식과 본 논문에서 사용하는 Doc(umentation)을 비교하는 예시입니다.
특정 질문에 대해 어떤 도구들을 사용해야 하는지에 대한 예시를 담은 전자와 달리, 후자는 각 도구들이 어떤 특징과 기능을 지니고 있는지에 대한 설명을 포함하고 있습니다.
(2) retrieval
매번 전체 doc을 모델의 입력으로 제공하게 되면, 길이의 제약으로 인해 모델이 좋은 성능을 발휘하지 못할 가능성이 높습니다.
따라서 doc 자체는 따로 저장해두고, TF-IDF 방식을 이용해 질문에 답변을 생성하기 적합한 것을 찾는 방식을 이용합니다.
(3) new benchmark: LLM Cloud CLI
Google Cloud Platform의 CLI(Command Line Interface)의 기능들을 나타내는 200여 개의 커맨드 모음집을 개발했다고 합니다.
이는 모델이 unseen tool들에 대하여 어떤 성능을 보이는지 파악하기 위한 지표입니다.
이전 방식(demo)은 특히 한 번 학습되었던 방식을 따라 hallucination을 만드는 경향을 보인 것이 한계로 지적되었기 때문에, 철저한 검증을 위한 벤치마크를 개발한 것으로 이해할 수 있습니다.
(4) no extra training
doc을 이용하는 방식을 적용할 때, 어떤 식으로든 추가 학습이 이뤄지지는 않았습니다.
즉 few-shot example을 만드는 수고로움은 덜되, 기존에 이르는, 혹은 그 이상의 성능을 발휘하는 메커니즘으로 전환하는데 doc을 생성하는 것 이외의 추가적인 cost가 들지 않는다고 볼 수 있습니다.
이와 같은 특징들을 지닌 doc 방식을 적용했을 때의 성능을 비교한 결과 예시는 다음과 같습니다.

세 개의 벤치마크에 대해 demo를 사용했을 때와 doc을 사용했을 때를 비교하고 있습니다.
이 결과를 통해서 doc 방식만을 사용하는 것만으로도 최고치 성능을 끌어낼 수 있음을 알 수 있습니다.
물론 demo를 곁들일 때 성능이 향상하는 경우도 있긴 하지만, 이를 위해 들여야하는 비용을 생각해보면 doc만을 사용하는 것이 훨씬 효율적인 방식으로 보입니다.

이 방식의 흥미로운 특징 중 하나는, 기존 도구들을 활용하여 새로운 방식을 ‘개발’하는 것이 가능하다는 점입니다.
즉 기존 도구들을 활용하여 태스크를 처리한 뒤, 이 방식을 저장해두고 다시 꺼내어 쓸 수 있다는 것이죠.
위 예시를 보면 첫 번째와 두 번째 query에 대해 처리한 방식이, ‘GroundingDINO’와 ‘SAM’ 방식을 결합한 것임을 알 수 있습니다.
이것이 시사하는 바는 앞으로도 등장할 여러 툴들과 태스크에 대해서도 이 방식이 적용 가능함, 즉 확장 가능성입니다.
- 개인적 감상
이와 같은 plug & play 방식과 관련된 논문들을 이전에도 읽은 적이 있는데, 그 방식에 대해 더욱 잘 이해할 수 있게 된 것 같습니다.
지금까지는 모델이 어떤 툴을 사용할지 정할 때 few shot example이 필요하다고도 생각하지 못했거든요..
물론 어떤 면에서는 API를 사용한다는 것 정도를 제외하면 HuggingGPT와 다른 것이 하나도 없는 듯한 느낌도 듭니다.
다른 딥러닝 모델들을 이용하여 추론 결과를 취합하는 HuggingGPT의 경우, 모델 카드나 데이터셋 카드에 나타난 정보를 활용하는 방식이라서 본 논문의 방식이 이를 거의 유사하게 따라간 것이 아닌가 싶었습니다.
이런 연구들을 볼 때마다 항상 드는 의문 중 하나는 '도대체 어떻게 다른 툴들을 이용할까'입니다.
API를 이용한다고 하더라도 각 사용 방식이 정해져 있고, 경우에 따라 설치를 해야 하는데 이를 모두 전제로 깔고 가는 것인지 궁금해지네요.
출처 : https://arxiv.org/abs/2308.00675
Tool Documentation Enables Zero-Shot Tool-Usage with Large Language Models
Today, large language models (LLMs) are taught to use new tools by providing a few demonstrations of the tool's usage. Unfortunately, demonstrations are hard to acquire, and can result in undesirable biased usage if the wrong demonstration is chosen. Even
arxiv.org